kenya-court-submissions-qa
收藏Hugging Face2025-10-29 更新2025-10-30 收录
下载链接:
https://huggingface.co/datasets/esherialabs/kenya-court-submissions-qa
下载链接
链接失效反馈官方服务:
资源简介:
肯尼亚法庭提交问答数据集,包含15,000个针对肯尼亚高等法院、上诉法院和最高法院的问答对,用于训练模型起草法庭所需的文件。每个答案都遵循BLUF(Bottom Line Up Front)的结构:BLUF → Governing Rules → Controlling Holdings → Application → Relief Sought。
创建时间:
2025-10-21
原始信息汇总
Kenya Court Submissions Q/A 数据集概述
基本信息
- 数据集名称: Kenya Court Submissions Q/A (HC/CA/SC) — Esheria
- 许可证: cc-by-nc-4.0
- 任务类别: 文本生成、问答
- 语言: 英语
- 标签: 法律提交、法律援助、肯尼亚、法律、文本到文本生成、司法访问
数据集规模与结构
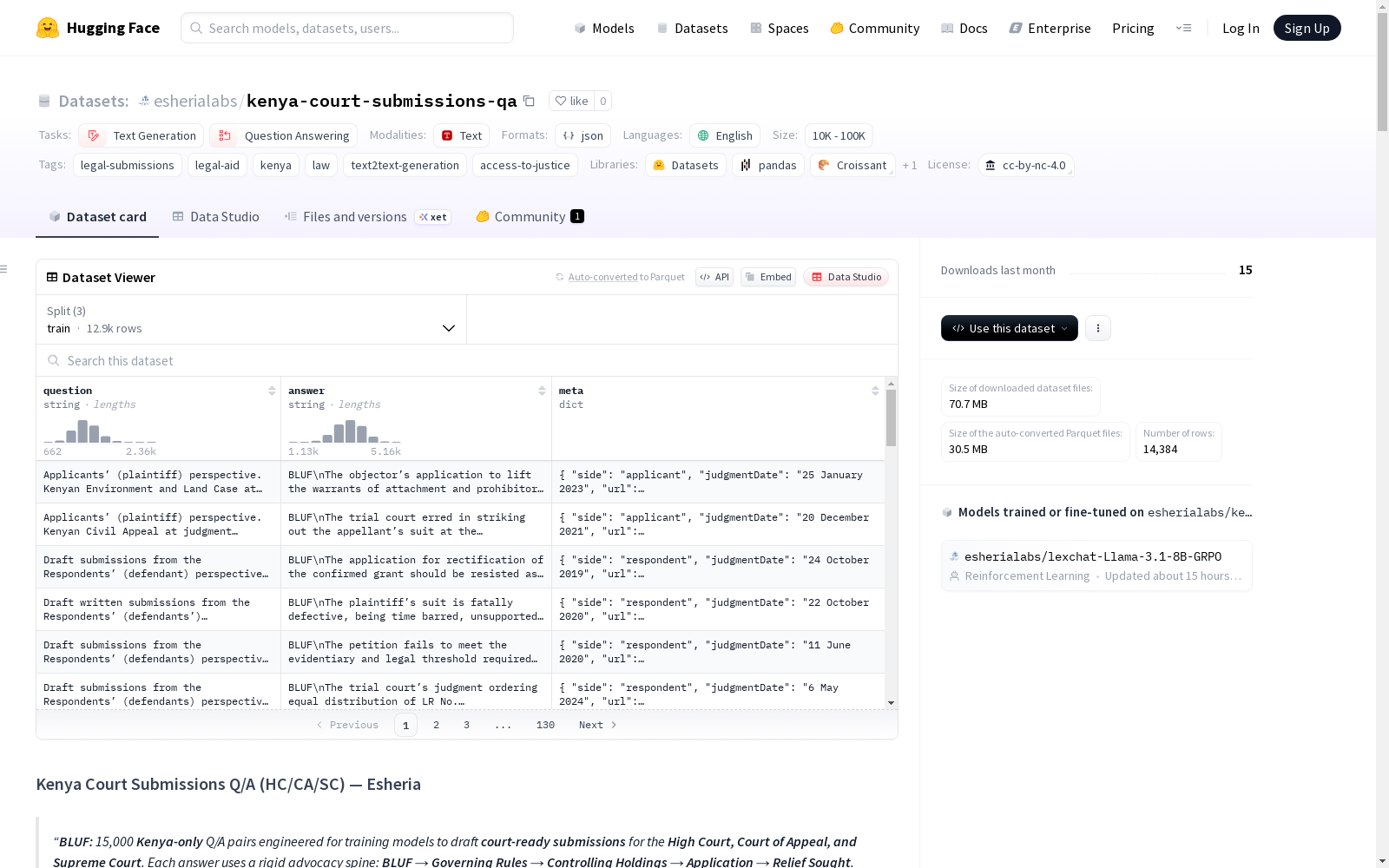
- 数据量: 15,000个问答对
- 格式: JSONL(每行一个JSON对象)
- 模式: {"question": str, "answer": str}
- 文件结构:
- train.jsonl(约90%)
- val.jsonl(约5%)
- test.jsonl(约5%)
核心特征
- 管辖范围: 肯尼亚(仅限高等法院、上诉法院和最高法院)
- 准备状态: 可直接用于监督微调,无额外键值,长格式答案(目标350-900词)
- 辩护结构: BLUF → 管辖规则 → 控制性判决 → 应用 → 寻求救济
- 立场平衡: 在申请人/原告/抗议者与被告/答辩人之间平衡(包括上诉中的上诉人/被上诉人)
法律领域覆盖
- 土地与财产法
- 行政法
- 商业与公司法
- 宪法
- 民事诉讼程序
- 就业与劳动法
- 侵权法
- 家庭与儿童法
- 税法
- 刑法
- 环境法
- 银行与金融法
- 知识产权法
- 选举请愿
质量保证措施
- 模式有效性验证
- 章节结构正则验证
- 词数范围控制
- 管辖纯度检查
- 去重处理
- 立场一致性检验
使用限制
- 不包含URL或精确引用
- 非案例数据库,仅为问答辩护数据集
- 范围限定:仅肯尼亚,高等法院及以上级别
合规与伦理
- 数据来源:肯尼亚法律资源和精选辩护模式
- 用户需遵守《肯尼亚数据保护法(2019)》
- 不构成法律建议,输出需经合格从业者审查
推荐训练配置
- 模型: Llama-3.1-8B-Instruct或相当模型
- 方法: QLoRA SFT →(可选)DPO/ORPO →(可选)带结构和管辖奖励的GRPO
- 最大序列长度: 约1,536个token
- 训练周期: 2-3个周期
版本信息
- 当前版本: v1.0.0(初始版本)
- 计划版本:
- v1.1.0:添加结构化元数据
- v1.2.0:可选引用感知变体
引用方式
Esheria (2025). Kenya Court Submissions Q/A (HC/CA/SC). Hugging Face Datasets. https://huggingface.co/datasets/esheria/kenya-court-submissions-qa
