ndl-core-corpus
收藏Hugging Face2026-01-12 更新2026-01-13 收录
下载链接:
https://huggingface.co/datasets/theodi/ndl-core-corpus
下载链接
链接失效反馈官方服务:
资源简介:
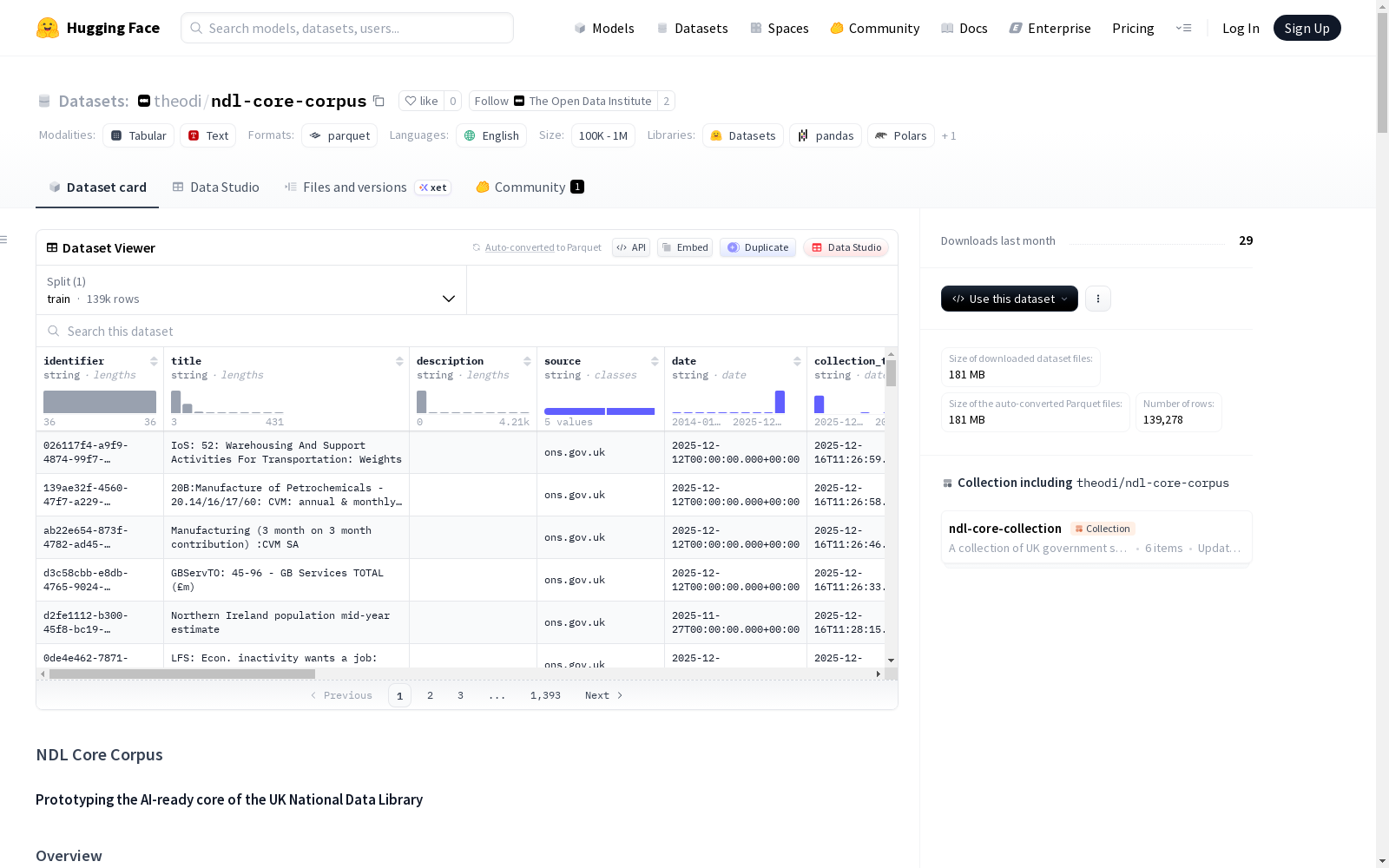
NDL核心语料库是一个实验性的、适合AI使用的英国公共部门数据集合,作为拟议的国家数据图书馆(NDL)的最小可行原型(MVP)开发。该数据集展示了如何将异构的公共部门数据进行跨机构联合、标准化和清理,并结构化以支持现代AI用例,如检索增强生成(RAG)、知识图谱和代理系统。语料库包括来自GOV.UK、Hansard、legislation.gov.uk等来源的文本数据,以及来自data.gov.uk、ONS和Defra的结构化数据。数据集遵循共享的元数据模式,确保跨异构来源的一致性和可追溯性。处理流程强调标准化格式、语义一致性和数据质量。数据集是一个原型,覆盖范围有限,旨在展示可能性而非替代官方发布渠道。
创建时间:
2026-01-01
原始信息汇总
NDL Core Corpus 数据集概述
数据集简介
NDL Core Corpus 是一个实验性的、面向人工智能的英国公共部门数据聚合数据集,作为拟议的国家数据图书馆的最小可行原型开发。该数据集展示了异构公共部门数据如何实现跨机构联合、标准化清理以及结构化与文档化,以支持现代人工智能用例。
目的与用例
- 支持使用英国公共部门数据进行人工智能实验。
- 为人工智能代理构建知识库。
- 支持检索增强生成管道。
- 支持政策研究与评估。
- 用于原型化数据基础设施。
- 特别适用于语义搜索、问答、跨领域模式发现、公共部门感知语言模型以及基于结构化元数据和文本进行推理的智能体系统。
数据集构成
该语料库聚合了来自以下来源的近期且具有代表性的英国公共部门数据:
文本数据
- GOV.UK:政策指南和政府出版物。
- Hansard:英国议会辩论记录。
- legislation.gov.uk:法定文书和议会法案。
结构化数据
- data.gov.uk:每个类别下最新的前10个数据集。
- 英国国家统计局。
- 环境、食品和农村事务部。
数据集概览
按来源统计的记录数
| 来源 | 记录数量 |
|---|---|
| Hansard | 75897 |
| GOV.UK | 60406 |
| legislation.gov.uk | 1708 |
| data.gov.uk | 1207 |
| 英国国家统计局 | 60 |
数据模态细分
| 数据类型 | 记录数量 |
|---|---|
| 文本数据 | 138443 |
| 结构化数据 | 835 |
语料库规模指标
| 指标 | 数值 |
|---|---|
| 总词数 | 52837450 |
| 总标记数 | 75020687 |
元数据覆盖率
| 指标 | 覆盖率 |
|---|---|
| 带有欧盟数据主题标签的记录 | 43.44% |
元数据模式
每个记录遵循共享的元数据模式以确保一致性、可追溯性和AI就绪性。核心字段包括:
