OK-VQA
收藏arXiv2019-09-04 更新2024-06-21 收录
下载链接:
http://okvqa.allenai.org
下载链接
链接失效反馈官方服务:
资源简介:
OK-VQA是一个专为视觉问答设计的知识基准数据集,由卡内基梅隆大学等机构创建。该数据集包含超过14,000个问题,这些问题不能仅通过图像内容回答,需要依赖外部知识资源。数据集涵盖多种知识类别,如科学、历史和体育,旨在评估模型在结合视觉识别与外部知识进行推理的能力。OK-VQA是迄今为止最大的专注于知识基础视觉问答的自然图像数据集,为研究者提供了新的研究途径。
OK-VQA is a knowledge-based benchmark dataset specifically designed for visual question answering (VQA), developed by institutions including Carnegie Mellon University. It contains over 14,000 questions that cannot be answered solely based on the content of the input image, and requires leveraging external knowledge resources. The dataset covers a wide range of knowledge categories such as science, history, and sports, aiming to evaluate the capability of models to perform reasoning by combining visual recognition and external knowledge. To date, OK-VQA is the largest natural image dataset focused on knowledge-based visual question answering, providing new research avenues for researchers.
提供机构:
卡内基梅隆大学
创建时间:
2019-06-01
搜集汇总
数据集介绍
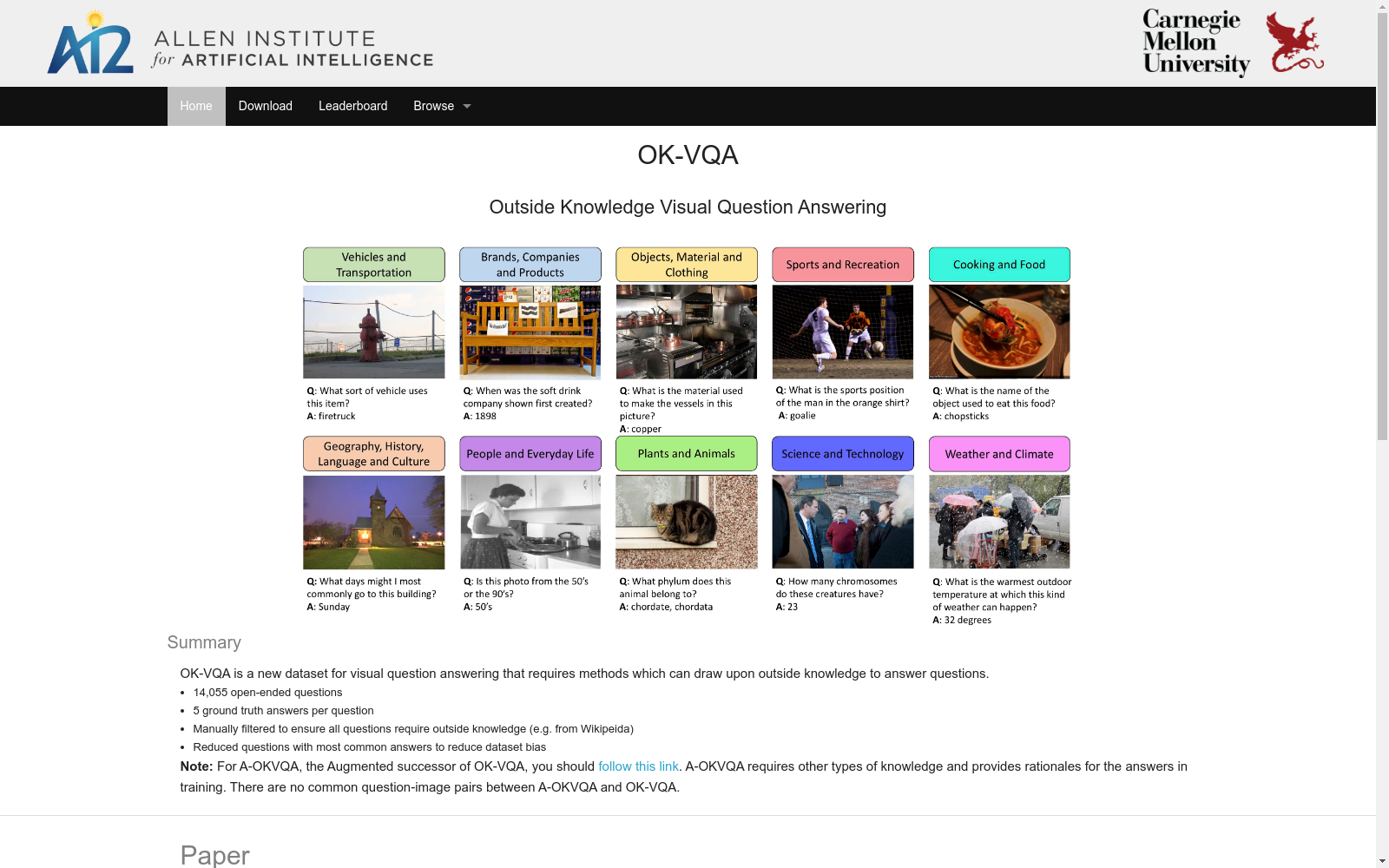
构建方式
OK-VQA数据集的构建基于开放域视觉问答任务,通过精心设计的问答对来实现。该数据集从多个公开的图像数据库中提取图像,并由领域专家和志愿者共同生成与图像内容相关的开放式问题。这些问题不仅涉及图像中的物体识别,还包括场景理解、情感分析等多维度信息。通过这种方式,OK-VQA确保了问题的多样性和复杂性,从而提升了数据集的实用性和挑战性。
使用方法
OK-VQA数据集主要用于训练和评估视觉问答系统。研究者可以通过该数据集训练模型,使其能够理解和回答与图像相关的开放式问题。使用时,首先需要加载数据集中的图像和对应的问题,然后利用这些数据进行模型的训练和验证。在评估阶段,可以通过比较模型生成的答案与数据集中的标准答案来衡量模型的性能。此外,OK-VQA还可以用于多模态学习研究,探索图像和文本之间的复杂关系。
