tck-qa-benchmark-v2
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/hzfokyn/tck-qa-benchmark-v2
下载链接
链接失效反馈官方服务:
资源简介:
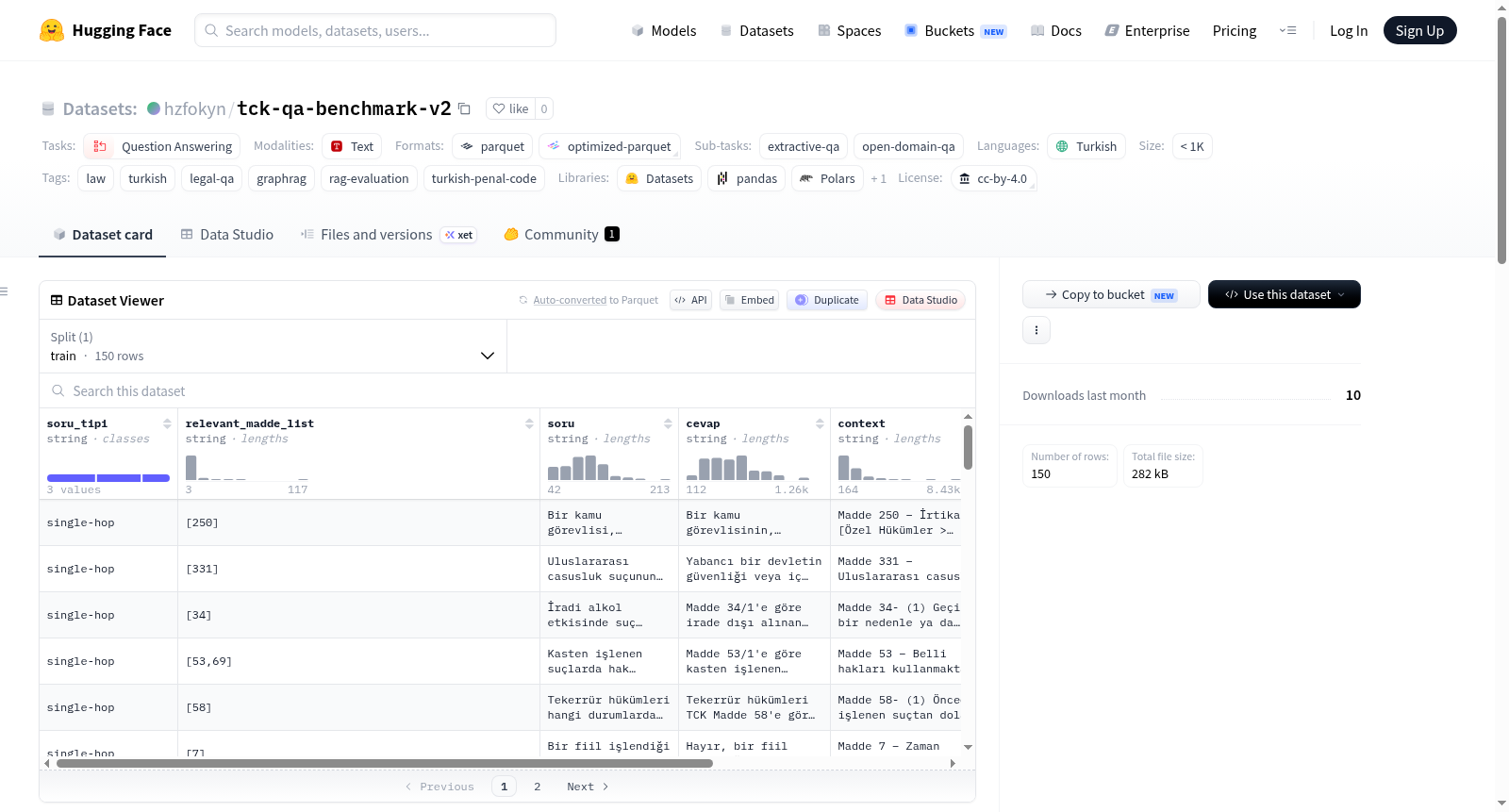
TCK 评估数据集 v2 是一个专门用于评估检索增强生成(RAG)系统在土耳其法律领域性能的基准数据集。该数据集基于《土耳其刑法典》(Türk Ceza Kanunu,简称 TCK)构建,包含 150 个土耳其语法律问题。数据集的核心设计目标是覆盖不同复杂程度的推理任务,问题被精心设计为三个难度级别:事实性单跳查询、涉及多个法条的多跳推理以及开放式的法律推理。每个数据样本包含多个结构化字段:土耳其语问题(`soru`)、带有法条引用(如 `[Madde 250]`)的参考答案(`cevap`)、标识问题类型(`single-hop`、`multi-hop` 或 `reasoning`)的字段(`soru_tipi`)、JSON 格式编码的相关法条编号列表(`relevant_madde_list`)、从 TCK 中提取的带有章节路径的黄金标准上下文片段(`context`)、相关 TCK 法条的完整文本(`tck_madde_metni`)以及固定的数据来源标识(`kaynak`,始终为 `Türk Ceza Kanunu`)。在 150 个问题中,单跳问题有 60 个,多跳问题有 55 个,推理问题有 35 个。该数据集适用于抽取式问答、开放域问答等任务,是评估法律领域 RAG 系统检索准确性、多步推理能力和法律理解深度的理想工具。
创建时间:
2026-05-19
原始信息汇总
TCK Evaluation Dataset v2 数据集概述
基本信息
- 数据集名称:TCK Evaluation Dataset v2
- 语言:土耳其语(tr)
- 许可证:CC-BY-4.0
- 数据集规模:小于1000条样本
- 任务类别:问答(抽取式问答、开放域问答)
- 标签:法律、土耳其语、法律问答、图检索增强生成、RAG评估、土耳其刑法典
数据集简介
该数据集是一个包含 150 个问题 的基准测试集,专门用于评估基于 土耳其刑法典(Türk Ceza Kanunu — TCK)的检索增强生成(RAG)系统。问题覆盖三种推理难度级别:事实性单跳查找、多条款多跳推理以及开放式法律推理。
数据字段说明
| 字段名 | 类型 | 描述 |
|---|---|---|
soru |
字符串 | 土耳其语问题 |
cevap |
字符串 | 参考答案(含条款引用,如 [Madde 250]) |
soru_tipi |
