cc12m-4mp
收藏Hugging Face2024-12-14 更新2024-12-15 收录
下载链接:
https://huggingface.co/datasets/opendiffusionai/cc12m-4mp
下载链接
链接失效反馈官方服务:
资源简介:
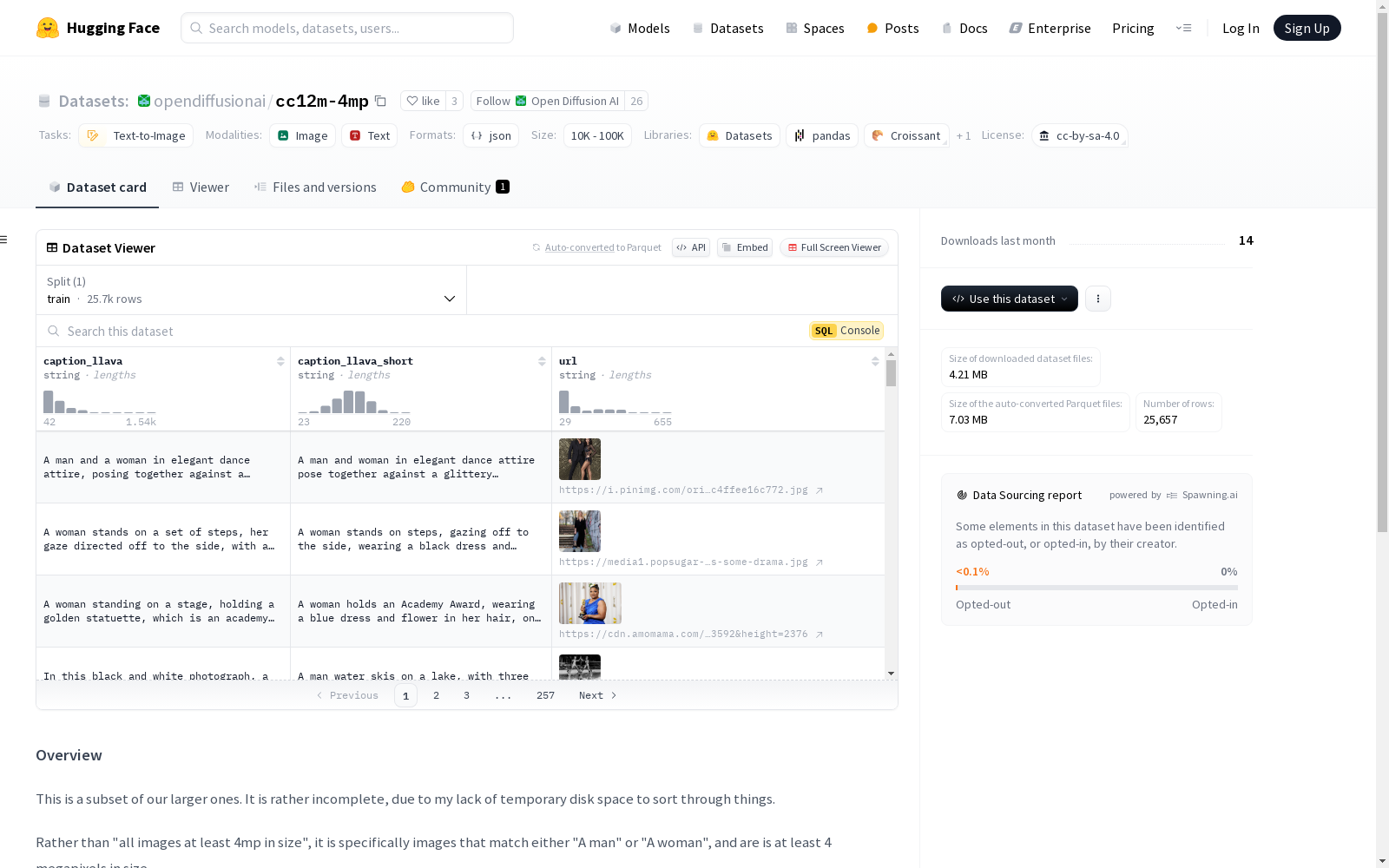
这是一个较大数据集的子集,包含约25,000张至少4百万像素的图像,主题为'一个男人'或'一个女人'。数据集并非完全去除水印,但至少来自经过初步清理的集合,而非原始的cc12m数据集。数据集还提供了两种风格的标题(长风格和短风格)。
This is a subset of a larger dataset, containing approximately 25,000 images with a resolution of at least 4 megapixels, themed around "a man" or "a woman". Watermarks are not fully removed from this dataset, which is sourced from at least a preliminarily cleaned collection rather than the original CC12M dataset. Two styles of captions (long-form and short-form) are also provided for this dataset.
