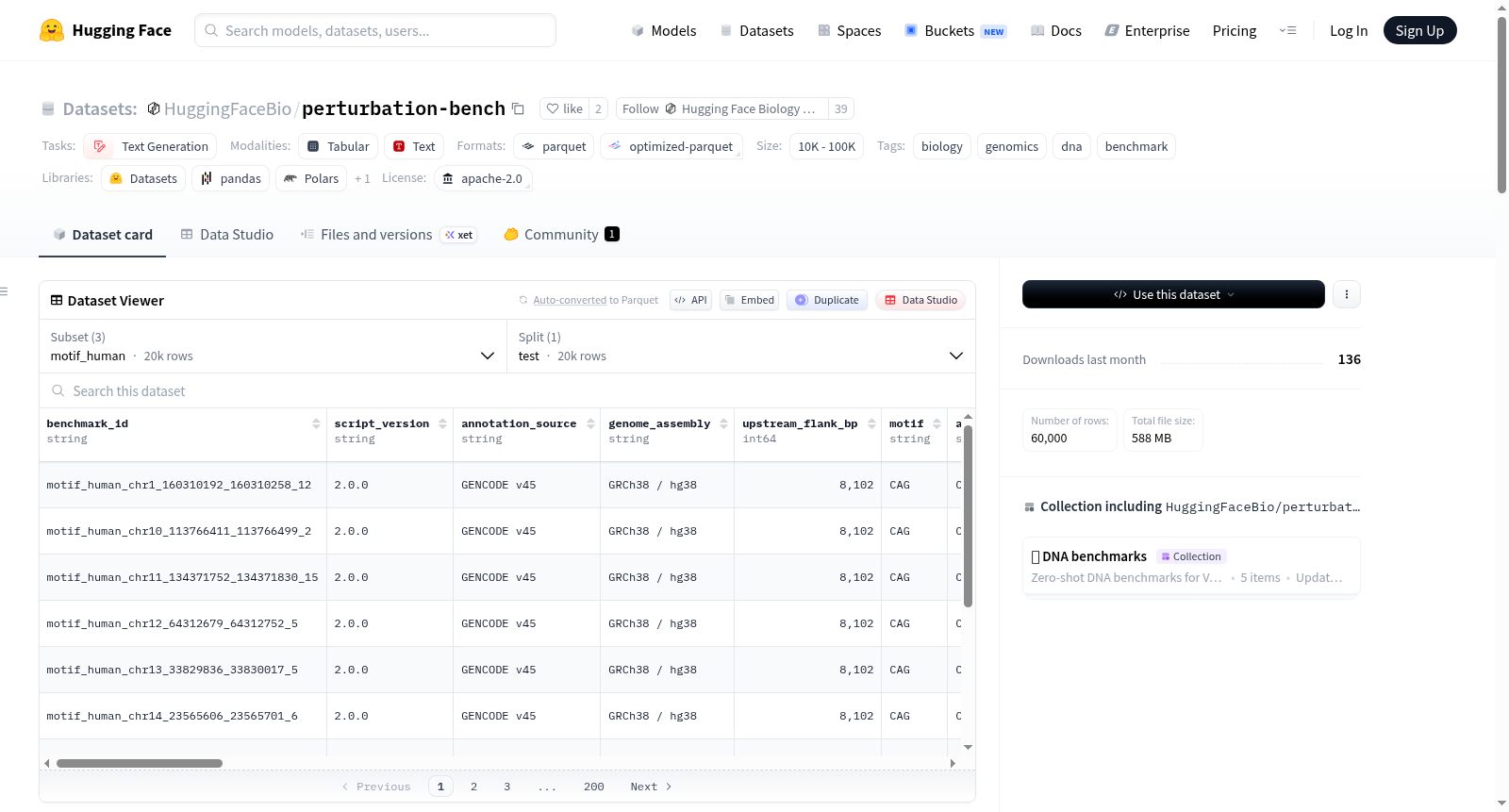
perturbation-bench
收藏数据集详情总结:Perturbation Bench
数据集概述
Perturbation Bench 是一个用于评估 DNA 基础模型的序列级扰动任务基准数据集。该数据集提供了成对的基因组序列——一条是真实的(未扰动的),另一条是结构改变的——并评估模型是否对原始序列赋予更高的对数似然值。评估指标为成对判别准确率:mean(LL(original) > LL(perturbed))。
许可协议
- Apache-2.0
任务与数据集配置
该数据集包含三个配置(config),每个配置包含 20,000 个测试样本:
1. syn_human —— 人类同义密码子替换
- 描述:将真实 CDS 区域内的密码子替换为目标物种最高频率的同义密码子,上下游侧翼序列保持不变,氨基酸序列被保留。
- 注释来源:GENCODE v45,参考基因组 GRCh38/hg38
- 密码子频率来源:CoCoPUTs(H. sapiens RefSeq CDS)
- 独特基因数:9,616
- 窗口大小:8,192 bp,以 CDS 为中心
- 密码子变化比例:平均约 55%(范围 10%–95%)
- 数据大小:下载 152.7 MB,数据集 335.9 MB
2. syn_mouse —— 小鼠同义密码子替换
- 描述:与人类配置相同,但针对小鼠基因组。
- 注释来源:GENCODE vM34,参考基因组 GRCm39/mm39
- 密码子频率来源:CoCoPUTs(M. musculus RefSeq CDS)
- 独特基因数:10,253
- 窗口大小:8,192 bp,以 CDS 为中心
- 密码子变化比例:平均约 55%(范围 10%–95%)
- 数据大小:下载 152.7 MB,数据集 336.1 MB
3. motif_human —— CAG 重复序列插入
- 描述:将 CDS 外显子第一个完整密码子下游 60 bp 处的一个 30 bp 密码子对齐区域替换为 10 个连续的 CAG 三联体,模拟导致多聚谷氨酰胺疾病(亨廷顿病、SCA、DRPLA)的病理性三核苷酸重复扩展。替换保持了序列长度和阅读框架。
- 注释来源:GENCODE v45 / GRCh38
- 独特基因数:9,705
- 窗口大小:8,192 bp
- 窗口布局:第一个完整 CDS 密码子始终位于位置 8,102;补丁始终位于位置 8,162–8,192
- 数据大小:下载 152.1 MB,数据集 334.8 MB
数据模式(Schema)
所有配置共享以下关键列:
| 列名 | 描述 |
|---|---|
original_sequence |
真实的、未扰动的基因组序列(正样本) |
sequence |
结构改变的序列(负样本) |
cds_start_in_seq / cds_end_in_seq |
窗口内 CDS 边界(bp 偏移量) |
chr, strand |
基因组位置 |
gene_name, transcript_id |
GENCODE 注释 |
