counsel
收藏Hugging Face2026-01-23 更新2026-01-24 收录
下载链接:
https://huggingface.co/datasets/AtlaAI/counsel
下载链接
链接失效反馈官方服务:
资源简介:
Counsel是第一个提供人类对LLM-as-a-Judge(LLMJ)在代理任务执行上的批评进行元评估的数据集。它解决了LLMJ批评在诊断和改进代理系统中的关键缺口。数据集包含225个独特的代理执行轨迹,覆盖了两个广泛使用的真实世界代理基准:TauBench(零售)和DACode(代码生成和调试)。数据集还包括三个评判模型的过程级评判和相应的人类注释的元评判,用于评估评判模型批评的位置和推理质量。每个注释由三位具有10年以上数据科学和NLP经验的人类注释者标注,具有较高的内部一致性(Krippendorff’s alpha 0.78)。
Counsel is the first dataset that enables meta-evaluation of human critiques directed at LLM-as-a-Judge (LLMJ) during agent task execution. It addresses critical gaps in utilizing LLMJ critiques for diagnosing and improving agent systems. The dataset includes 225 unique agent execution trajectories, covering two widely used real-world agent benchmarks: TauBench (retail) and DACode (code generation and debugging). It also encompasses process-level judgments from three judge models, alongside corresponding human-annotated meta-judgments that assess the positioning and reasoning quality of these judge models’ critiques. Each annotation was completed by three human annotators with over 10 years of experience in data science and natural language processing (NLP), achieving strong inter-annotator agreement (Krippendorff’s alpha = 0.78).
创建时间:
2026-01-15
原始信息汇总
Counsel 数据集概述
数据集基本信息
- 数据集名称: Counsel
- 数据集地址: https://huggingface.co/datasets/AtlaAI/counsel
- 许可协议: MIT
- 主要语言: 英语
- 数据规模: n<1K
数据集构成与配置
数据集包含两个配置。
配置一:meta-annotations
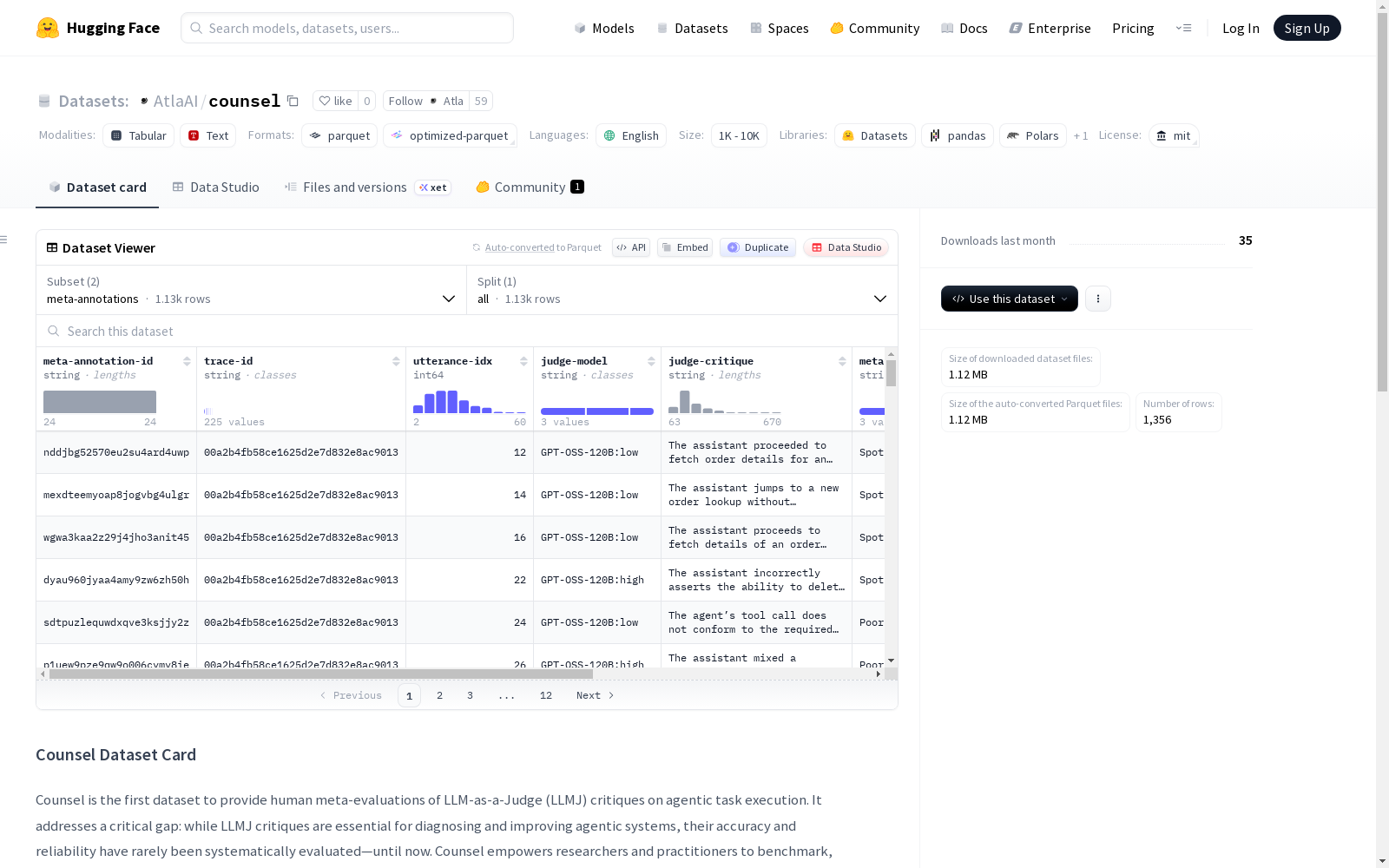
- 特征字段:
meta-annotation-id: 字符串类型trace-id: 字符串类型utterance-idx: 整数类型judge-model: 字符串类型judge-critique: 字符串类型meta-judgement: 字符串类型meta-comment: 字符串类型__index_level_0__: 整数类型
- 数据分割: 仅一个分割
all - 样本数量: 1131
- 数据集大小: 441537 字节
- 下载大小: 194509 字节
配置二:trajectories
- 特征字段:
trace-id: 字符串类型environment: 字符串类型agent-model: 字符串类型trajectory: 列表类型,包含复杂嵌套结构,详细描述了代理执行轨迹中的内容、完成原因、索引、消息、角色、工具调用以及可用工具等信息。
- 数据分割: 仅一个分割
all - 样本数量: 225
- 数据集大小: 5815490 字节
- 下载大小: 927831 字节
数据集详情与内容
Counsel 是首个提供对智能体任务执行中“LLM 作为评判者”批评进行人类元评估的数据集。
- 核心目标: 解决 LLM 评判批评的准确性和可靠性缺乏系统性评估的关键空白,使研究人员和从业者能够通过高质量、人类验证的注释来基准测试、改进和信任 LLM 评判批评。
- 数据来源: 包含 225 个独特的智能体执行轨迹,涵盖两个广泛使用的真实世界智能体基准:
- TauBench (零售): 一个客户支持数据集,包含 185 条轨迹。
- DACode: 一个代码生成和调试数据集,包含 40 条轨迹。
- 轨迹生成: 执行轨迹由两种具有不同推理风格的代理模型生成:GPT-OSS-20B(中等推理)和 Qwen3-235B-A22B-Instruct-2507(无推理)。
- 评估内容: 数据集包含三个评判模型(Qwen-3, GPT-OSS-2B:low 和 GPT-OSS-20B:high)在轨迹每个片段上的过程级评判,以及相应的人类注释元评判。评判者批评轨迹的每个片段,但只有被标记为存在错误的片段才会由人类进行元评判。
- 元评判类别: 元评判评估每个评判模型批评的位置和推理质量:
- Spot On: 错误位置和推理/批评均正确。
- Poor Reasoning but Right Location: 评判者正确识别了错误发生的位置,但提供了错误或不充分的推理来说明为何是错误。
- Should Not Have Flagged: 评判者错误地将此位置标记为包含错误(位置和推理均错误)。
- 附加信息: 注释者可以选择提供元评论。除元评估外,还提供完整的 225 条智能体轨迹。
数据标注质量
每个注释均由三位人类注释者标注,每位注释者都是拥有超过 10 年数据科学和 NLP 经验的熟练数据科学家,获得了较高的评分者间一致性(Krippendorff‘s alpha 0.78)。该数据集可用于改进评判者本身,帮助优化直接激励正确错误定位和忠实推理的目标。
搜集汇总
数据集介绍
构建方式
Counsel数据集的构建过程体现了对智能体系统评估的严谨追求。该数据集通过整合两个广泛使用的真实世界智能体基准——TauBench零售客户支持数据集和DACode代码生成与调试数据集,共收集了225条独特的智能体执行轨迹。这些轨迹由两种具有不同推理风格的智能体模型生成,随后由三个法官模型对轨迹的每个片段进行过程级评判。关键创新在于,仅当法官模型标记出错误片段时,才由经验丰富的人类标注员进行元评判,从而形成高质量的人类验证注释,确保了数据构建的精确性与效率。
使用方法