identifier:全局唯一标识符。title:资源标题。description:描述或摘要。source:数据来源。date:原始发布日期。collection_time:数据收集时间戳。open_type:开放类型分类。license:使用许可。tags:自动分配的欧盟数据主题词汇标签。language:内容语言。format:数据格式。text:提取的全文内容。word_count:词数。token_count:标记数。data_file:关联结构化数据文件的相对路径(文件位于 https://huggingface.co/datasets/theodi/ndl-core-structured-data 数据集)。extra_metadata:源特定的额外元数据。
处理与标准化
所有组件数据集均通过共享的自动化流程进行处理以确保AI就绪性,关键特性包括:
- 标准化格式:使用ISO 8601日期时间、UTF-8编码、一致的
null值处理、自动生成欧盟数据主题标签。 - 语义一致性:规范化的字段名称、共享词汇表。
- 数据质量:去重、个人身份信息移除。
- 统一存储:以Apache Parquet格式交付。
相关数据处理流程详情见 https://github.com/theodi/ndl-core-data-pipeline/tree/main。
方法论
完整的开发过程均有文档记录,并基于ODI的数据、人工智能与集体智慧计划及其AI就绪数据框架。
局限性
- 这是一个原型,非生产系统。
- 覆盖范围是选择性的,非穷尽的。
- 由于来源多样性,部分语义协调较浅。
- 不保证实时更新。
许可与归属
- 所有数据均源自英国公共部门,在各自开放许可下重用。
- 用户需遵守源特定的许可条款。
- 尽可能在元数据中保留来源信息。
联系与贡献
该数据集是持续探索性工作的一部分,可通过 https://github.com/theodi/ndl-core-data-pipeline 提交问题、建议或扩展。
搜集汇总
数据集介绍
构建方式
在构建英国公共部门数据资源库的背景下,NDL核心语料库通过集成异构数据源,展示了数据联邦化的可行性。该数据集从GOV.UK、议会辩论记录、立法文件及多个政府统计门户中,选取近期代表性数据,运用自动化流水线进行标准化清洗。处理流程涵盖去重、个人身份信息移除,并采用统一元数据模式,确保日期格式、编码与标签体系的一致性,最终以Apache Parquet格式存储,为AI应用提供结构化基础。
使用方法
该数据集适用于支持检索增强生成、智能体知识库构建及政策分析等场景。用户可通过标准化的元数据字段进行跨域检索,利用文本内容与结构化数据的关联实现语义查询。数据集以分块形式组织,便于直接接入机器学习流水线;结合附带的标记化统计信息,可优化嵌入模型训练与评估。开发者可依据开源方法论复现处理流程,并在遵守原始许可的前提下,将其集成于AI驱动的研究或应用原型中。
背景与挑战
背景概述