benchmark_id |
唯一行标识符 |
配置特有字段
syn_human 和 syn_mouse 特有列:
recoding_mode,optimization_rate,random_seedwindow_size_bp,species,chrom_lengthupstream_actual,downstream_actual,is_clampedexon_rank,is_first_exon,frame,phase_gtfcds_length,patch_start_in_seq,patch_end_in_seq,patch_lengthn_codons_total,n_codons_eligible,n_codons_changed,fraction_codons_changedcodon_usage_source,genome_assembly,annotation_source,script_version
motif_human 特有列:
upstream_flank_bp,motif,actual_motif,patch_len_bp,start_after_bp,random_seedspecies,chrom_length,is_clampedexon_rank,is_first_exon,frame,phase_gtfcds_length,patch_start_in_cds,patch_end_in_cds,patch_start_in_seq,patch_end_in_seqannotation_source,genome_assembly,script_version
任务分类与标签
- 任务类别:文本生成
- 标签:生物学、基因组学、DNA、基准测试
使用示例
python from datasets import load_dataset
加载人类同义密码子替换任务
syn_human = load_dataset("HuggingFaceBio/perturbation-bench", "syn_human", split="test")
加载小鼠同义密码子替换任务
syn_mouse = load_dataset("HuggingFaceBio/perturbation-bench", "syn_mouse", split="test")
加载CAG基序插入任务
motif = load_dataset("HuggingFaceBio/perturbation-bench", "motif_human", split="test")
评估方法
提供现成的评估脚本,支持 Carbon、GENERator 和 Evo2 模型。示例命令:
bash python evaluation/perturbation_tasks.py --task syn_human --model HuggingFaceBio/Carbon-3B --bf16
python evaluation/perturbation_tasks.py --task motif_human --model arcinstitute/evo2_7b --backend evo2 --bf16