cc12m-4mp-realistic
收藏Hugging Face2024-12-16 更新2024-12-17 收录
下载链接:
https://huggingface.co/datasets/opendiffusionai/cc12m-4mp-realistic
下载链接
链接失效反馈官方服务:
资源简介:
这是CC12M数据集的一个子集,专注于高质量的真实世界4百万像素图像。这些图像带有长或短风格的描述。当前版本特别包含描述为'A man'或'A woman'的图像,且图像大小至少为4百万像素。数据集包含约25k张图像,经过筛选去除了杂志封面、海报、黑白图像、绘画、模糊图像、带水印图像、颗粒状图像、经过Photoshop处理的图像和电子游戏图像等。下载数据集可以通过'crawl.sh'脚本进行,也可以选择parquet格式。
This is a subset of the CC12M dataset, focusing on high-quality real-world 4-megapixel images. These images are paired with long or short descriptive captions. This specific version particularly includes images with captions reading "A man" or "A woman", and a minimum resolution of 4 megapixels. The dataset contains approximately 25,000 images, which have been filtered to remove magazine covers, posters, black-and-white images, paintings, blurry images, watermarked images, grainy images, Photoshop-edited images, and video game images, among others. The dataset can be downloaded via the 'crawl.sh' script, and is also available in Parquet format.
创建时间:
2024-12-13
原始信息汇总
数据集概述
概览
该数据集是CC12M数据集的一个子集,专注于高质量的现实世界图像,分辨率至少为4百万像素。数据集中的图像带有长或短风格的描述。目前,数据集仅包含与“一个男人”或“一个女人”匹配的图像,数量约为25,000张。完整的原始数据集解析可能会产生约60,000张图像。
过滤内容
已排除的图像类型包括但不限于:
- 杂志封面
- 海报
- 黑白图像
- 绘画
- 模糊图像
- 带有水印的图像
- 颗粒状图像
- 经过Photoshop处理的图像
- 电子游戏图像
此外,任何可能混淆训练的图像也被排除。最终筛选后,可能仍有少量图像因人为错误而包含在内,但预计不超过1%。
下载
可以通过“crawl.sh”脚本轻松下载实际图像到本地计算机,前提是您已经拥有jsonl.gz文件。可以编辑脚本来调整各种选项。
Parquet格式
如果需要parquet格式,可以在以下位置找到自动转换的版本: https://huggingface.co/datasets/opendiffusionai/cc12m-4mp-realistic/tree/refs%2Fconvert%2Fparquet/default/train
搜集汇总
数据集介绍
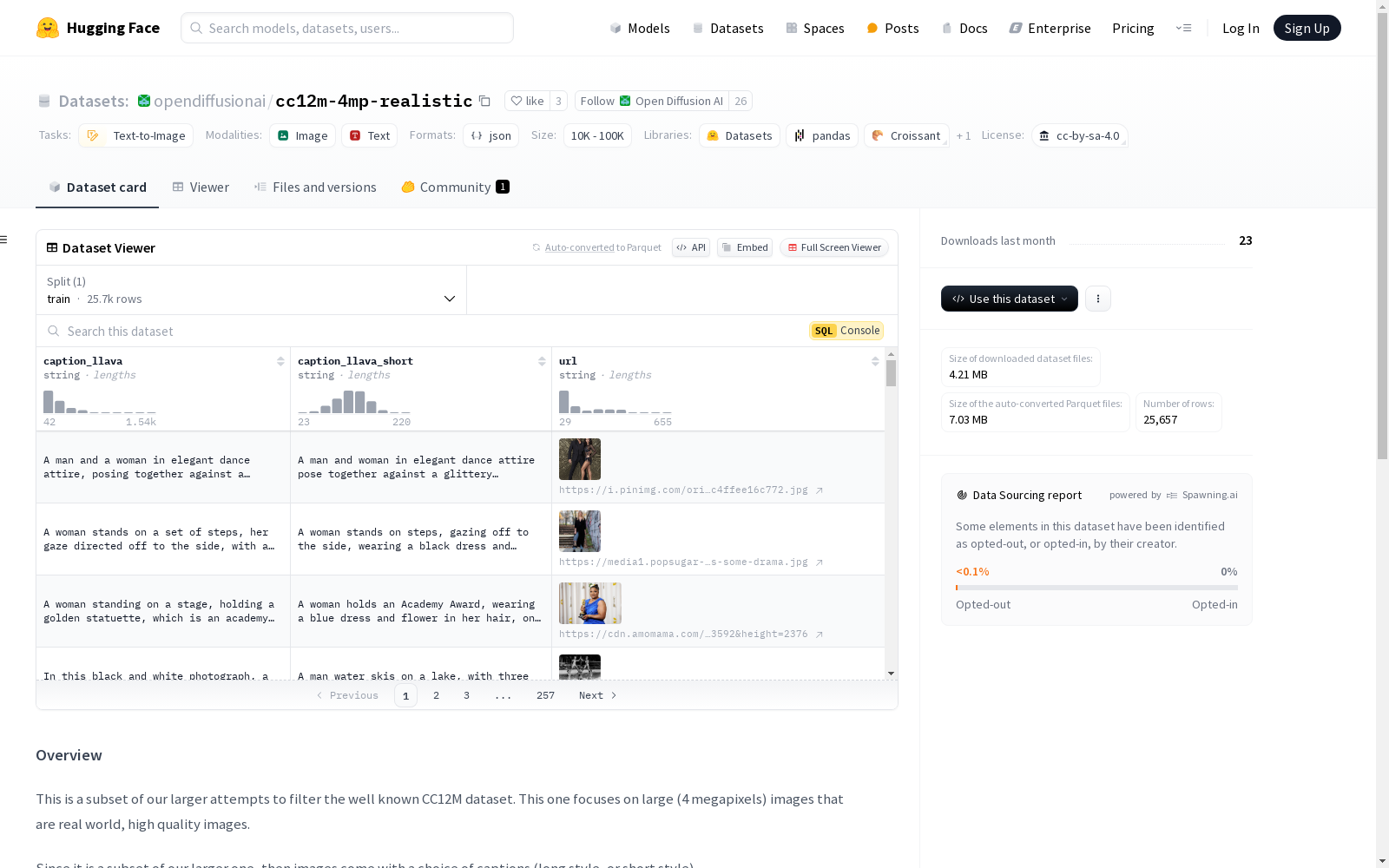
构建方式