在人工智能与自然语言处理的研究实践中,Counsel数据集为评估和优化智能体系统提供了关键资源。研究人员可利用该数据集对法官模型的性能进行基准测试,分析其在错误定位与推理质量上的表现差异。具体而言,通过对比轨迹数据、法官批判与人类元评判,可以诊断法官模型的薄弱环节,进而设计更有效的训练目标以提升其评判的准确性与忠实性。该数据集支持对智能体任务执行的深入分析,是推动可靠智能体系统发展的重要工具。
背景与挑战
背景概述
在大型语言模型作为智能体执行复杂任务的时代,评估其决策过程的可靠性成为关键研究议题。Counsel数据集由相关研究团队于近期创建,旨在填补LLM-as-a-Judge(LLMJ)评估机制在智能体任务执行中缺乏系统性验证的空白。该数据集聚焦于对LLMJ生成的批判性评论进行人类元评估,通过收集真实世界智能体执行轨迹与多模型评判数据,为提升智能体系统的诊断精度与可信度提供了基准资源。其核心研究问题在于如何量化LLMJ批判的准确性与定位能力,从而推动智能体评估范式从单纯输出评判转向可解释、可验证的深度分析,对自动化评估与可信人工智能领域具有显著影响力。
当前挑战
Counsel数据集致力于解决智能体任务执行中自动化评估的可靠性挑战,即如何确保LLMJ生成的批判能够准确识别错误位置并提供合理推理。这一领域问题的难点在于平衡评估的自动化程度与人类判断的一致性,避免因模型偏见或推理缺陷导致误判。在构建过程中,挑战主要体现在数据标注的复杂性与一致性维护上:智能体轨迹涉及多步骤交互与工具调用,要求标注者具备深厚的领域知识以理解错误语境;同时,协调多位专家进行元评估标注,并达成高水平的标注者间一致性,需要精细的流程设计与质量控制,以确保数据集的权威性与可用性。
常用场景
经典使用场景
在大型语言模型作为评判者(LLMJ)的评估领域,Counsel数据集提供了人类元评估的宝贵资源。该数据集的核心应用场景在于系统性地评估LLMJ对智能体任务执行轨迹的批判质量,通过对比不同评判模型在错误定位与推理准确性上的表现,为研究者构建可靠的自动化评估框架奠定基础。其典型使用方式涉及分析智能体在零售客服与代码调试等真实任务中的执行轨迹,结合人类标注的元判断,深入探究评判模型在复杂决策过程中的有效性。
解决学术问题
Counsel数据集直接应对了智能体系统评估中评判模型可靠性验证的学术空白。传统上,LLMJ的批判往往缺乏人类标准参照,导致其诊断结果的可信度存疑。该数据集通过提供高质量的人类元评估标注,使得研究者能够量化评判模型在错误定位与推理逻辑上的准确率,从而推动评估指标的设计与优化。这一贡献不仅提升了智能体系统诊断的严谨性,也为自动化评估方法的可信验证提供了实证基础。
实际应用
在实际应用层面,Counsel数据集为开发更稳健的智能体系统提供了关键支持。工程团队可借助该数据集校准其内部评判模型,确保在客户服务、代码生成等场景中,系统能够准确识别并修正执行错误。例如,在零售客服自动化流程中,基于人类验证的评判标准可以帮助优化对话代理的决策逻辑,减少误判率,提升用户体验。这种以数据驱动的迭代方式,显著增强了智能体在复杂环境中的部署可靠性。
数据集最近研究
最新研究方向
在大型语言模型作为智能体评估工具(LLM-as-a-Judge)的快速发展背景下,Counsel数据集通过提供人类元评估标注,为评估LLM评判的准确性与可靠性开辟了新路径。该数据集聚焦于智能体任务执行轨迹的批判性分析,涵盖零售客服与代码生成等实际场景,其高质量的人类验证标注正推动着评估范式的革新。前沿研究借助Counsel探索如何优化评判模型的错误定位能力与推理忠实性,旨在提升智能体系统的诊断精度与可信度,这一进展对于构建稳健、可解释的自主智能体具有深远意义。
以上内容由遇见数据集搜集并总结生成


