mari-pdf-corpus
收藏Hugging Face2025-07-19 更新2025-07-20 收录
下载链接:
https://huggingface.co/datasets/OneAdder/mari-pdf-corpus
下载链接
链接失效反馈官方服务:
资源简介:
Mari Press和School Books语料库是一个包含Meadow Mari和Hill Mari语言的文本语料库,文本主要来源于杂志和学校教材。语料库的第一部分包括不同年份的多种杂志,第二部分包括1933-1951年间出版的地理、数学等学科的教材。
Mari Press和School Books语料库是一个包含Meadow Mari和Hill Mari语言的文本语料库,文本主要来源于杂志和学校教材。语料库的第一部分包括不同年份的多种杂志,第二部分包括1933-1951年间出版的地理、数学等学科的教材。
创建时间:
2025-07-17
原始信息汇总
Mari Press and School Books Corpus 数据集概述
数据集描述
- 语言:包含Meadow Mari和Hill Mari两种语言的文本语料库。
- 内容:从PDF提取的纯文本,带有基本元数据,但无额外标注。
- 特点:文本因PDF提取而较为杂乱。
数据集来源
- 基于Mari Lab的杂志和学校教材PDF文本。
数据集组成
第一部分:杂志
| 杂志名称 | 语料库中的名称 | 年份 | 语言 |
|---|---|---|---|
| У вий | U_Viy_* | 1926–1936 | Meadow Mari,偶见Hill Mari |
| Пиалан илыш | пиалан_илыш_* | 1926–1936 | Meadow Mari |
| Родина верч | родина_верч_* | 1942–1945 | Meadow Mari |
| Марий альманах | марий_альманах_* | 1946–1949 | Meadow Mari |
| Ончыко | ончыко_* | 1954-2022 | Meadow Mari,偶见Hill Mari |
| Марий сандылак | марий_сандалык_* | 2008-2018 | Meadow Mari,偶见Hill Mari |
| У сэм | у_сэм_* | 1930-1934 | Hill Mari |
| Йакшар знамӹ | йакшар_знамӹ_* | 1935-1936 | Hill Mari |
| У сем | у_сем_* | 1990-2018 | Hill Mari |
注意事项:
- 部分杂志在不同年份有不同名称。
- 1938年书写系统有微小变化,如需现代书写,可通过
year字段过滤。
第二部分:学校教材
- 内容:1933-1951年间的地理、数学等科目教材。
预处理
- 分类:根据PDF质量分为
clean、ocr、fix、remap四类。 - 处理:对不同类别的PDF进行相应编码转换和字符修正。
过滤
- 方法:使用逻辑回归分类器识别并移除俄语部分。
数据集指标
| 总数 | 仅Hill Mari | 仅Meadow Mari | 无OCR | 现代书写 | |
|---|---|---|---|---|---|
| 文本数 | 878 | 176 | 563 | 166 | 701 |
| 标记数* | 45,576,320 | 5,081,705 | 32,426,529 | 8,192,294 | 41,520,480 |
*标记使用nltk.tokenize.casual.TweetTokenizer,因PDF杂质可能不准确。
引用
bibtex @online{mari_press_and_school_books_corpus, author = {Andrei Chemyshev and Michael Voronov}, title = {Mari Press and School Books Corpus}, year = 2025, url = {https://huggingface.co/datasets/OneAdder/mari-pdf-corpus}, urldate = {2025-07-17} }
