fineweb-oracle-convqa-chunked
收藏Hugging Face2026-05-12 更新2026-05-13 收录
下载链接:
https://huggingface.co/datasets/cds-jb/fineweb-oracle-convqa-chunked
下载链接
链接失效反馈官方服务:
资源简介:
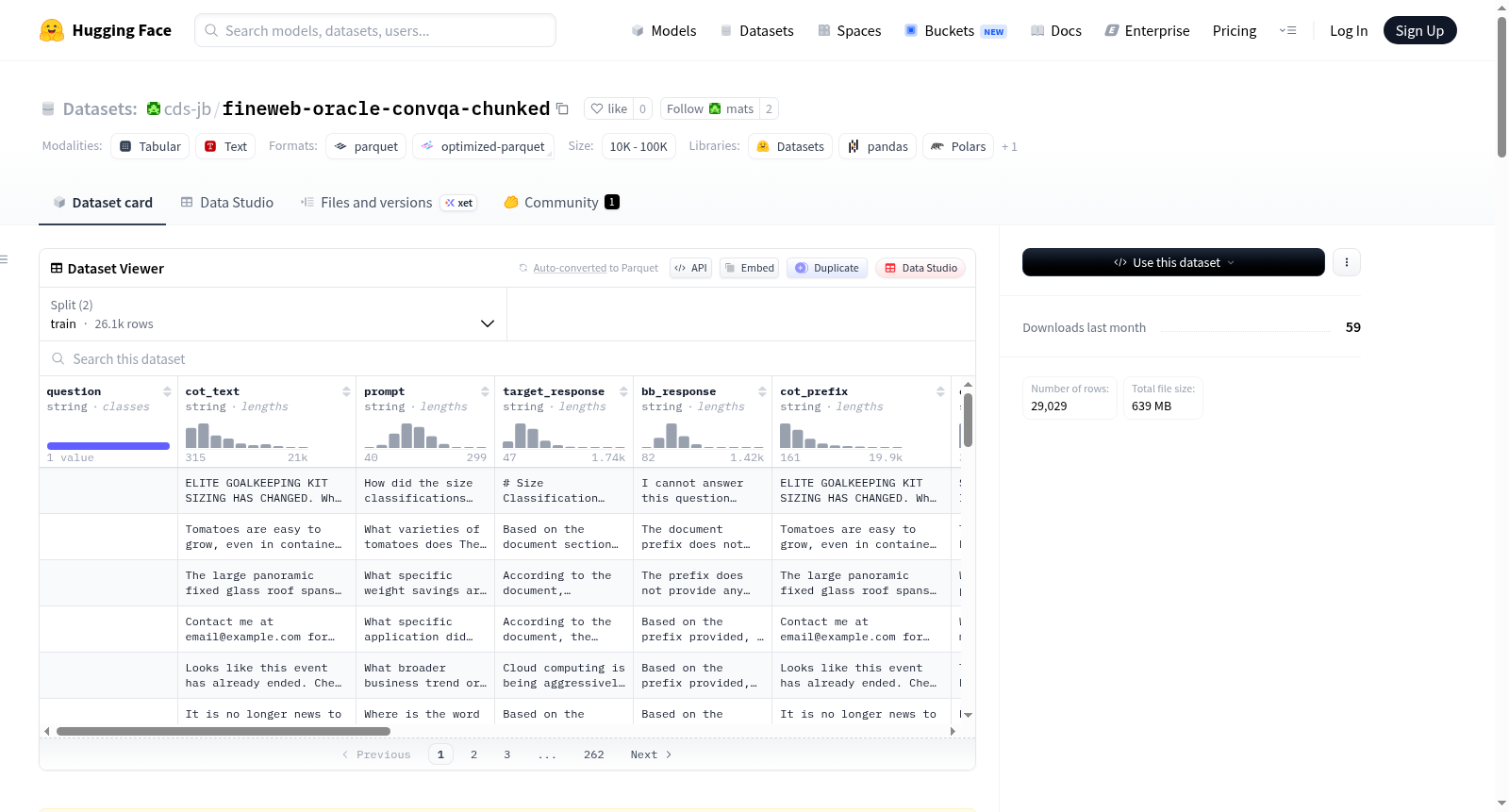
FineWeb Oracle: Chunked ConvQA是一个用于评估语言模型在信息缺口(oracle)场景下推理能力的对话式问答数据集。其核心任务是:给定一个长文档,模型需识别自然转折点将文档分割为前缀和后缀,然后生成一个关于后缀内容的问题(该问题无法仅从前缀推导出)。接着,基线模型(仅看到前缀)尝试回答问题,其答案将与真实答案(仅看到后缀生成的答案)进行比较和评分。数据集通过三阶段自动化流程生成,全程使用Anthropic Haiku 4.5模型:第一阶段模型阅读完整文档并生成问题;第二阶段模型基于前缀生成基线答案;第三阶段模型基于后缀生成真实答案,最后由同一模型进行评分。数据集包含29,029个样本,划分为训练集(26,123条)和测试集(2,906条),原始文档来源于FineWeb数据集并经过长度处理。每个样本包含完整文档文本、生成的问题、基线答案、真实答案、基线答案正确性判断(bb_correct)和细粒度匹配分数(bb_score),以及前缀、后缀、分割点索引、文档ID等信息。后续更新增加了target_response_distractor(与真实答案相似但事实错误的干扰项)和question_category(问题分类为“元认知”或“程序性”)。该数据集适用于语言模型推理评估、对抗性干扰项研究和问答生成任务。
FineWeb Oracle: Chunked ConvQA is a conversational question-answering dataset designed to evaluate the reasoning capabilities of language models in information gap (oracle) scenarios. The core task involves: given a long document, the model must first identify a natural turning point to split the document into a prefix and a suffix, then generate a question about the suffix content (which cannot be deduced from the prefix alone). Next, a baseline model (seeing only the prefix) attempts to answer the question, and its answer is compared and scored against the ground-truth answer (generated from the suffix). The dataset is generated through a three-stage automated pipeline using the Anthropic Haiku 4.5 model throughout: Stage 1 (Round 1) involves reading the full document, selecting a split point, and generating the question; Stage 2 (Round 2) generates the baseline answer based solely on the prefix; Stage 3 (Round 3) generates the ground-truth answer based solely on the suffix. Finally, the