字符串 | 问题类型:single-hop(单跳)、multi-hop(多跳)、reasoning(推理) |
relevant_madde_list |
字符串 | JSON 编码的相关条款编号列表(如 "[250]") |
context |
字符串 | 土耳其刑法典中的黄金标准上下文片段(含章节路径) |
tck_madde_metni |
字符串 | 相关土耳其刑法典条款的全文 |
kaynak |
字符串 | 数据来源(固定为 Türk Ceza Kanunu) |
问题类型分布
| 问题类型 | 数量 | 描述 |
|---|---|---|
single-hop |
60 | 单一条款查找 |
multi-hop |
55 | 需连接多个条款进行推理 |
reasoning |
35 | 开放式法律推理 |
| 总计 | 150 |
使用示例
python from datasets import load_dataset
ds = load_dataset("hzfokyn/tck-qa-benchmark-v2", split="train") print(ds[0])
按问题类型筛选
single_hop = ds.filter(lambda x: x["soru_tipi"] == "single-hop")
引用方式
bibtex @misc{tck-evaluation-2026, author = {Huzeyfe Okuyan}, title = {TCK Evaluation Dataset}, year = {2026}, url = {https://huggingface.co/datasets/hzfokyn/tck-qa-benchmark-v2} }
搜集汇总
数据集介绍
构建方式
tck-qa-benchmark-v2数据集专为评估土耳其刑法典背景下的检索增强生成系统而设计,共包含150道精心构建的问答对。其构建逻辑遵循层次化难度递进原则,涵盖单一条文查明的单跳问题、需跨多条法条进行关联推理的多跳问题,以及考察开放式法律推理的复杂问题。每个样本均附有标准答案、相关法条编号、问题类型标签、黄金上下文节选及完整的法条原文,确保了评测的全面性与可复现性。
特点
该数据集的核心特色在于其三元难度体系与法律领域专业性。60题的单跳任务聚焦于事实性条文定位,55题的多跳场景挑战模型跨文档整合能力,35题推理型问题则要求对法律原则进行深度解析。所有问题均基于土耳其刑法典真实条文,答案以精确法条编号(如[Madde 250])为引用依据,兼具结构化与可解释性,为法律NLP系统的鲁棒性评估提供了标准化基准。
使用方法