搜集汇总
数据集介绍
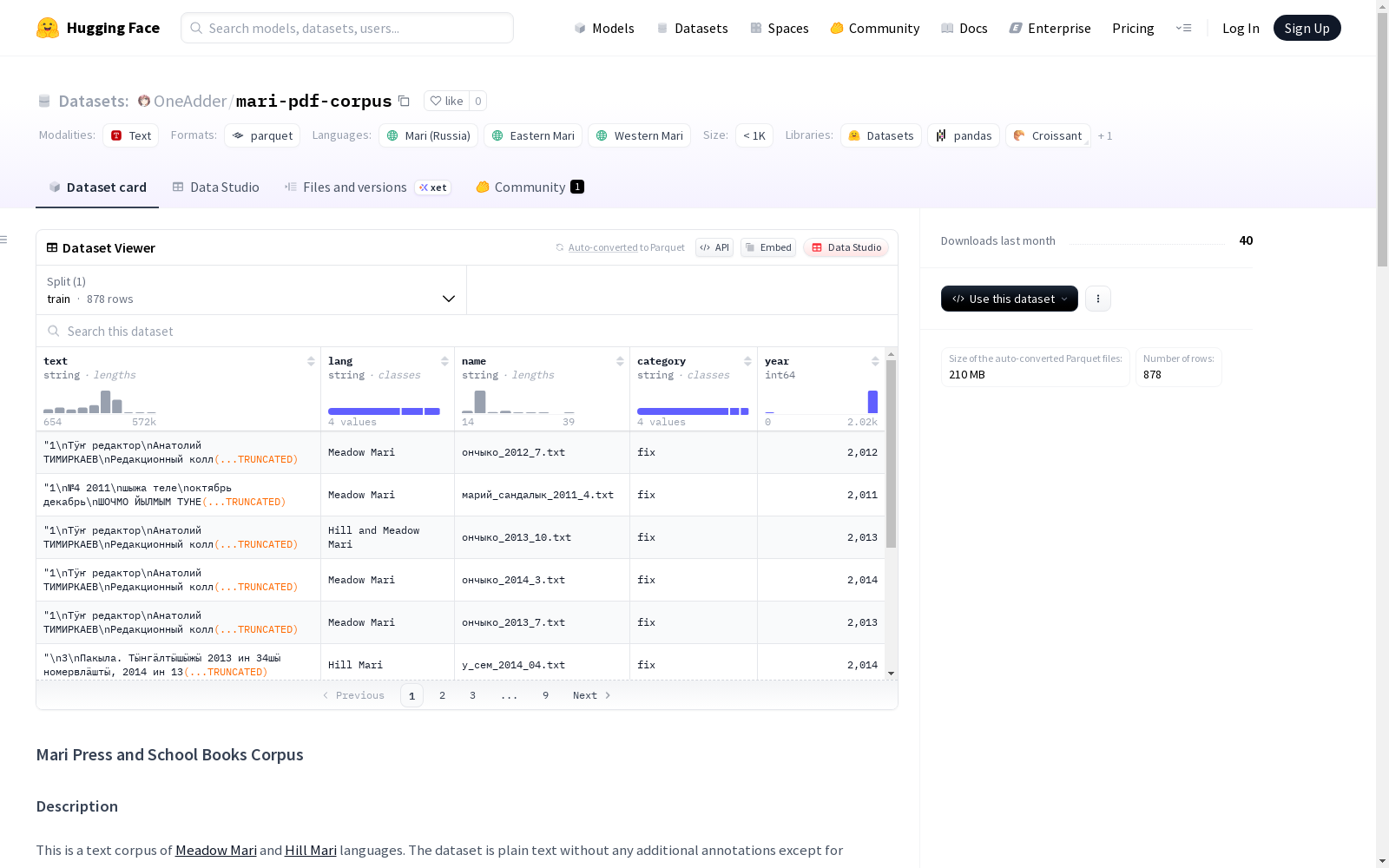
构建方式
该数据集基于Mari Lab提供的PDF文本资源构建,涵盖草地马里语和山地马里语两种语言的杂志与教科书内容。通过复杂的预处理流程,将原始PDF分为清洁文本、OCR识别文本、编码修复文本和字符重映射文本四类进行处理,其中后两类经过特定编码转换和字符校正。针对文本中混杂的俄语内容,研究者开发了基于逻辑回归的分类器进行有效过滤,确保语料的语言纯净度。
特点
数据集收录1926至2022年间878个文本样本,包含45,576,320个标记,全面覆盖两种马里语的现代与历史变体。独特之处在于同时收录杂志与教科书两类文本,并精确标注了语言种类、出版年份和文本类别等元数据。特别值得注意的是,数据集保留了1938年文字改革前的历史拼写形式,为语言演变研究提供珍贵素材。文本虽因PDF转换存在一定噪声,但经过严格的清洗和分类处理。
使用方法
使用者可通过HuggingFace平台直接加载数据集,利用预置的语言、年份和类别字段进行灵活筛选。建议研究者重点关注现代书写文本(year≥1938)或特定杂志序列的历时分析。由于文本包含PDF转换噪声,建议配合NLP预处理工具使用。数据集特别适用于低资源语言建模、历史语言学研究和双语平行语料构建,引用时请遵循提供的BibTeX格式。
背景与挑战
背景概述
Mari-PDF-Corpus是由Andrei Chemyshev和Michael Voronov于2025年构建的文本数据集,专注于记录和保存梅德韦马里语(Meadow Mari)和山地马里语(Hill Mari)这两种濒危乌拉尔语言的书面文献。该数据集依托Mari Lab的数字化资源,收录了1926至2022年间出版的杂志及1933至1951年的教科书文本,涵盖了近一个世纪的语言演变历程。作为少数系统整理马里语文本的语料库之一,它不仅为乌拉尔语言学研究提供了珍贵的一手资料,更为濒危语言的数字化保存与自然语言处理研究树立了重要范例。
当前挑战
该数据集面临的核心挑战体现在语言处理与数据质量两个维度。在领域问题层面,马里语作为低资源语言,其复杂的形态变化和1938年正字法改革导致的书写差异,对文本标准化与模型训练构成显著障碍。数据构建过程中,原始PDF存在文本层缺失、编码混乱(如cp1251与UTF-8混用)、OCR识别错误等问题,需采用分类修复策略处理;同时杂志中俄语内容的混杂,迫使研究者开发专用分类器进行语种过滤。这些技术难题使得最终语料虽经严格清洗,仍保留部分噪声数据,对后续研究的可靠性提出更高要求。
常用场景
经典使用场景
在乌拉尔语系研究中,Mari-PDF-Corpus作为罕见的马里语文本资源,为语言学家提供了研究草地马里语和山地马里语历时演变的珍贵素材。该数据集特别适合用于构建历时语言模型,通过1926-2022年间跨度近百年的杂志文本,研究者能够追踪马里语正字法改革前后的词汇、语法变化规律。
衍生相关工作
基于该数据集衍生的经典研究包括马里语形态分析器Morpho-Mari的开发,以及跨语言词嵌入项目UralicVec。在ACL等顶级会议上,已有学者利用该数据集进行低资源语言建模研究,相关成果推动了《马里语数字语料库建设标准》的制定工作。
数据集最近研究
最新研究方向
近年来,随着濒危语言保护意识的提升,Mari语系文本语料库的研究价值日益凸显。该数据集作为涵盖草地马里语和山地马里语的珍贵历史文献集合,为计算语言学和数字人文领域提供了独特的研究素材。当前研究热点集中在基于深度学习的低资源语言处理技术开发,特别是针对PDF噪声数据的自适应预训练模型构建。该语料库中1926-2022年间杂志和教科书的多时期文本特性,为语言演变分析和跨时代机器翻译任务提供了理想实验平台。在语言技术应用层面,研究者正探索利用该数据集改进马里语-俄语双语模型的性能,以支持俄罗斯马里埃尔共和国地区的教育信息化建设。
以上内容由遇见数据集搜集并总结生成