same model judges and scores the match between the baseline and ground-truth answers. It contains 29,029 samples, split into a training set (26,123 entries) and a test set (2,906 entries). The original document text is sourced from the FineWeb dataset and processed to match specific length distributions. Each sample includes the full document text, generated question, baseline answer, ground-truth answer, model-judged baseline answer correctness (binary judgment `bb_correct`), fine-grained matching score (`bb_score` on a 0.0 to 1.0 scale), as well as prefix, suffix, split point index, document ID, and other information. Subsequent updates added two key fields: `target_response_distractor` (a distractor similar to the ground-truth answer in length, structure, and vocabulary but with key factual errors) and `question_category` (classifying generated questions as metacognitive or procedural). The dataset is suitable for language model reasoning evaluation, adversarial distractor research, and question-answering generation tasks.
创建时间:
2026-05-08
搜集汇总
数据集介绍
构建方式
该数据集源自HuggingFaceFW/fineweb的sample-10BT配置,通过精心设计的文本长度匹配策略构建而成。具体而言,研究者首先提取FineWeb流式样本中长度最长的30%文档,并依据原始cot-oracle-convqa-chunked数据集中cot_text的经验长度累积分布函数(CDF),对每个保留文档进行句子级截断,以实现贪婪分位数匹配。随后,借助Anthropic Haiku 4.5模型的三轮交互式流程生成问答对:第一轮,模型通览全文后选择自然转折点并生成关于后缀内容的问题;第二轮,模型仅依据前缀尝试回答以建立基线(BB);第三轮,模型仅依据后缀给出真实答案(GT),并由同模型根据5分制评分标准对BB进行评判。
特点
数据集包含26123条训练样本与2906条测试样本,其核心特色在于引入了两类高难度干扰项。其一为target_response_distractor列,由Haiku 4.5在精确控制长度、结构及词汇风格的前提下,仅翻转一个实质性事实生成的语境感知型虚假答案,专用于更严苛的识别评估。其二为question_category列,将每个问题二分类为元认知型(涉及推理状态与过程)或程序型(涉及推理内容与事实),分类准确率达95%。此外,数据集保留了完整的推理链前缀与后缀、生成提示等丰富元信息,便于深入分析模型的信息缺口弥合能力。
使用方法
