ndl-core-structured-data
收藏Hugging Face2026-01-12 更新2026-01-13 收录
下载链接:
https://huggingface.co/datasets/theodi/ndl-core-structured-data
下载链接
链接失效反馈官方服务:
资源简介:
NDL Core – Structured Data是一个经过整理的英国公共部门结构化数据集集合,已转换为Apache Parquet格式以提高分析和机器学习工作流的效率。该数据集是更广泛的NDL Core Corpus的一部分,专注于表格/结构化数据,来源于英国政府及公共部门的权威平台,包括data.gov.uk、英国国家统计局(ONS)和英国环境、食品和农村事务部(Defra)。数据集旨在为研究、政策分析、数据科学和下游AI应用提供干净、分析就绪的基础。预期用途包括政策分析和评估、社会经济和环境研究、公共部门分析、机器学习模型的特征工程以及检索增强生成(RAG)流程。需要注意的是,数据集仅包含结构化数据,相关文本数据集在NDL Core Corpus中单独托管。数据集存在一些局限性,如数据反映的是爬取时的状态,某些数据集可能不完整、已过时或被上游替代,且不同来源的模式一致性不一,不保证实时更新。
创建时间:
2026-01-02
原始信息汇总
NDL Core Structured Data 数据集概述
数据集基本信息
- 数据集名称:NDL Core Structured Data
- 格式:Apache Parquet
- 数据规模:100M < n < 1B
概述
NDL Core – Structured Data 是一个精选的英国公共部门结构化数据集集合,已转换为 Apache Parquet 格式,旨在为高效分析和机器学习工作流提供支持。该数据集是更广泛的 NDL Core Corpus 的一部分,专注于提供干净、可直接用于分析的基础数据,适用于研究、政策分析、数据科学和下游人工智能应用。
数据来源
数据来源于以下英国公共部门:
- data.gov.uk
- 涵盖领域:交通、环境、健康、教育和政府运营等。
- 包含每个类别在爬取时最新的前10个数据集。
- 原始格式多样(CSV、XLSX、JSON),均已规范化并转换为 Parquet 格式。
- 英国国家统计局 (ONS)
- 提供关于人口、经济、劳动力市场、健康等方面的官方英国统计数据。
- 包含常用于研究和政策制定的高价值国家数据集。
- 环境、食品和农村事务部 (Defra)
- 提供环境、农业和农村数据。
- 包含与土地利用、气候、农业和自然资源相关的数据集。
预期用途
- 政策分析与评估
- 社会经济与环境研究
- 公共部门分析
- 机器学习模型的特征工程
- 检索增强生成 (RAG) 流程
- 与政府文本语料库的数据集成
与 NDL Core Corpus 的关系
本仓库仅包含结构化数据。相关的文本数据集(政府指南、议会辩论、立法文件)单独托管在 NDL Core Corpus 仓库中。这些数据集共同支持对英国公共部门信息的混合结构化和非结构化分析。
局限性
- 数据反映了爬取时源数据集的状态。
- 部分数据集可能不完整、已弃用或在上游已被取代。
- 不同来源之间的模式一致性存在差异。
- 不保证实时更新。
搜集汇总
数据集介绍
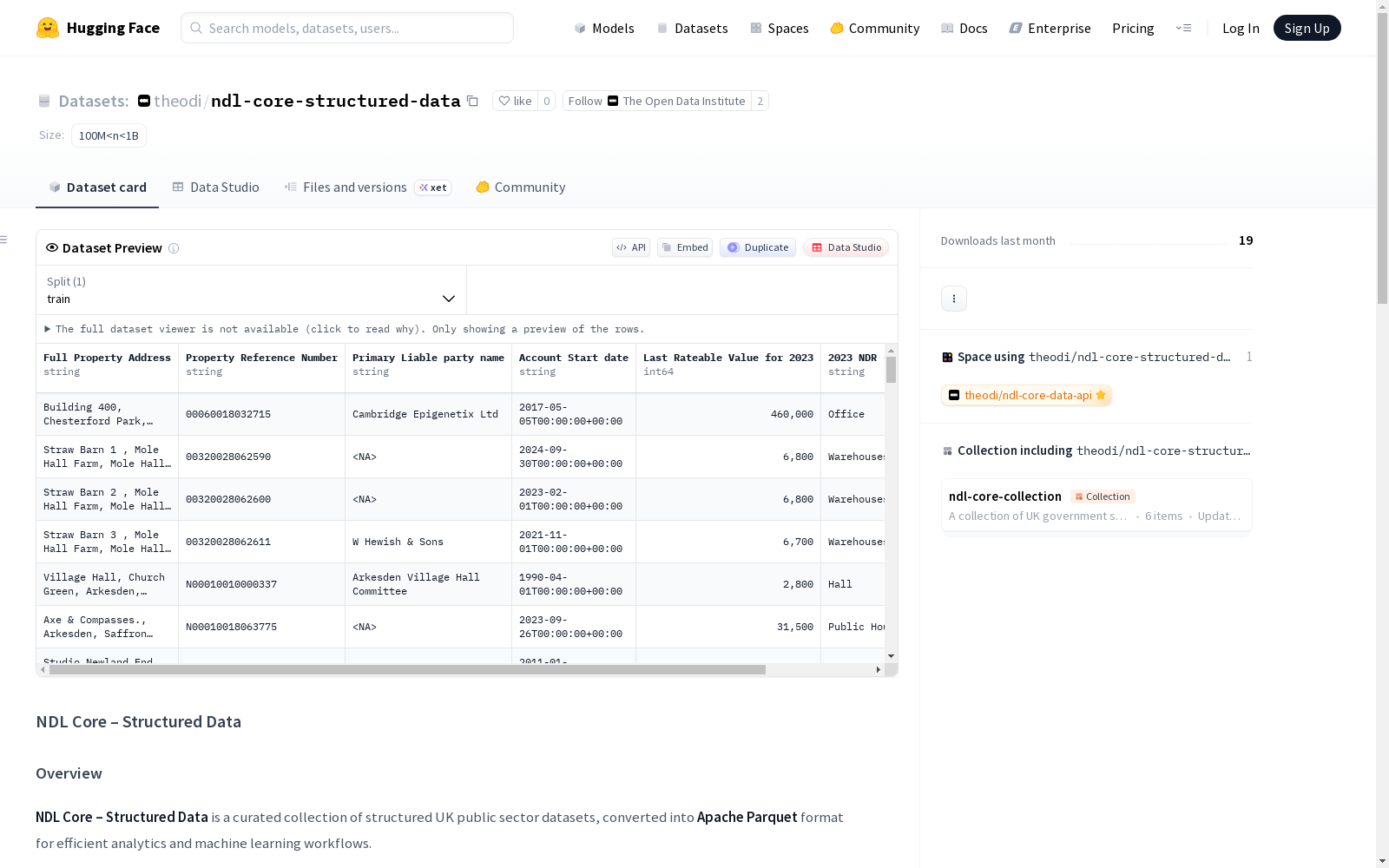
构建方式
在公共数据整合领域,NDL Core – Structured Data 数据集通过系统化流程构建而成。其核心方法是从英国公共部门的权威平台进行定向采集,涵盖 data.gov.uk、国家统计局以及环境、食品与农村事务部等多个来源。采集过程中,优先选取各领域内最新的前十项数据集,确保内容的时效性与代表性。原始数据格式多样,包括 CSV、XLSX 和 JSON 等,均经过规范化处理并统一转换为 Apache Parquet 格式,以提升存储与访问效率。这一构建方式不仅保证了数据的结构一致性,也为后续的分析与应用奠定了坚实基础。