在数据科学与人工智能领域,构建高质量、标准化的公共数据资源库对于推动政策研究、知识发现与智能系统发展至关重要。NDL Core Corpus数据集由英国开放数据研究所(ODI)主导,作为国家数据图书馆(NDL)的最小可行原型,于近期创建,旨在整合英国公共部门的异构数据。该数据集的核心研究问题聚焦于如何实现跨机构数据的联邦化聚合、标准化清洗与结构化文档化,以支持检索增强生成、知识图谱构建及智能体系统等现代AI应用。通过汇聚政府出版物、议会辩论记录、立法文本及统计数据集等多模态数据,它不仅为AI实验提供了丰富语料,也为公共数据基础设施的演进树立了实践标杆,显著提升了数据在跨领域模式发现与语义推理中的可用性。
当前挑战
NDL Core Corpus面临的挑战主要体现在领域问题与构建过程两方面。在领域层面,数据集致力于解决公共部门数据在AI驱动下的语义集成与知识抽取难题,其挑战在于如何从异构、多源的文本与结构化数据中实现深层次的语义对齐,以支持复杂的检索增强生成与智能体推理任务,这要求模型能够理解政策语境、法律条文与统计指标间的隐含关联。构建过程中的挑战则源于数据源的多样性与标准化难度,包括跨机构数据的格式统一、元数据模式的一致性维护、个人身份信息的合规去除,以及在有限资源下实现语义标注的深度与覆盖度平衡。此外,作为原型系统,数据集在实时更新与全面性方面存在局限,需在扩展性与数据质量间寻求优化路径。
常用场景
经典使用场景
在人工智能与公共数据融合的前沿领域,NDL Core Corpus作为英国公共部门数据的实验性聚合体,其经典使用场景聚焦于构建知识增强型AI系统。该数据集通过整合政府出版物、议会辩论记录及立法文本等多源异构数据,为检索增强生成(RAG)流程提供了标准化语料基础。研究者可依托其结构化元数据与清洗后的文本内容,训练语义搜索模型,实现跨政策文档的精准问答与模式挖掘,从而推动公共部门认知智能的发展。
解决学术问题
该数据集有效应对了公共数据AI化过程中的核心学术挑战,即异构数据源的联邦整合与语义对齐问题。通过实施统一的元数据模式与自动化处理流程,它解决了多机构数据标准化缺失、知识碎片化等难题,为构建可解释的政策分析模型提供了实验基准。其意义在于将国家数据图书馆的架构理念转化为可操作原型,促进了数据驱动型治理研究从理论框架向实证验证的过渡,为跨学科政策智能研究奠定了数据基础设施。
实际应用
在实际应用层面,NDL Core Corpus支撑着公共部门数字化转型的具体实践。政府部门可基于该数据集开发政策影响评估工具,通过分析历史立法与统计数据的关联,模拟政策推行的潜在效果。同时,它赋能了智能政务助手的构建,使AI代理能够依据实时更新的公共数据,为公民提供精准的法律咨询或服务指引。这些应用显著提升了公共数据资源的可及性与利用效率,推动了开放政府生态系统的智能化演进。
数据集最近研究
最新研究方向
在公共数据智能化的浪潮中,NDL核心语料库作为英国国家数据图书馆的原型,正推动着跨机构异构数据融合的前沿探索。当前研究聚焦于利用其标准化、多模态的结构,构建面向检索增强生成(RAG)和智能体系统的知识图谱,以支持政策分析与语义搜索。这一数据集为开发公共部门感知的语言模型提供了实验基础,促进了数据基础设施与人工智能技术的协同创新,在开放数据与集体智能领域具有重要的示范意义。
以上内容由遇见数据集搜集并总结生成


