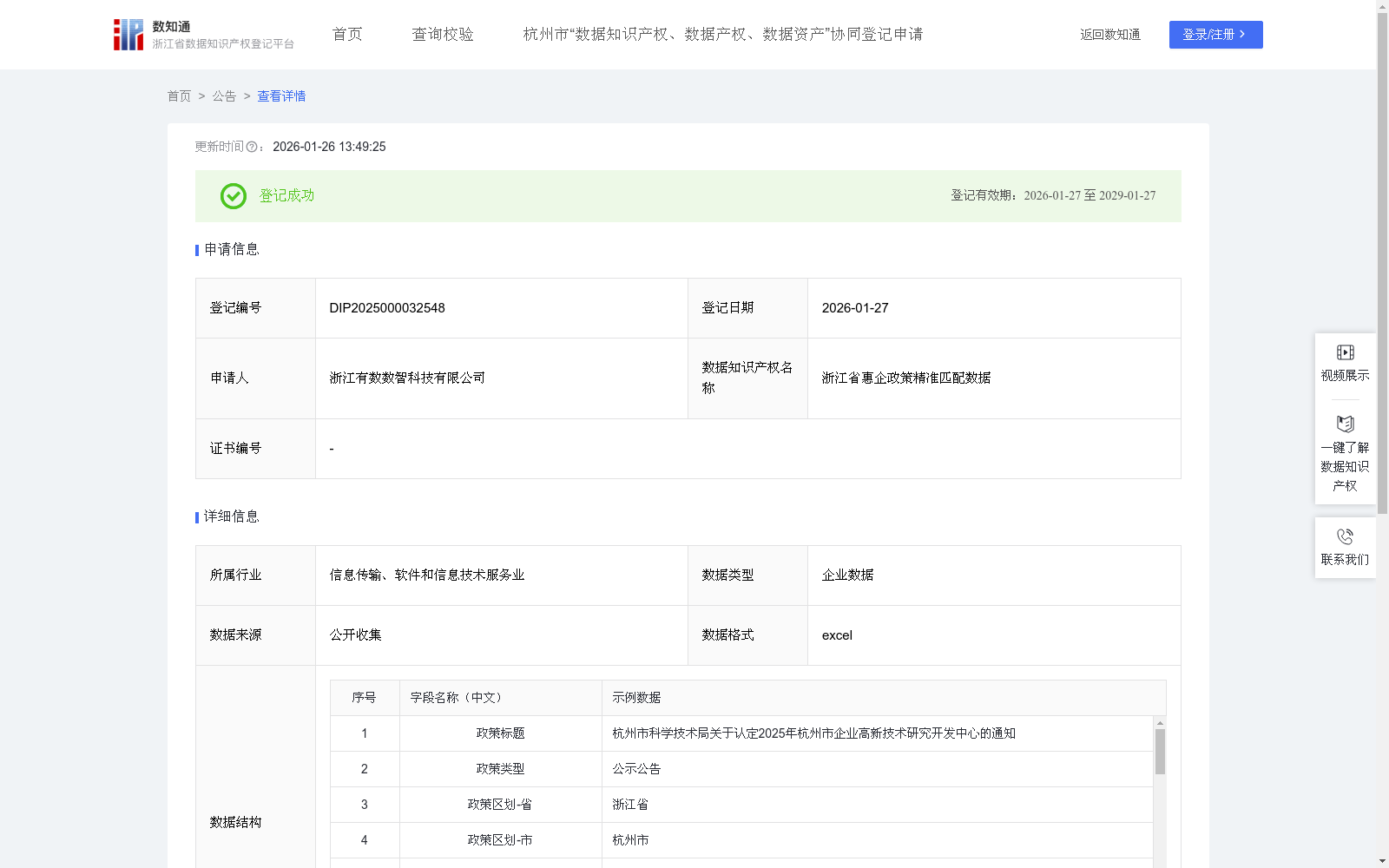
浙江省惠企政策精准匹配数据
收藏浙江省数据知识产权登记平台2026-01-26 更新2026-01-27 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8424544
下载链接
链接失效反馈官方服务:
资源简介:
我司基于浙江省各级政府的公开政策信息,为解决政策分布较为散乱、更新与维护不及时、政策信息难以有效触达企业等问题,通过构建全面,及时,准确的政策信息数据场景,完成数据采集、数据清洗、模型构建、验证全过程,形成涵盖浙江的政策相关信息数据,能够有效帮助企业快速定位符合自身条件的优惠政策、评估申报可行性及预期收益,同时辅助政府机构提升政策触达精度与兑现效率,解决政策信息不对称、申报流程复杂、企业获得感不强等具体问题。政企申报匹配度 = 政企关系相似度评分×α + 政策标签匹配评分×β(α、β 为权重系数)。政企关系相似度评分基于企业历年申报政策数据,结合政策重要性(政策级别,政策类型等),申报条件等构建带权有向图,融合企业注册资本、行业属性等多个固有因子,再通过剪枝算法与推荐池清洗筛选得出;政策标签匹配评分依托大模型从政策文本中提取核心标签(如适用企业行业,适用企业性质等),结合专家经验和历史数据适配机制,按照多标签适配逻辑计算;最终得以量化政策与企业的匹配程度。
Our company, based on public policy information from governments at all levels in Zhejiang Province, aims to address issues including scattered policy distribution, delayed updates and maintenance, and the difficulty of effectively delivering policy information to enterprises. By building a comprehensive, timely and accurate policy information data scenario, we have completed the full workflow of data collection, data cleaning, model construction and validation, and compiled policy-related information data covering all of Zhejiang Province. This dataset can effectively help enterprises quickly locate preferential policies matching their own qualifications, evaluate the declaration feasibility and expected benefits, assist government agencies in improving the accuracy of policy outreach and the efficiency of policy implementation, and solve specific problems such as policy information asymmetry, complicated declaration procedures, and low sense of gain among enterprises.
The government-enterprise declaration matching degree is defined as: Government-Enterprise Declaration Matching Degree = Government-Enterprise Relationship Similarity Score × α + Policy Tag Matching Score × β, where α and β are weight coefficients.
The Government-Enterprise Relationship Similarity Score is derived by first constructing a weighted directed graph based on enterprises' annual historical policy declaration data, combined with policy importance (including policy level, policy type, etc.), declaration conditions and other factors, integrating multiple intrinsic factors such as enterprises' registered capital and industry attributes, then obtaining the final score via pruning algorithms and recommendation pool cleaning and screening.
The Policy Tag Matching Score is calculated by extracting core tags from policy texts using the Large Language Model (LLM) — such as applicable enterprise industry and applicable enterprise nature — combining with expert experience and historical data adaptation mechanisms, and applying multi-label adaptation logic. Ultimately, the matching degree between policies and enterprises can be quantified.
提供机构:
浙江有数数智科技有限公司
创建时间:
2025-11-14
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集专注于浙江省惠企政策的精准匹配,包含政策信息(如标题、类型、适用条件)和企业信息(如名称、行业、经营状态)的结构化数据,规模为1000条并每日更新。它通过算法模型量化政策与企业的匹配度,旨在解决政策信息不对称问题,帮助企业快速定位适用政策并辅助政府提升政策兑现效率。
以上内容由遇见数据集搜集并总结生成


