original-language-bibles-hebrew
收藏Hugging Face2024-12-30 更新2024-12-31 收录
下载链接:
https://huggingface.co/datasets/hmcgovern/original-language-bibles-hebrew
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含古代希伯来语圣经和古希腊语新约的原始语言文本,具有单词级别的翻译和注释。数据集基于最早的抄本证据,从STEP Bible编译而来。数据集包含希伯来语和英语的圣经文本,具有单词级别的翻译和注释。
创建时间:
2024-12-19
搜集汇总
数据集介绍
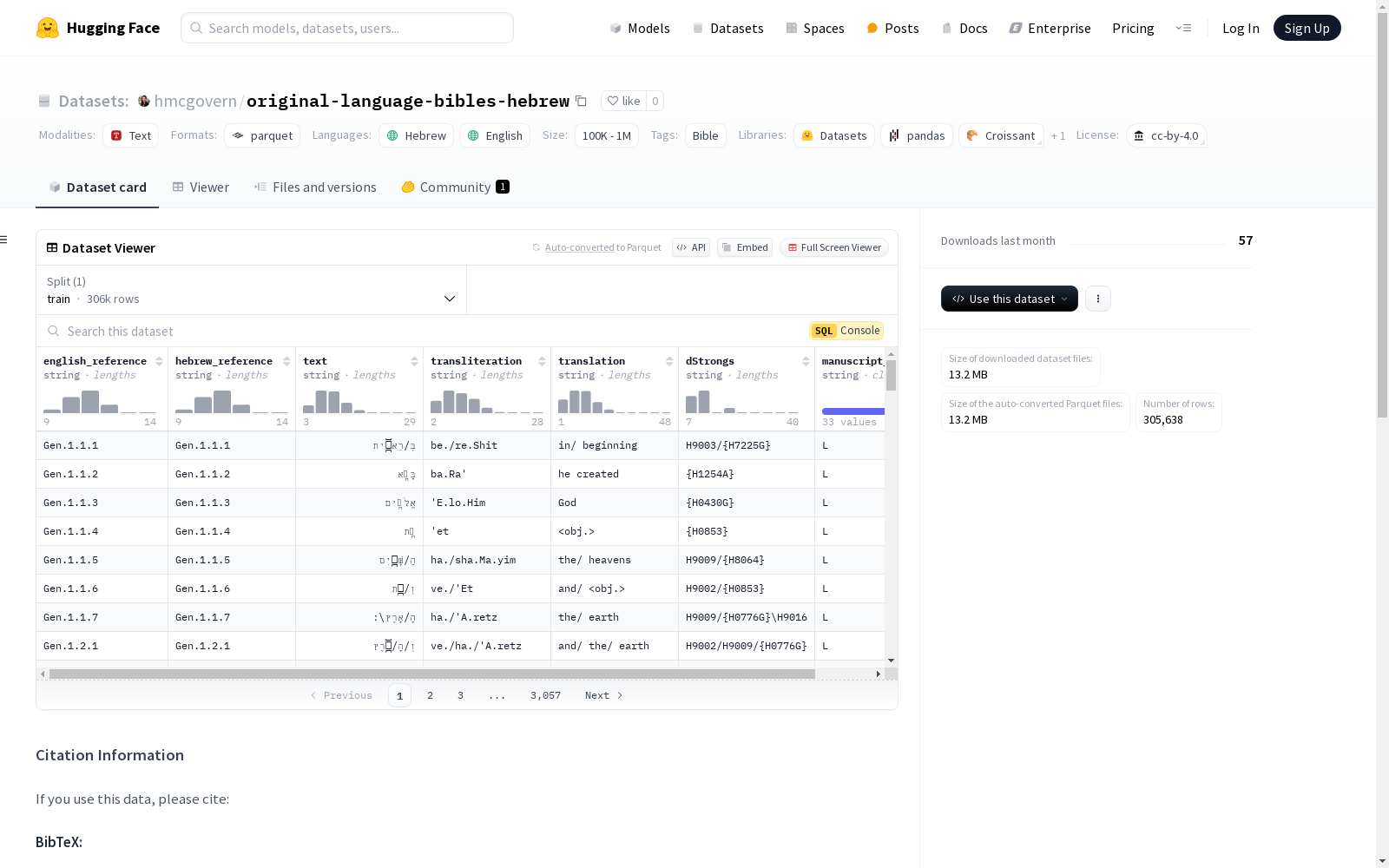
构建方式
该数据集基于最早的希伯来圣经手稿证据,通过STEP Bible平台进行编译,包含了希伯来圣经(旧约)的逐词注释和英文翻译。数据集的构建过程涉及从原始手稿中提取文本,并进行逐词级别的翻译和注释,确保每个词条都与其对应的希伯来原文、英文参考、音译、翻译以及Strong's词典编号相关联。这种精细的构建方式为研究者提供了丰富的语言学资源。
特点
该数据集的特点在于其逐词级别的注释和翻译,涵盖了希伯来圣经的每个词条,并提供了详细的英文参考、音译、翻译以及Strong's词典编号。此外,数据集还包含了手稿来源信息,使得研究者能够追溯每个词条的历史背景。数据集的语言涵盖了希伯来语和英语,适用于跨语言研究和圣经文本的深入分析。
使用方法
使用该数据集时,研究者可以通过`.map()`函数将数据聚合到行(节)级别,以便进行更宏观的文本分析。通过指定优先级(如希伯来语或英语),可以生成不同语言版本的节级数据。这种聚合方式不仅简化了数据分析过程,还为研究者提供了灵活的文本处理选项,使其能够根据研究需求进行定制化分析。
背景与挑战
背景概述
