liupf/ChEBI-20-MM
收藏Hugging Face2024-06-17 更新2024-03-04 收录
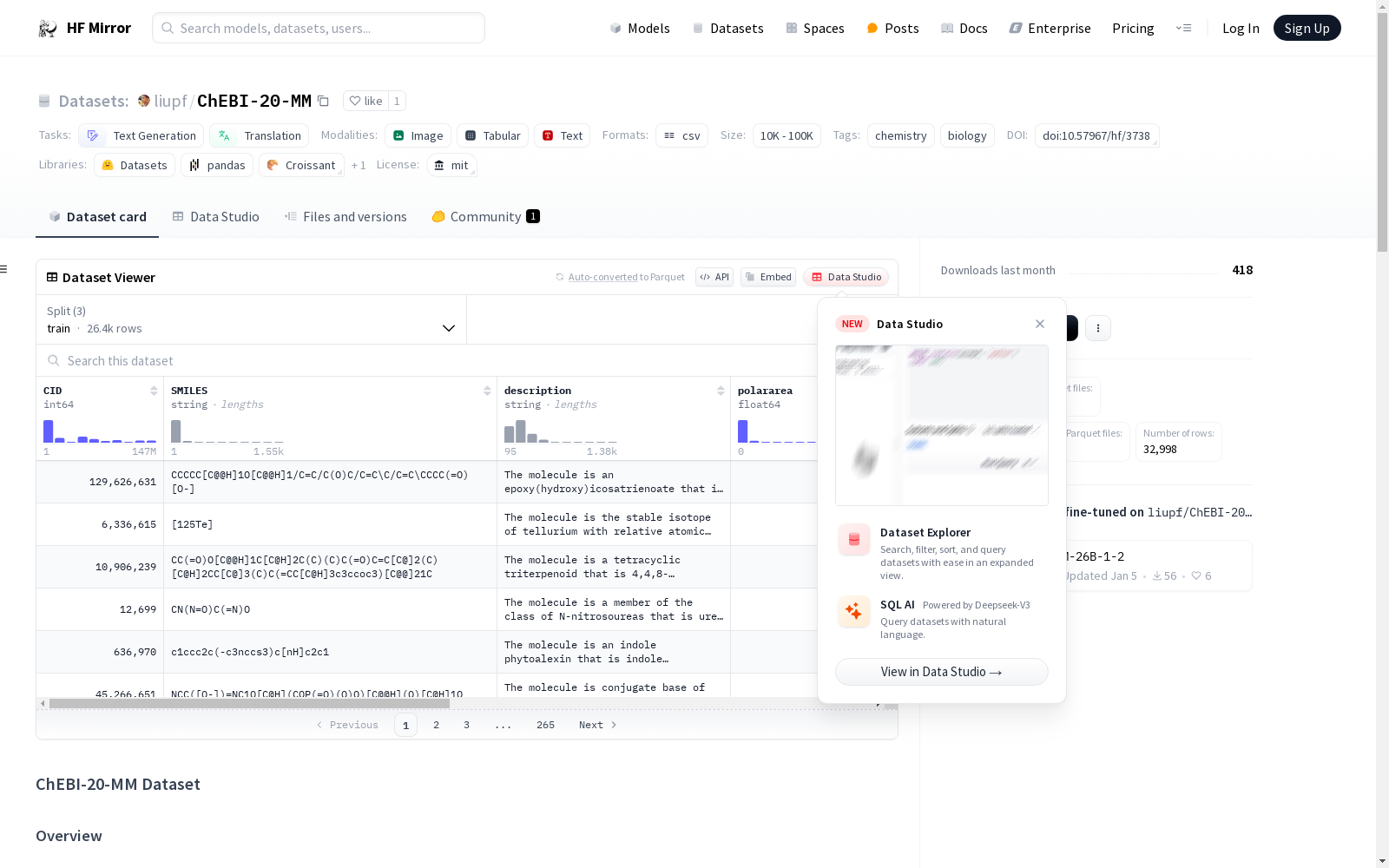
下载链接:
https://hf-mirror.com/datasets/liupf/ChEBI-20-MM
下载链接
链接失效反馈官方服务:
资源简介:
ChEBI-20-MM数据集是一个扩展自ChEBI-20数据集的多模态基准数据集,专注于分子科学领域。该数据集整合了多种分子数据模态,包括InChI、IUPAC、SELFIES和图像,旨在评估模型在分子生成、图像识别、IUPAC识别、分子描述和检索任务中的能力。通过增加数据模态的多样性,该数据集能够更全面地评估模型在多模态数据处理中的性能。
The ChEBI-20-MM dataset is a multimodal benchmark dataset extended from the ChEBI-20 dataset, focusing on the field of molecular science. It integrates various molecular data modalities including InChI, IUPAC, SELFIES and molecular images, aiming to evaluate the performance of models across tasks such as molecular generation, image recognition, IUPAC recognition, molecular description and retrieval. By increasing the diversity of data modalities, this dataset enables a more comprehensive assessment of model performance in multimodal data processing.