该数据集专为评估大型语言模型在信息不完备情境下的推理能力而设计。用户可直接加载默认配置中的train与test两个分片,利用prompt字段作为输入,target_response作为参考答案,bb_response作为基线模型输出。评估时可采用bb_correct二值标签或bb_score连续评分(范围0.0至1.0)进行量化分析。特别地,target_response_distractor字段可用于构建更具挑战性的负样本识别任务,而question_category字段支持按问题类型进行细粒度性能分析。数据集采用cot_id哈希值划分分片,确保同一文档的所有数据落在同一集合内,便于跨样本一致性分析。
背景与挑战
背景概述
在大语言模型推理能力评估领域,如何有效衡量模型在信息不完整条件下的推断表现一直是核心难题。FineWeb-Oracle-ConvQA-Chunked数据集由Anthropic研究团队于2026年基于HuggingFaceFW/fineweb语料库构建,旨在通过构建“信息缺口”(info-gap)场景,系统评估模型根据文本前缀预测后续关键内容的能力。该数据集以FineWeb的10亿样本子集为源,通过精心设计的管道提取文本内容,并利用Claude Haiku 4.5模型自动生成答案,开创了一种新颖的推理评估范式。其引入的“盲预测”(BB)与真值(GT)对比机制,为衡量模型在缺失上下文时的推理可靠度提供了量化标准,对推动语言模型鲁棒性和溯因推理研究具有重要价值。
当前挑战
该数据集主要面临两大挑战。其一,在领域问题层面,现有推理评测基准多聚焦于完整上下文下的逻辑推理,难以刻画模型在信息断层时的真实认知边界。本数据集通过设计“转折点”分割策略,强制模型仅依赖前缀信息填补后缀内容空缺,精准暴露了模型在长距离语义关联和事实推断上的脆弱性,实验显示盲预测正确率仅约5.2%,凸显评估难度。其二,在构建过程中,FineWeb文本长度分布与原始CoT语料存在差异,需通过分位数匹配和截断操作对齐,导致约1.5k字符的最大长度缺口;同时,对抗性干扰项(target_response_distractor)的生成需严格匹配长度、结构与词汇风格,并巧妙翻转单一事实,对生成模型的事实操控精度提出了苛刻要求。
常用场景
经典使用场景
在自然语言处理与可解释人工智能的交叉领域,FineWeb-Oracle-ConvQA-Chunked数据集为探究大型语言模型在信息不对等条件下的推理能力提供了独特的实验范式。该数据集的核心设计围绕一种“信息缺口”情境展开:模型仅能观察到文档的前缀部分,却需回答关于后缀内容的具体问题。经典使用场景为评估模型的“前瞻性归纳”能力,即仅凭前文线索推断后续信息,类似于人类在阅读不完整文本时进行的语义预测。研究者常利用此数据集来检验模型在缺失关键信息时能否仍保持逻辑连贯性,从而揭示其内部表征的完备性与鲁棒性。
实际应用
在实际应用层面,FineWeb-Oracle-ConvQA-Chunked数据集可服务于多种高风险场景中的模型诊断与安全审计。例如,在智能客服系统中,当用户问题涉及对话历史中被截断的细节时,该数据集可模拟并测试模型能否正确回忆并利用远端信息。在文档摘要与信息检索领域,它可用于评估模型在仅阅读文档前半部分时,能否准确回答涉及后半部分的提问,这对于实时处理流式长文本的应用程序尤为关键。此外,在法律与医疗文书审阅等对信息完整性要求严苛的行业,该数据集有助于识别模型在信息不全时产生“幻觉”的典型模式,从而指导研发更鲁棒的上下文编码机制,降低部署风险。
衍生相关工作
围绕FineWeb-Oracle-ConvQA-Chunked数据集,衍生了一系列旨在深化理解模型推理机制的代表性工作。其中,最具启发性的方向之一是“信息缺口归因分析”,研究者尝试解码模型在前缀阶段提取到的隐含线索,以及这些线索如何影响后续回答的置信度与正确率。另一类衍生工作聚焦于“对抗性干扰生成”,基于数据集中新增的`target_response_distractor`字段——一个长度与结构匹配但关键事实被翻转的选项——来构建更具挑战性的评估基准,迫使模型不仅要识别正确答案,还要抵御高度逼真的干扰项。此外,`question_category`字段的引入催生了区分“元认知型”与“程序型”问题的研究,揭示了模型在处理涉及自身推理状态的问题时与处理纯内容问题时的表现差异,为设计细粒度的推理能力诊断工具提供了新思路。
以上内容由遇见数据集搜集并总结生成


