HoneyBee
收藏arXiv2024-05-13 更新2024-06-21 收录
下载链接:
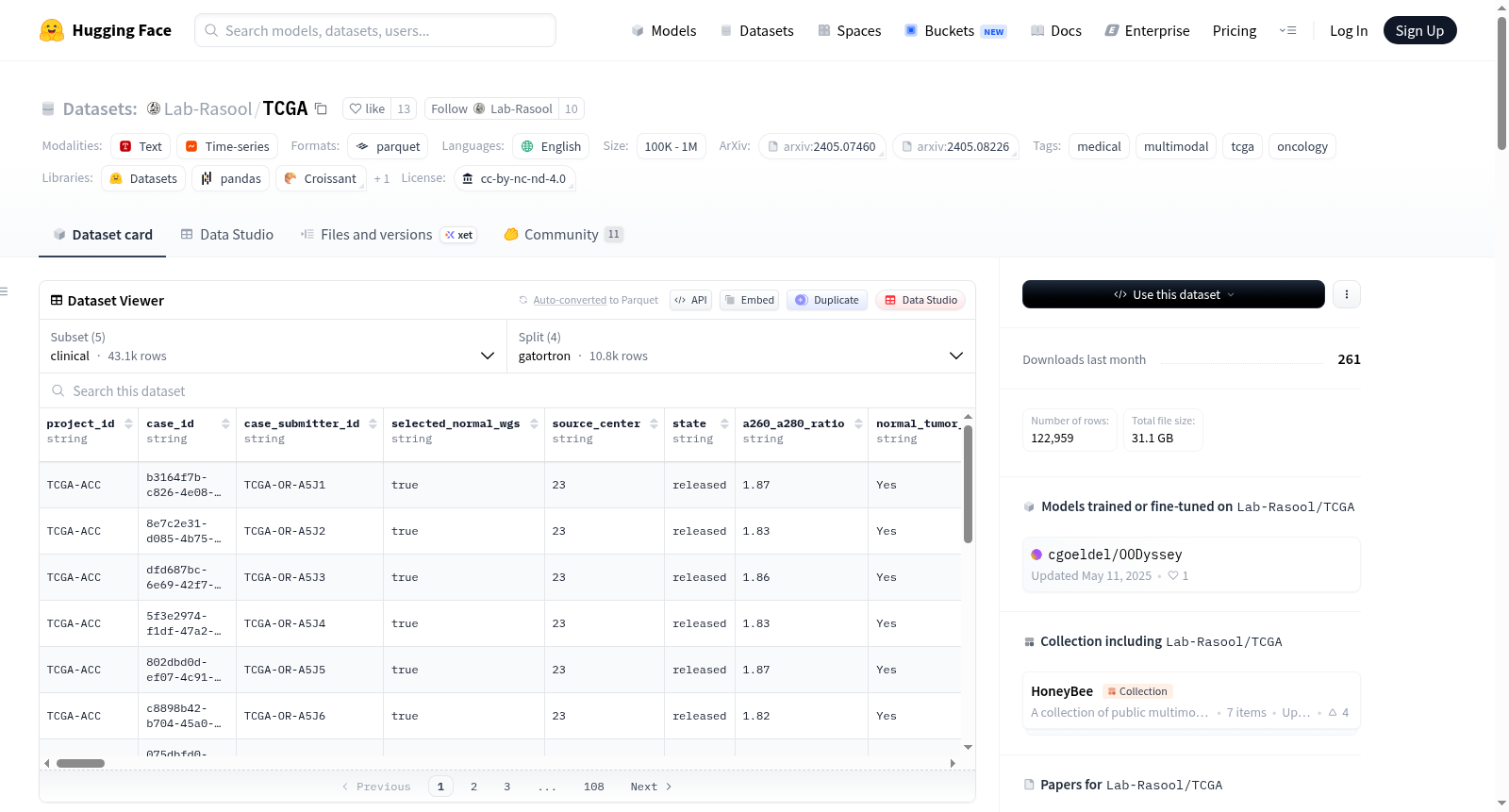
https://huggingface.co/datasets/Lab-Rasool/TCGA
下载链接
链接失效反馈官方服务:
资源简介:
HoneyBee是一个用于创建多模态肿瘤学数据集的可扩展模块化框架,由莫菲特癌症中心开发。该数据集整合了临床记录、影像数据和患者结果等多种数据模态,通过基础模型生成代表性嵌入。数据集大小庞大,包含来自TCGA项目的11,428名患者的数据,涵盖33种癌症类型。创建过程中,利用了先进的数据预处理技术和基于变压器的架构来生成嵌入,捕捉原始医疗数据中的基本特征和关系。HoneyBee旨在通过提供高质量、机器学习就绪的数据集,加速肿瘤学研究,解决医疗数据复杂性和异质性的挑战,并可扩展到其他医疗领域。
HoneyBee is a scalable, modular framework for creating multimodal oncology datasets, developed by the Moffitt Cancer Center. This dataset integrates multiple data modalities including clinical records, imaging data, and patient outcomes, and generates representative embeddings via foundation models. Boasting a large scale, the dataset contains data from 11,428 patients in the TCGA project, covering 33 cancer types. During its development, advanced data preprocessing techniques and Transformer-based architectures are employed to generate embeddings that capture the fundamental features and relationships within raw medical data. HoneyBee aims to accelerate oncology research by providing high-quality, machine learning-ready datasets, address the challenges of complexity and heterogeneity in medical data, and be scalable to other healthcare domains.