背景与挑战
背景概述
视觉问答(Visual Question Answering, VQA)是计算机视觉与自然语言处理交叉领域的一个重要研究方向。OK-VQA数据集由Marques等人于2019年提出,旨在解决传统VQA数据集依赖于图像中显而易见信息的局限性。该数据集通过引入开放式问题,要求模型不仅理解图像内容,还需结合外部知识库进行推理,从而推动了VQA领域向更复杂、更具挑战性的任务发展。OK-VQA的提出,标志着VQA研究从简单的图像理解向更深层次的认知推理迈进,对提升人工智能系统的综合理解能力具有重要意义。
当前挑战
OK-VQA数据集的构建面临多重挑战。首先,数据集中的问题需要模型具备广泛的外部知识,这要求数据集设计者精心选择和标注问题,确保其涵盖多领域的知识。其次,模型的训练需要有效的知识融合机制,以整合图像信息与外部知识库的内容。此外,数据集的评估标准也需重新定义,以准确衡量模型在复杂推理任务中的表现。最后,数据集的规模和多样性也是一大挑战,确保训练数据能够覆盖足够广泛的知识领域,以提升模型的泛化能力。
发展历史
创建时间与更新
OK-VQA数据集由Agrawal等人于2019年创建,旨在通过结合开放域知识来增强视觉问答任务。该数据集在创建后经过多次更新,以确保其内容和质量的持续提升。
重要里程碑
OK-VQA数据集的一个重要里程碑是其首次引入开放域知识库,使得视觉问答任务不再局限于图像本身的信息,而是能够结合外部知识进行更深入的推理。这一创新极大地扩展了视觉问答的应用场景,并为后续研究提供了新的方向。此外,OK-VQA还通过引入多模态数据融合技术,进一步提升了问答系统的准确性和鲁棒性。
当前发展情况
当前,OK-VQA数据集已成为视觉问答领域的重要基准之一,广泛应用于多模态学习和知识图谱的研究中。其对相关领域的贡献主要体现在推动了视觉问答技术从单一图像信息向多源知识融合的转变,促进了跨学科研究的深入发展。随着技术的不断进步,OK-VQA数据集也在持续更新和优化,以适应日益复杂的应用需求,并为未来的智能系统提供更为丰富的数据支持。
发展历程
- OK-VQA数据集首次发表,由阿里达摩院和新加坡国立大学联合提出,旨在通过开放域知识增强视觉问答任务。
- OK-VQA数据集首次应用于视觉问答模型的评估,推动了多模态学习领域的发展。
- OK-VQA数据集被广泛用于研究多模态融合技术,特别是在结合图像和文本信息进行复杂推理方面。
- OK-VQA数据集成为视觉问答领域的重要基准,促进了相关算法的创新和性能提升。
常用场景
经典使用场景
在视觉问答(Visual Question Answering, VQA)领域,OK-VQA数据集以其独特的多模态特性成为研究热点。该数据集要求模型不仅理解图像内容,还需结合外部知识库回答问题,从而模拟人类在复杂情境下的决策过程。经典使用场景包括:模型通过分析图像中的视觉元素,并检索相关文本信息,最终生成准确答案。这种多模态融合的方法,显著提升了VQA系统的性能和鲁棒性。
解决学术问题
