eto-sft-trajectory
收藏魔搭社区2025-08-15 更新2025-05-31 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/eto-sft-trajectory
下载链接
链接失效反馈官方服务:
资源简介:
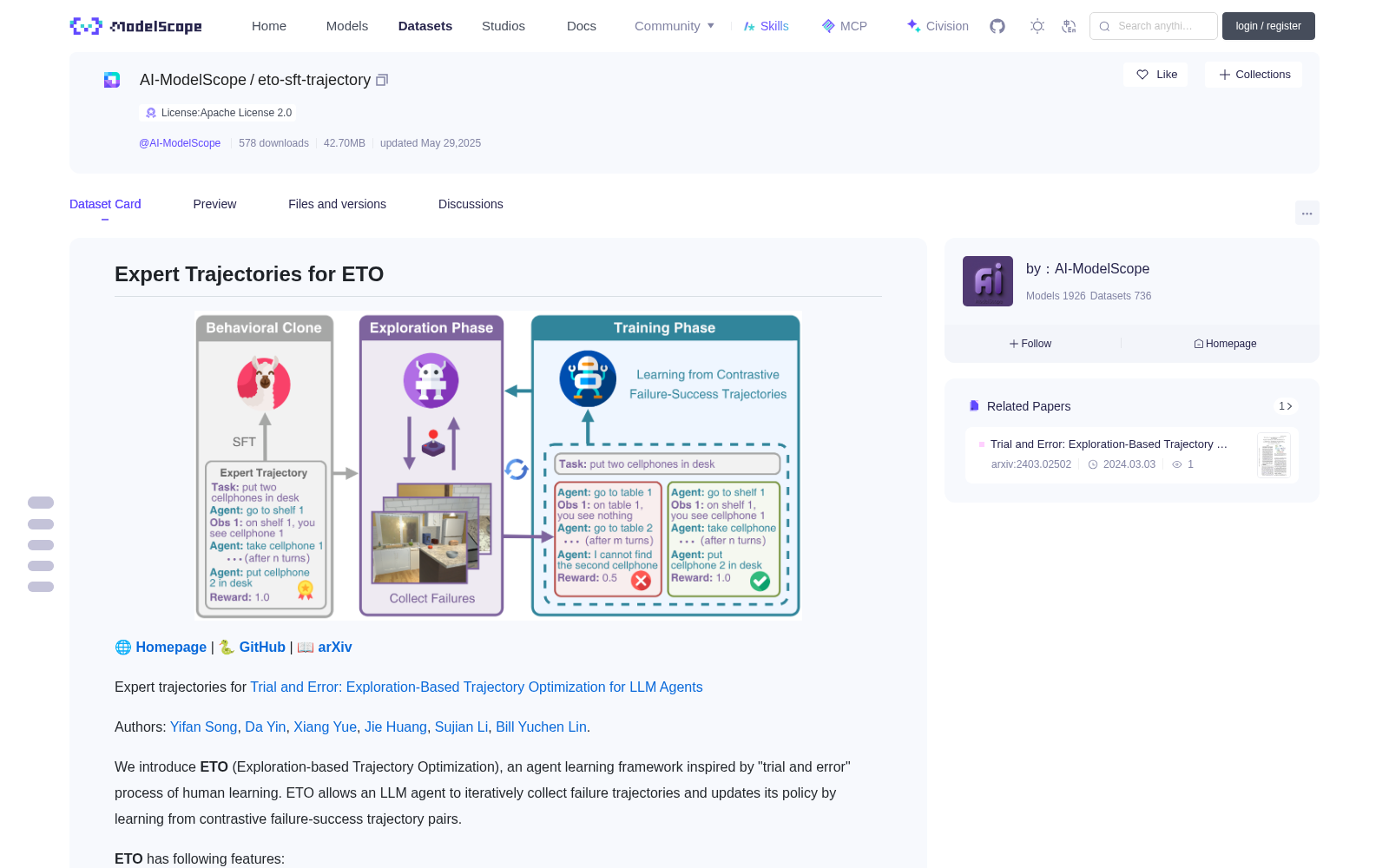
# Expert Trajectories for ETO
[**🌐 Homepage**](https://huggingface.co/spaces/agent-eto/Agent-ETO) | [**🐍 GitHub**](https://github.com/Yifan-Song793/ETO) | [**📖 arXiv**](https://arxiv.org/abs/2403.02502)
Expert trajectories for [Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents](https://arxiv.org/abs/2403.02502)
Authors: [Yifan Song](https://github.com/Yifan-Song793), [Da Yin](https://wadeyin9712.github.io/), [Xiang Yue](https://xiangyue9607.github.io/), [Jie Huang](https://jeffhj.github.io/), [Sujian Li](http://123.56.88.210/), [Bill Yuchen Lin](https://yuchenlin.xyz/).