提供机构:
liupf
原始信息汇总
ChEBI-20-MM 数据集
概述
ChEBI-20-MM 是一个从 ChEBI-20 数据集发展而来的广泛且多模态的基准测试。它旨在为分子科学领域的各种模型的能力提供全面的基准测试。该基准集成了多模态数据,包括 InChI、IUPAC、SELFIES 和图像,使其成为广泛分子任务的多功能工具。
数据集描述
ChEBI-20-MM 是原始 ChEBI-20 数据集的扩展,重点在于整合多种分子数据模态。该基准旨在评估模型在以下关键领域的能力:
- 分子生成:评估模型生成准确分子结构的能力。
- 图像识别:测试模型在将分子图像转换为其他表示格式方面的熟练程度。
- IUPAC 识别:评估模型从其他表示格式生成 IUPAC 名称的能力。
- 分子描述:评估模型生成分子结构描述性描述的能力。
- 检索任务:衡量模型在准确高效地检索分子信息方面的有效性。
实用性和重要性
通过扩展数据模态的多样性,该基准能够更全面地评估模型在多模态数据处理方面的性能。
数据可视化
我们采用可视化技术来分析数据源对语言模型的适用性和化学空间覆盖范围。下图展示我们使用不同的可视化方法来分析由每个模型的分词器生成的文本长度分布和标记计数,这些方法评估了语言模型对我们数据集文本特征的适应性。

我们还关注数据集中前10个支架,统计每个支架的分子数量。在这里,半透明条表示总数,而实心条表示训练集中的数量。另一方面,对于化学空间覆盖范围的分析,我们选择分子量(MW)、LogP、芳香环数量和拓扑极性表面积(TPSA)作为描述符。我们检查这些描述符在数据集中的分布和相关性,提供对我们数据中化学多样性和复杂性的见解。
搜集汇总
数据集介绍
构建方式
ChEBI-20-MM数据集是在ChEBI-20基础上的扩展,它通过融合InChI、IUPAC、SELFIES等多种分子表示形式以及图像数据,构建了一个多模态的分子科学评价基准。该数据集的构建旨在全面评估模型在不同分子任务中的性能,包括分子生成、图像识别、IUPAC名称识别、分子描述生成以及检索任务等。
特点
该数据集的特点在于其多模态数据的整合,不仅包含了文本信息,还纳入了分子图像,从而为模型提供了更加丰富的训练和评估资源。通过这种数据模态的多样性扩展,ChEBI-20-MM能够更加全面地评价模型在处理多模态数据时的表现,这对于分子科学领域的研究具有重要意义。
使用方法
用户可以通过SLM4Mol链接直接访问与该数据集相关的模型评估和评价。此外,数据集还提供了可视化工具,帮助用户分析数据源的适用性以及化学空间的覆盖范围,从而更好地理解数据集的特性和模型的适应能力。
背景与挑战
背景概述
ChEBI-20-MM数据集是在分子科学领域内,为了全面评估模型在多模态数据处理能力而开发的综合性和多模态基准。该数据集基于原有的ChEBI-20数据集扩展而来,汇集了InChI、IUPAC、SELFIES以及图像等多种分子数据模态。ChEBI-20-MM数据集的创建,旨在分子生成、图像识别、IUPAC名称识别、分子描述生成以及检索任务等多个关键领域对模型进行评估。此数据集的发展受到了MolT5在分子生成和描述生成方面工作的启发,并借鉴了PubChem的额外数据信息补充,自推出以来,为分子科学领域的研究提供了重要的资源和工具。
当前挑战
在构建ChEBI-20-MM数据集的过程中,研究者们面临的挑战包括如何有效地整合和表示多种分子数据模态,以及如何确保模型在处理这些多模态数据时的准确性和效率。在所解决的领域问题方面,该数据集对模型的分子生成准确性、图像识别能力、IUPAC名称生成能力以及分子描述生成能力提出了挑战。同时,构建过程中的挑战还涉及到数据源的适用性分析以及化学空间覆盖度的评估,这些都对研究团队提出了较高的技术要求和研究难度。
常用场景
经典使用场景
在分子科学领域中,ChEBI-20-MM数据集以其多元化的分子数据模态,成为评估模型在多模态数据处理能力上的重要基准。其经典使用场景在于对分子生成、图像识别、IUPAC名称识别、分子标注以及检索任务等方面的模型性能进行深入评估,旨在推动分子科学计算模型的发展。
衍生相关工作
基于ChEBI-20-MM数据集的研究已经衍生出一系列相关工作,包括但不限于分子生成模型的优化、多模态数据融合技术的研究以及分子信息检索算法的改进,这些工作进一步扩展了分子科学在计算生物学和药物设计领域的应用边界。
数据集最近研究
最新研究方向
ChEBI-20-MM数据集作为分子科学的综合评价工具,其多模态特性为当前研究提供了新的研究方向。该数据集通过融入InChI、IUPAC、SELFIES及图像等多种分子数据格式,旨在评估模型在分子生成、图像识别、IUPAC识别、分子标注以及检索任务等方面的性能。目前,该领域的前沿研究正聚焦于如何提高模型在多模态数据处理能力上的准确性和效率,进而推动分子科学的发展。ChEBI-20-MM数据集的构建不仅丰富了分子数据的研究维度,也为评估模型在化学空间覆盖度上的表现提供了有力支持,对于促进分子生成模型和语言模型在生物化学领域的应用具有重要意义。
以上内容由遇见数据集搜集并总结生成