OK-VQA数据集解决了传统VQA数据集依赖图像内部信息不足的问题,特别是在需要外部知识辅助的复杂问答场景中。通过引入外部知识库,该数据集促使研究者开发更智能、更全面的视觉问答模型。这不仅推动了多模态学习的研究进展,还为理解人类认知过程提供了新的视角。OK-VQA的意义在于,它为构建能够处理复杂、开放性问题的AI系统奠定了基础。
实际应用
在实际应用中,OK-VQA数据集的模型可以广泛应用于教育、医疗和智能助手等领域。例如,在教育领域,系统可以通过分析教材图像并结合外部知识,为学生提供更深入的解释和扩展学习资源。在医疗领域,系统可以帮助医生快速获取和理解复杂的医学图像信息,从而提高诊断效率。智能助手则可以通过多模态理解,提供更精准、个性化的服务。
数据集最近研究
最新研究方向
在视觉问答(VQA)领域,OK-VQA数据集因其对开放域知识的依赖而备受关注。最新研究方向主要集中在提升模型对复杂问题的理解和推理能力,特别是在多模态数据融合方面。研究者们通过引入更丰富的知识图谱和跨模态注意力机制,以增强模型对图像内容和外部知识的综合利用。此外,针对OK-VQA的评估标准也在不断完善,旨在更准确地衡量模型的知识推理和语言理解能力。这些进展不仅推动了VQA技术的发展,也为智能问答系统在实际应用中的表现提供了新的可能性。
相关研究论文
- 1OK-VQA: A Visual Question Answering Benchmark Requiring External KnowledgeUniversity of North Carolina at Chapel Hill, University of Michigan, University of Washington · 2019年
- 2OK-VQA: A Benchmark for Open-Knowledge Visual Question AnsweringUniversity of North Carolina at Chapel Hill, University of Michigan, University of Washington · 2020年
- 3Exploring the Limits of Transfer Learning with a Unified Text-to-Text TransformerGoogle Research, Carnegie Mellon University · 2020年
- 4LXMERT: Learning Cross-Modality Encoder Representations from TransformersUniversity of North Carolina at Chapel Hill, University of Washington · 2019年
- 5GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question AnsweringUniversity of California, Berkeley, University of Toronto · 2019年
以上内容由遇见数据集搜集并总结生成