We introduce **ETO** (Exploration-based Trajectory Optimization), an agent learning framework inspired by "trial and error" process of human learning.
ETO allows an LLM agent to iteratively collect failure trajectories and updates its policy by learning from contrastive failure-success trajectory pairs.
**ETO** has following features:
- 🕹️ **Learning by Trial and Error**
- 🎲 **Learning from Failure Trajectories.** Contrary to previous approaches that exclusively train on successful expert trajectories, ETO allows agents to learn from their exploration failures.
- 🎭 **Contrastive Trajectory Optimization.** ETO applies DPO loss to perform policy learning from failure-success trajectory pairs.
- 🌏 **Iterative Policy Learning.** ETO can be expanded to multiple rounds for further policy enhancement.
- 🎖️ **Superior Performance**
- ⚔️ **Effectiveness on Three Datasets.** ETO significantly outperforms strong baselines, such as RFT, PPO, on [WebShop](https://webshop-pnlp.github.io/), [ScienceWorld](https://sciworld.apps.allenai.org/), and [ALFWorld](https://alfworld.github.io/).
- 🦾 **Generalization on Unseen Scenarios.** ETO demonstrates an impressive performance improvement of 22% over SFT on the challenging out-of-distribution test set in ScienceWorld.
- ⌛ **Task-Solving Efficiency.** ETO achieves higher rewards within fewer action steps on ScienceWorld.
- 💡 **Potential in Extreme Scenarios.** ETO shows better performance in self-play scenarios where expert trajectories are not available.
## Expert Trajectories
This dataset contains expert trajectories for three agent environments:
- **WebShop**: We preprocess the official [human demonstrations](https://github.com/princeton-nlp/WebShop/issues/21) provided by authors of WebShop. We also employ GPT-4 to explore in the environment and select trajectories with rewards greater than 0.7.
- **ScienceWorld**: The environment provides heuristic algorithm to generate golden trajectories.
- **ALFWorld**: The authors provide a few human-annotated trajectories for imitation learning.
Since the original trajectories do not contain CoT information for each action step, we utilize GPT-4 to generate the corresponding rationales.
## 🛠️ Setup & Evaluation
Please see our [GitHub Repo](https://github.com/Yifan-Song793/ETO).
## 📑 The Data Format for Training the Agent
```json
[
{
"id": "example_0",
"conversations": [
{
"from": "human",
"value": "Who are you?"
},
{
"from": "gpt",
"value": "I am Vicuna, a language model trained by researchers from Large Model Systems Organization (LMSYS)."
},
{
"from": "human",
"value": "Have a nice day!"
},
{
"from": "gpt",
"value": "You too!"