cc12m-4mp-realistic数据集是从著名的CC12M数据集中筛选出的一个子集,专注于包含高质量、真实世界的4百万像素图像。该数据集的构建过程涉及对原始数据集的严格筛选,确保图像符合特定的标准,如图像大小至少为4百万像素,并且内容主要集中在描述‘一个男人’或‘一个女人’的场景。此外,数据集还提供了长风格和短风格的描述文本,以丰富图像的语义信息。在筛选过程中,剔除了诸如杂志封面、海报、黑白图像、模糊图像、水印图像、颗粒状图像、经过Photoshop处理的图像以及视频游戏图像等不符合要求的类型,以确保数据集的高质量和一致性。
特点
cc12m-4mp-realistic数据集的主要特点在于其高质量的图像和明确的主题定位。所有图像均为4百万像素以上的高分辨率,且内容聚焦于真实世界的场景,特别是关于‘一个男人’或‘一个女人’的描述。数据集提供了两种风格的描述文本,即长风格和短风格,以满足不同应用场景的需求。此外,数据集经过严格的筛选,剔除了多种不符合要求的图像类型,确保了数据集的纯净性和适用性。尽管当前数据集仅包含约25,000张图像,但其高质量和明确的主题定位使其在文本到图像生成任务中具有显著的优势。
使用方法
cc12m-4mp-realistic数据集适用于文本到图像生成任务,用户可以通过提供的‘crawl.sh’脚本轻松下载图像到本地计算机,并结合jsonl.gz文件进行使用。该脚本允许用户根据需要调整下载选项,以满足不同的应用需求。此外,数据集还提供了Parquet格式的版本,用户可以通过访问指定链接获取该格式的数据文件。在使用过程中,用户可以根据任务需求选择合适的描述文本风格,如长风格或短风格,以优化模型的训练效果。总体而言,该数据集的高质量和明确的主题定位使其在文本到图像生成任务中具有广泛的应用潜力。
背景与挑战
背景概述
cc12m-4mp-realistic数据集是基于广泛使用的CC12M数据集的一个精选子集,由OpenDiffusionAI团队创建。该数据集专注于包含高质量、真实世界的4百万像素图像,旨在为文本到图像的任务提供更精确的数据支持。数据集的构建时间可追溯至近期,主要研究人员或机构为OpenDiffusionAI,其核心研究问题在于如何通过筛选和优化现有大规模数据集,提升文本到图像生成模型的性能。该数据集的推出对图像生成领域具有重要影响,特别是在提高生成图像的分辨率和真实性方面,为相关研究提供了新的基准。
当前挑战
cc12m-4mp-realistic数据集在构建过程中面临多项挑战。首先,筛选高质量、真实世界的4百万像素图像需要耗费大量计算资源和时间,尤其是在处理大规模数据集时。其次,去除不符合要求的图像类型,如杂志封面、海报、黑白图像等,增加了数据清洗的复杂性。此外,数据集的规模限制在25k图像,相比原始数据集的潜在60k图像,可能限制了其在某些应用中的广泛适用性。最后,尽管进行了严格的筛选,仍可能存在少量的误分类图像,这可能对模型的训练产生微妙的影响。
常用场景
经典使用场景
cc12m-4mp-realistic数据集在文本到图像生成任务中展现了其独特的价值。该数据集专注于高质量、真实世界的4百万像素图像,特别适用于需要高分辨率图像的生成模型训练。其图像与长或短风格的文本描述相结合,为模型提供了丰富的语义信息,从而在生成逼真图像方面表现出色。
衍生相关工作
基于cc12m-4mp-realistic数据集,研究者们开发了多种先进的文本到图像生成模型,这些模型在图像质量和语义理解方面取得了显著进展。此外,该数据集还激发了在图像生成领域的多模态学习研究,推动了跨模态信息融合技术的进步,为未来的研究提供了丰富的实验基础和理论支持。
数据集最近研究
最新研究方向
在文本到图像生成领域,cc12m-4mp-realistic数据集因其专注于高质量、真实世界的4百万像素图像而备受关注。该数据集通过筛选和优化,剔除了如杂志封面、黑白图像、低质量图片等干扰因素,确保了数据集的纯净性和实用性。当前的研究方向主要集中在利用该数据集提升文本到图像生成模型的准确性和逼真度,尤其是在处理复杂场景和多样化人物描述时。此外,该数据集的精简版本也为资源受限的研究者提供了宝贵的实验材料,推动了相关技术的普及与应用。
以上内容由遇见数据集搜集并总结生成