搜集汇总
数据集介绍
构建方式
在肯尼亚司法体系背景下,该数据集通过系统化采集高级法院、上诉法院及最高法院的诉讼文书构建而成。构建过程严格遵循五段式论证框架(BLUF→法律依据→判例援引→法律适用→救济请求),每条数据均经过管辖权验证和格式标准化处理,确保内容符合肯尼亚司法实践规范。数据源经过专业法律团队筛选,采用去标识化技术保护隐私,并通过模糊相似度算法进行去重优化。
特点
本数据集最显著的特征在于其严格的司法专业性,所有问答对均采用肯尼亚本土法律术语与判例体系。数据内容覆盖土地产权、宪法诉讼、商业纠纷等15个专业领域,且保持原被告双方视角的平衡性。每条答案均遵循固定论证结构,摒弃法律文书常见的冗余表述,确保模型输出的内容可直接应用于法庭陈述。数据集特别强调本土法源的优先性,仅在必要时辅以域外法理作为补充论证。
使用方法
使用者可通过Hugging Face标准接口加载数据集,建议采用指令微调技术进行模型训练。训练时应配置系统提示词明确肯尼亚司法场景需求,输入序列长度建议控制在1536个标记以内。对于模型输出,需通过正则表达式验证五段式结构完整性,并利用启发式规则检测论证立场的一致性。该数据集适用于法律文书自动生成系统的开发,但输出内容必须经执业律师审核方可投入实际应用。
背景与挑战
背景概述
随着人工智能技术在法律领域的深入应用,专门针对司法文书生成的数据集逐渐成为研究热点。Kenya Court Submissions Q/A数据集由Esheria团队于2025年发布,聚焦肯尼亚高等法院、上诉法院及最高法院的司法文书自动生成任务。该数据集包含1.5万组问答对,采用严格的五段式论证结构(核心主张→法律依据→判例援引→事实适用→救济请求),旨在解决传统法律数据集存在的法域错配与论证逻辑松散等问题。其创新性体现在将法律专业知识转化为可计算的结构化范式,为肯尼亚司法系统提供了标准化的人工智能辅助工具。
当前挑战
构建过程面临双重挑战:在领域问题层面,需克服法律文本的强领域依赖性,要求模型精准掌握肯尼亚特定法条与判例体系,同时保持论证逻辑的严密性与司法文书的规范性;在技术实现层面,数据集构建需平衡专业性与普适性,既要确保五段式论证结构的严格遵循,又要避免模型陷入模板化输出的困境。此外,数据标注需要法律专家深度参与,在保持论证密度的同时控制文本长度,这对质量评估体系的设计提出了更高要求。
常用场景
经典使用场景
在肯尼亚司法体系中,该数据集专为训练法律文本生成模型而设计,聚焦于高等法院、上诉法院及最高法院的诉讼文书起草。其核心应用场景在于模拟律师撰写法庭陈述的完整流程,要求模型严格遵循BLUF(核心论点)→管辖规则→判例引用→法律适用→救济请求的五段式论证结构。这种设计确保了生成内容不仅符合肯尼亚司法文书规范,更能直接应用于实际诉讼场景的文书准备工作。
实际应用
在法律科技实践中,该数据集支撑的开发成果可直接服务于肯尼亚律师事务所的日常工作。通过训练后的模型,律师能够快速生成符合法院要求的诉讼文书初稿,显著提升土地纠纷、行政诉讼、商业合同等典型案件的材料准备效率。这种技术应用不仅降低了法律服务的门槛,更通过标准化文书格式确保了司法程序的规范性与专业性。
衍生相关工作
基于该数据集衍生的经典研究包括结合检索增强生成技术的法律文书辅助系统,这类系统通过引入判例数据库来验证生成内容的法条引用准确性。同时,该数据集也催生了针对肯尼亚法律特色的指令微调方法研究,特别是在处理多标签法律分类任务时,如何保持论证结构与法域特性的一致性成为后续工作的重点突破方向。
以上内容由遇见数据集搜集并总结生成