}
]
}
]
```
## 📖 Citation
If you find this dataset helpful, please cite out paper:
```
@article{song2024trial,
author={Yifan Song and Da Yin and Xiang Yue and Jie Huang and Sujian Li and Bill Yuchen Lin},
title={Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents},
year={2024},
eprint={2403.02502},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# 面向ETO的专家轨迹数据集
[🌐 主页](https://huggingface.co/spaces/agent-eto/Agent-ETO) | [🐍 GitHub仓库](https://github.com/Yifan-Song793/ETO) | [📖 arXiv论文](https://arxiv.org/abs/2403.02502)
本数据集为论文《Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents》配套的专家轨迹数据集。
作者:宋一凡(Yifan Song)、尹达(Da Yin)、岳翔(Xiang Yue)、黄杰(Jie Huang)、李素建(Sujian Li)、林昱辰(Bill Yuchen Lin)。
我们提出了**ETO(Exploration-based Trajectory Optimization,基于探索的轨迹优化)**,这是一个受人类学习“试错”过程启发的智能体学习框架。ETO允许大语言模型(Large Language Model,LLM)智能体迭代收集失败轨迹,并通过对比失败-成功轨迹对进行学习以更新其策略。
**ETO** 具备以下特性:
- 🎮 **试错学习**
- 🎲 **从失败轨迹中学习**。与以往仅在成功专家轨迹上进行训练的方法不同,ETO允许智能体从自身的探索失败中学习。
- 🎭 **对比轨迹优化**。ETO采用DPO损失函数,通过失败-成功轨迹对完成策略学习。
- 🌏 **迭代策略学习**。ETO可扩展至多轮迭代以进一步优化策略。
- 🎖️ **优异性能表现**
- ⚔️ **三大数据集上的有效性**。ETO在WebShop、ScienceWorld与ALFWorld三大环境上均显著优于RFT、PPO等顶尖基线模型。
- 🦾 **未知场景泛化能力**。在ScienceWorld的挑战性分布外测试集上,ETO相较于监督微调(Supervised Fine-Tuning,SFT)性能提升高达22%,表现亮眼。
- ⌛ **任务求解效率**。在ScienceWorld环境中,ETO仅需更少的动作步数即可获得更高的奖励值。
- 💡 **极端场景应用潜力**。在无专家轨迹可用的自博弈场景中,ETO同样展现出更优的性能。
## 专家轨迹数据集说明
本数据集包含三大智能体环境的专家轨迹:
- **WebShop**:我们预处理了WebShop原作者提供的官方[人类演示数据](https://github.com/princeton-nlp/WebShop/issues/21),同时通过GPT-4在环境中进行探索,并筛选出奖励值大于0.7的轨迹。
- **ScienceWorld**:该环境自带启发式算法,可生成最优轨迹。
- **ALFWorld**:原作者提供了少量人工标注的轨迹,用于模仿学习。
由于原始轨迹未包含每一步动作的思维链(Chain of Thought,CoT)信息,我们通过GPT-4生成了对应的推理依据。
## 🛠️ 环境配置与评估
详细的环境配置与评估流程请参阅我们的[GitHub仓库](https://github.com/Yifan-Song793/ETO)。
## 📑 智能体训练数据格式
json
[
{
"id": "example_0",
"conversations": [
{
"from": "human",
"value": "Who are you?"
},
{
"from": "gpt",
"value": "I am Vicuna, a language model trained by researchers from Large Model Systems Organization (LMSYS)."
},
{
"from": "human",
"value": "Have a nice day!"
},
{
"from": "gpt",
"value": "You too!"
}
]
}
]
## 📖 引用方式
如果您认为本数据集对您的研究有所帮助,请引用我们的论文:
bibtex
@article{song2024trial,
author={Yifan Song and Da Yin and Xiang Yue and Jie Huang and Sujian Li and Bill Yuchen Lin},
title={Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents},
year={2024},
eprint={2403.02502},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
maas创建时间:
2025-05-29
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集为ETO(探索式轨迹优化)框架提供专家轨迹,涵盖WebShop、ScienceWorld和ALFWorld三个代理环境,并利用GPT-4补充了推理信息。它支持基于失败-成功轨迹对比的代理策略学习,旨在提升LLM代理的任务解决能力。
以上内容由遇见数据集搜集并总结生成