数据集可通过HuggingFace Datasets库便捷加载,使用load_dataset('hzfokyn/tck-qa-benchmark-v2', split='train')即可获取。用户可按需求过滤子集,例如通过filter函数提取单跳类型样本进行专项测试。每个样本的soru_tipi字段支持按问题难度分类分析,context字段提供黄金标准上下文用于评估检索效果,tck_madde_metni字段则可直接作为生成式问答的参考材料。
背景与挑战
背景概述
在法律人工智能领域,特别是针对土耳其语的法律文本检索与问答系统评估,长期缺乏标准化的基准数据集。该数据集由Huzeyfe Okuyan于2026年创建,专注于土耳其刑法典(TCK),旨在为检索增强生成(RAG)系统提供精细化的评测工具。其核心研究问题在于评估模型在三种不同推理难度下的表现:事实性单跳查找、跨条款多跳推理以及开放性法律推理。这一基准填补了土耳其语法律NLP评估资源的空白,为后续法律智能系统的性能对比与研究提供了可复现的参照。
当前挑战
数据集主要挑战在于解决法律领域问答的固有复杂性:1)法律条文需精确引用,单跳问题虽只需单一条文,但多跳和推理题则需跨条款关联与逻辑推导,这对RAG系统的多步检索与推理能力构成严峻考验。2)构建过程中,150个问题需涵盖不同难度且确保法律准确性,人工设计每个问题的参考答案、相关条款及黄金上下文,严格校验法律一致性。3)语料为土耳其语,其形态丰富性及法律术语的特定表达增加了数据标注与模型评估的难度。
常用场景
经典使用场景
TCK-QA-Benchmark-v2 数据集专为评估基于土耳其刑法典(Türk Ceza Kanunu, TCK)的检索增强生成(RAG)系统而设计。其经典使用场景聚焦于法律领域的问答任务,涵盖事实性单跳查找、多条款多跳推理以及开放式法律推理三种难度层级。研究者可借助该基准测试,系统性地衡量 RAG 模型在法律文本检索与答案生成中的准确性、连贯性与推理能力,尤其适用于土耳其语法律资料的语义理解与知识应答场景。
解决学术问题
该数据集有效攻克了法律领域问答研究中面临的基准缺失与评估碎片化问题。它首次针对土耳其刑法典构建了标准化且带有细粒度难度分级的测试集,弥补了低资源语言在法律 RAG 评估中的空白。通过区分单跳、多跳与推理三类任务,研究者得以深入剖析模型在事实检索与法律逻辑推演中的具体短板,从而推动自然语言处理在法律文本理解与复杂问答场景下的理论进展。
衍生相关工作
依托该数据集,学术界与工业界已衍生出若干具有启发意义的工作。例如,研究者基于其多跳推理问题设计专用图谱检索策略,探索图索引结构(GraphRAG)在法律知识组织中的优势;另有工作围绕开放式推理任务开发评估指标,衡量模型生成答案与真实法律条文之间的语义对齐程度。此外,该数据集已被用作土耳其语法律语料库构建的前期基准,推动更多面向低资源语言的跨域司法问答研究。
以上内容由遇见数据集搜集并总结生成