特点
该数据集展现出多维度特点,其核心在于专注于英国公共部门的结构化信息,覆盖交通、环境、健康、教育及政府运作等多个关键领域。数据以 Parquet 格式存储,具备高效的压缩与列式存储优势,适合大规模数据分析与机器学习任务。作为 NDL Core 语料库的一部分,该数据集与文本数据资源相互补充,支持结构化与非结构化信息的混合分析。尽管数据在采集时力求完整,但需注意其可能存在的模式不一致性或上游更新延迟,这要求使用者在应用中结合具体情境进行验证。
使用方法
在应用层面,该数据集为政策分析、社会经济研究及公共部门分析提供了直接支持。用户可通过标准的数据处理工具加载 Parquet 文件,进行特征工程或集成至机器学习模型。其结构化特性也使其适用于检索增强生成流程,或与相关文本语料库结合,实现跨模态的信息融合。建议使用者在访问数据时,参考源平台的更新状态,并注意数据采集时间点可能带来的局限性,以确保分析结果的准确性与时效性。
背景与挑战
背景概述
在公共数据开放与政府透明化浪潮的推动下,英国政府及公共部门积累了海量的结构化数据资源。NDL Core – Structured Data数据集由开放数据研究所(The Open Data Institute, ODI)等机构主导构建,旨在整合来自data.gov.uk、国家统计局(ONS)及环境、食品与农村事务部(Defra)等权威来源的英国公共部门结构化数据,并将其统一转换为Apache Parquet格式,以支持高效的数据分析、政策研究与机器学习应用。该数据集作为NDL Core Corpus的重要组成部分,与文本语料库相辅相成,为跨领域的社会经济与环境研究提供了坚实的数据基础,显著提升了公共数据在科研与决策中的可及性与实用性。
当前挑战
该数据集致力于解决公共部门数据整合与标准化这一核心领域问题,其挑战在于原始数据来源多样、格式不一,且涵盖交通、环境、健康等多领域,确保数据质量与一致性难度较大。在构建过程中,团队需克服数据爬取时的时效性局限,部分数据集可能存在不完整或已过时的情况;同时,不同来源的数据模式(Schema)差异显著,进行规范化转换与清洗需耗费大量工程努力。此外,保持数据集与上游更新的同步,并维护其长期有效性,亦是持续面临的现实挑战。
常用场景
经典使用场景
在公共政策与社会科学研究领域,NDL Core Structured Data数据集为学者提供了分析英国公共部门结构化信息的坚实基础。其经典使用场景聚焦于政策评估与决策支持,研究人员能够利用该数据集整合多源政府统计数据,构建跨领域的分析模型,揭示社会经济趋势与环境变化之间的内在关联,从而为政策制定提供实证依据。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,特别是在结合文本与结构化数据的混合分析领域。例如,研究团队利用该数据集与NDL Core Corpus中的文本数据,开发了检索增强生成(RAG)管道,用于自动生成政策简报或立法影响分析报告。此外,该数据集也促进了跨机构数据整合框架的开发,为构建更全面的政府知识图谱奠定了基础。
数据集最近研究
最新研究方向
在公共数据科学领域,NDL Core Structured Data作为英国公共部门结构化数据的高质量集合,正推动着政策智能分析的前沿探索。研究者们借助其标准化的Parquet格式,将数据集与文本语料库结合,构建混合检索增强生成(RAG)管道,以支持更精准的政策评估与决策模拟。当前热点聚焦于利用该数据集进行跨领域社会经济与环境指标的整合分析,例如通过机器学习模型预测政策影响或自动化生成政府报告。这些进展不仅提升了公共部门数据的可访问性与分析效率,也为透明治理和证据驱动政策制定提供了坚实的数据基础,在开放数据运动中具有示范意义。
以上内容由遇见数据集搜集并总结生成