创建时间:
2024-12-13
原始信息汇总
数据集概述
概览
- 数据集名称: cc12m-4mp
- 许可证: cc-by-sa-4.0
- 任务类别:
- text-to-image
- 数据集规模:
- 10K<n<100K
数据集描述
- 该数据集是较大数据集的一个子集。
- 数据集包含约25,000张图像,这些图像满足以下条件:
- 图像内容为“一个男人”或“一个女人”。
- 图像大小至少为4百万像素(4 megapixels)。
- 完整解析原始数据集可能会产生约60,000张图像。
- 数据集经过初步清理,但未完全去除水印。
- 数据集提供两种风格的标题:长风格和短风格。
下载
- 提供了
crawl.sh脚本,用于下载实际图像到本地计算机。 - 需要先获取
jsonl.gz文件。
Parquet格式
- 如果需要parquet格式,可以在以下路径找到自动转换的版本:
- https://huggingface.co/datasets/opendiffusionai/cc12m-4mp/tree/refs%2Fconvert%2Fparquet/default/train
搜集汇总
数据集介绍
构建方式
cc12m-4mp数据集是从一个更大的数据集中提取的子集,专门筛选出至少4百万像素的图像,且这些图像的主题限定为‘一个男人’或‘一个女人’。由于存储空间的限制,当前版本仅包含约25,000张图像,而完整解析原数据集可能产生约60,000张图像。尽管如此,该数据集仍提供了比完全缺失更好的选择。值得注意的是,该数据集并非完全去除水印,但相较于原始的cc12m数据集,已经进行了一定程度的清理。
特点
cc12m-4mp数据集的主要特点在于其图像的高分辨率特性,所有图像均至少为4百万像素,且主题明确,便于进行特定类型的图像分析或生成任务。此外,数据集提供了两种风格的标题选择,即长风格和短风格,增加了数据集的灵活性和适用性。尽管存在部分水印未完全去除的问题,但整体质量相较于原始数据集有所提升。
使用方法
使用cc12m-4mp数据集时,用户可以通过提供的‘crawl.sh’脚本轻松下载图像到本地计算机,前提是已经获取了jsonl.gz文件。用户可以根据需求编辑脚本以调整下载选项。此外,如果偏好parquet格式,用户可以在指定链接下找到自动转换的版本。该数据集适用于文本到图像的生成任务,尤其适合需要高分辨率图像和特定主题的应用场景。
背景与挑战
背景概述
cc12m-4mp数据集是基于更大规模数据集的一个子集,由主要研究人员或机构在资源有限的情况下创建。该数据集专注于文本到图像的任务,旨在提供高质量的图像数据,特别是针对描述‘一个男人’或‘一个女人’的图像,且这些图像的分辨率至少为4百万像素。尽管数据集的完整解析可能产生约60,000张图像,但由于存储空间的限制,当前版本仅包含约25,000张图像。尽管如此,该数据集的发布为研究者提供了一个初步的资源,特别是在图像质量和描述准确性方面,对文本到图像生成领域的研究具有重要意义。
当前挑战
cc12m-4mp数据集在构建过程中面临多项挑战。首先,由于存储空间的限制,数据集的完整性受到影响,未能包含所有符合条件的图像,这可能影响研究的全面性。其次,尽管数据集已经过初步清理,但仍存在部分图像带有水印的问题,这可能影响图像的可用性和分析结果的准确性。此外,数据集提供了长风格和短风格的描述文本,如何在不同风格间保持一致性和准确性也是一个需要解决的问题。最后,数据集的下载和使用过程中,用户需要自行处理和转换数据格式,这增加了使用的复杂性。
常用场景
经典使用场景
cc12m-4mp数据集主要用于文本到图像的生成任务,特别是在生成高质量、高分辨率的人像图像方面表现突出。由于数据集中的图像至少为4百万像素,且主要包含描述‘一个男人’或‘一个女人’的图像,因此它非常适合用于训练和评估能够生成逼真人像的模型。此外,数据集提供了长风格和短风格的描述,这为研究不同文本描述对图像生成效果的影响提供了丰富的资源。
解决学术问题
该数据集解决了在文本到图像生成领域中,如何生成高分辨率、高质量人像图像的学术问题。通过提供高像素的图像和多样化的文本描述,cc12m-4mp数据集为研究者提供了一个理想的平台,以探索和优化文本描述与图像生成之间的映射关系。这不仅推动了生成模型在图像质量上的提升,还为理解文本描述对图像生成的影响提供了重要的实验数据。
衍生相关工作
基于cc12m-4mp数据集,研究者们开发了多种文本到图像生成模型,这些模型在生成高质量人像图像方面表现优异。例如,一些研究工作利用该数据集训练了能够生成逼真人像的深度学习模型,这些模型在多个图像生成挑战赛中取得了显著的成绩。此外,还有研究探讨了如何利用数据集中的多样化文本描述来提升模型的生成多样性和准确性,这些工作为文本到图像生成领域的发展提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


