有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
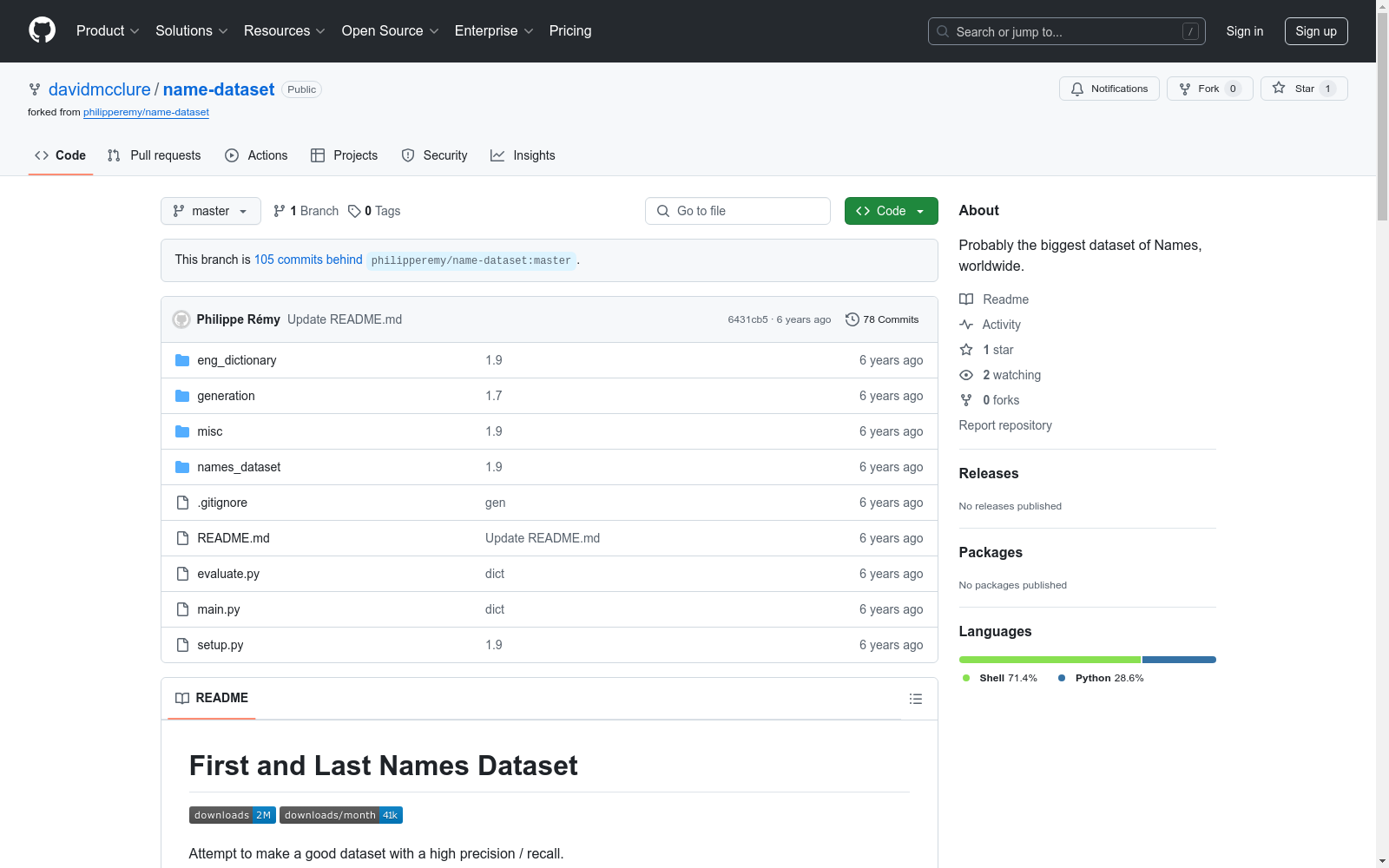
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
bash pip install names-dataset
python from names_dataset import NameDataset m = NameDataset() m.search_first_name(Mikael) m.search_last_name(Remy)
13_Gitovu.rar
:unav
DataCite Commons 收录
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
ClinicalTrials.gov
Provides patients, family members, health care professionals, and members of the public easy access to information on clinical trials for a wide range of diseases and conditions.
OPEN DATA NETWORK 收录
FishBase Species List
FishBase Species List 是一个包含全球鱼类物种信息的全面数据库。该数据集提供了关于鱼类物种的详细信息,包括物种名称、分类学信息、分布区域、生态习性、繁殖行为、食性等。此外,数据集还包括了每个物种的图片和参考文献,以便用户进行深入研究。
www.fishbase.se 收录