《Original Language Bible Corpus -- Ancient Hebrew》数据集由Hope McGovern于2024年创建,旨在为研究古代希伯来语圣经提供详尽的语料支持。该数据集基于最早的圣经手稿证据,收录了古代希伯来语圣经(旧约)的文本,并附有逐词注释和英文翻译。其数据来源主要依赖于STEP Bible项目,为圣经文本的语言学、翻译学以及宗教学研究提供了宝贵的资源。该数据集的发布不仅填补了古代希伯来语圣经研究领域的空白,还为跨语言文本分析、机器翻译等自然语言处理任务提供了重要的数据基础。
当前挑战
该数据集在构建与应用过程中面临多重挑战。首先,古代希伯来语圣经的文本结构复杂,包含大量古词汇和语法现象,如何准确进行逐词注释和翻译是核心难题。其次,数据集的构建依赖于早期手稿,这些手稿可能存在文本残缺或版本差异,如何确保数据的完整性与一致性成为关键问题。此外,将逐词注释的文本聚合为行级(如诗节)数据时,如何保持语义的连贯性与准确性也是技术上的挑战。这些问题的解决不仅需要深厚的语言学知识,还需借助先进的计算工具与方法。
常用场景
经典使用场景
在圣经文本研究中,original-language-bibles-hebrew数据集为学者提供了古代希伯来语圣经的原始文本及其逐字翻译,极大地便利了语言学和宗教学领域的深入分析。通过该数据集,研究者能够直接对比希伯来语原文与英语翻译,探索文本的语义和语法结构。
实际应用
在实际应用中,original-language-bibles-hebrew数据集被广泛用于圣经教学、宗教研究以及古代语言学习。教育机构可以利用该数据集进行希伯来语教学,帮助学生理解圣经文本的原始语言。此外,宗教研究者可以通过该数据集进行文本比较,探索不同文化背景下的圣经解读。
衍生相关工作
基于original-language-bibles-hebrew数据集,许多经典研究工作得以展开。例如,学者们利用该数据集进行了圣经文本的语义分析、词频统计以及跨语言对比研究。这些研究不仅深化了对圣经文本的理解,还为古代语言学和宗教学领域提供了宝贵的数据支持。
以上内容由遇见数据集搜集并总结生成