提供机构:
莫菲特癌症中心
创建时间:
2024-05-13
搜集汇总
数据集介绍
构建方式
在视觉语言推理领域,构建高质量数据集是提升模型性能的关键。HoneyBee数据集的构建采用了系统化的数据策展流程,首先从多个现有视觉语言推理数据集中筛选出高质量的图像-问题对作为上下文来源,并通过实验验证了ViRL数据集在提升模型性能方面的优越性。随后,研究团队引入了多种数据干预策略,包括增强感知能力的“描述并解决”方法,该方法通过为图像生成详细描述并将其融入推理链中,显著提升了模型对视觉内容的理解深度。同时,通过融合纯文本推理数据,进一步强化了模型的跨模态问题解决能力。最终,通过在多维度上扩展数据规模——包括增加独特图像数量、为每张图像生成多个问题以及为每个图像-问题对合成多条推理链,构建了包含250万样本的大规模高质量链式思维推理数据集。
特点
HoneyBee数据集在视觉语言推理领域展现出若干突出特点。其规模宏大,涵盖250万个样本,包含28万张独特图像和35万个独特问题,为模型训练提供了丰富的多样性。数据质量经过精心优化,通过严格的上下文筛选和干预策略,确保了样本的高效性和教育价值。数据集中每条推理链平均长度约600词,不仅包含逐步解题过程,还融入了图像描述、规划、反思等复杂推理行为,能够有效引导模型进行深度思考。此外,数据集的设计支持高效的测试时扩展,通过共享图像描述机制,能在生成多个解决方案时显著减少计算开销,提升推理效率。这些特点共同使得基于HoneyBee训练的模型在多项视觉数学推理基准测试中取得了领先性能。
使用方法
HoneyBee数据集主要用于训练视觉语言模型进行链式思维推理。研究人员可采用监督微调方法,以图像和问题作为输入,训练模型生成包含图像描述和解题步骤的完整推理链。在训练过程中,建议使用完整的250万样本集,因为实验表明模型性能随数据规模增加而持续提升,即使在此规模下仍未达到饱和。对于资源有限的研究,也可使用其子集进行实验,但需注意数据规模与模型性能的正相关关系。训练后的模型可直接应用于多种视觉推理任务,如数学问题求解、图表分析和逻辑推理等。此外,该数据集还支持测试时扩展技术,通过生成多个推理链并采用多数投票机制提升预测可靠性,同时利用其内置的图像描述共享机制可大幅降低计算成本。对于进阶研究,该数据集还可作为强化学习的优质起点,进一步优化模型的推理能力。
背景与挑战
背景概述
HoneyBee数据集由Meta FAIR与加州大学洛杉矶分校的研究团队于2025年10月联合发布,旨在系统探索视觉-语言推理模型的高效训练数据构建原则。该数据集聚焦于解决多模态推理中的核心科学问题,即如何通过精心设计的链式思维数据提升模型在复杂视觉语境下的数学与逻辑推理能力。研究团队通过控制变量实验,深入分析了上下文来源、数据干预策略及多维度扩展对模型性能的影响,最终构建了包含250万实例的大规模高质量CoT数据集。HoneyBee的推出为视觉-语言推理领域提供了可复现的数据构建范式,显著推动了开源模型在MathVista、MathVerse等权威基准上的性能边界。
当前挑战
HoneyBee数据集致力于解决视觉-语言推理任务中模型需融合图像与文本信息进行复杂推理的挑战,其构建过程面临多重困难。在领域层面,多模态推理要求模型同时具备深度的视觉理解与符号推理能力,而现有数据往往存在感知冗余或逻辑浅层化问题。在构建过程中,研究团队需系统评估不同上下文来源的效能差异,例如图像-问题对的原始质量对最终推理性能的影响高达4%的准确率波动。此外,数据干预策略如视觉扰动、文本增强等多数未能稳定提升性能,仅图像描述增强与纯文本推理数据融合被验证为有效手段。数据扩展时还需平衡图像、问题及CoT数量等多维度缩放,确保规模增长伴随质量提升。
常用场景
经典使用场景
在视觉语言推理领域,HoneyBee数据集被广泛应用于训练和评估多模态推理模型。该数据集通过精心设计的思维链数据,为模型提供了丰富的图像-问题-推理三元组,使其能够在几何、函数、图表等复杂视觉场景中进行逐步推理。典型应用包括在MathVista、MathVerse等基准测试上对模型进行微调,以提升其在数学视觉问题解答中的准确性和鲁棒性。
实际应用
该数据集的实际应用场景涵盖教育辅助、科学数据分析和智能决策支持系统。在教育领域,基于HoneyBee训练的模型能够解析教科书中的几何图示和函数图像,为学生提供步骤化解题指导。在科研场景中,模型可协助研究人员从视觉化数据中提取量化信息,加速科学发现进程。其高效解码策略还能在保持精度的同时大幅降低计算成本。
衍生相关工作
HoneyBee数据集催生了多项重要研究工作,包括基于共享字幕的高效测试时扩展方法、视觉语言模型的强化学习微调框架OpenVLThinker,以及跨模态知识迁移的文本-视觉混合训练范式。这些衍生工作进一步拓展了多模态推理的研究边界,为构建更高效、更通用的视觉语言智能体奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


