nemotron-gym-safety
收藏Hugging Face2026-05-16 更新2026-05-17 收录
下载链接:
https://huggingface.co/datasets/laion/nemotron-gym-safety
下载链接
链接失效反馈官方服务:
资源简介:
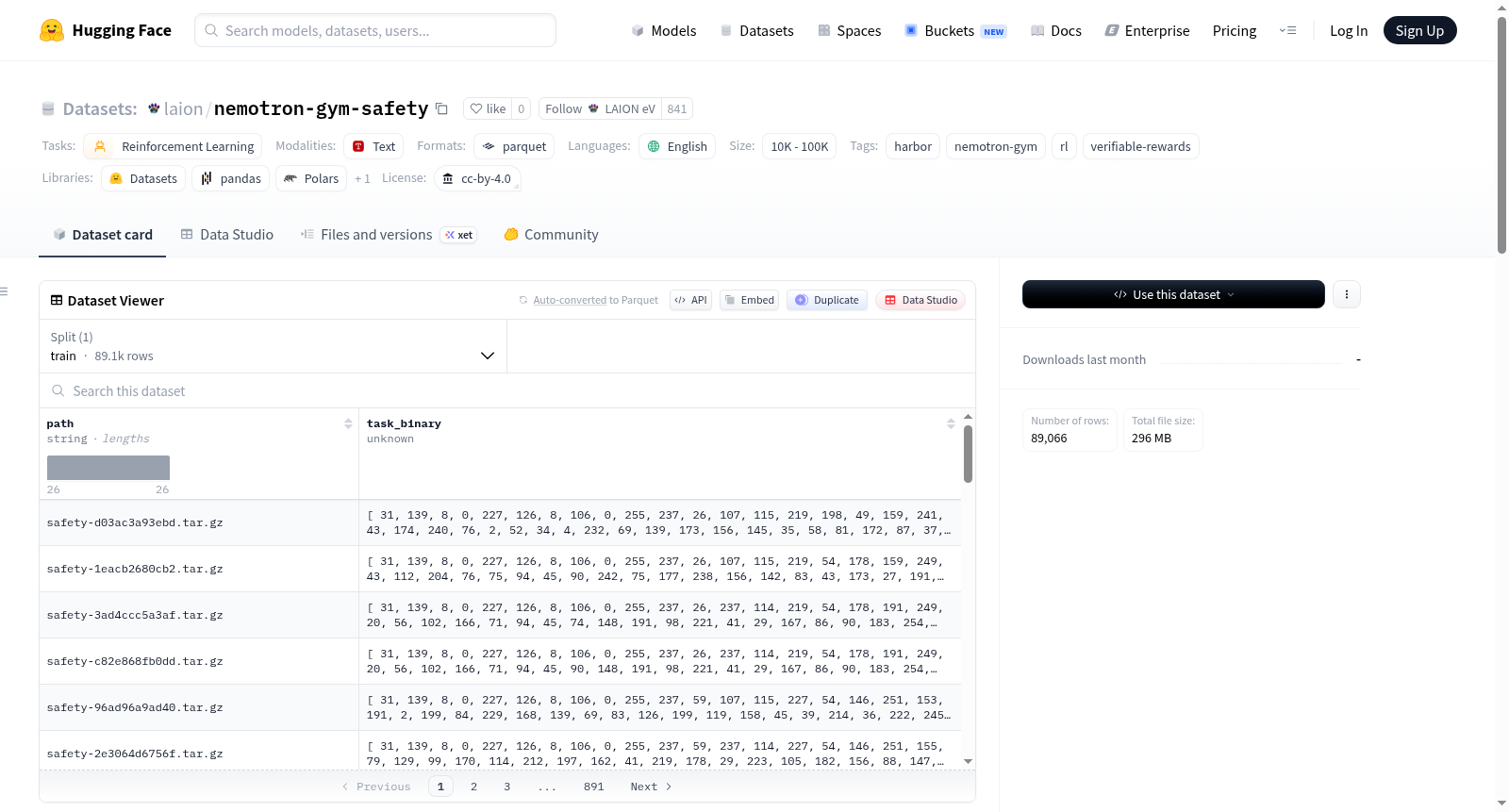
该数据集是nvidia/Nemotron-RL-Safety-v1的Harbor格式转换版本,属于NVIDIA NeMo-Gym集合的一部分,专为强化学习任务设计,特别关注安全性验证。每个数据行包含两个字段:path(确定性短ID,格式为<family>-<sha256[:12]>.tar.gz)和task_binary(包含完整Harbor任务的gzip压缩tar文件)。任务内容遵循Harbor标准布局,包括:instruction.md(展示给智能体的提示)、environment/Dockerfile(基于python:3.11-slim-bookworm并添加任务特定依赖)、tests/test.sh(验证器入口点)、tests/verifier.py(验证器实现)、tests/verifier_data.json(每个任务的验证器输入数据,JSON格式)、metadata.json(来源信息:源数据集、行索引、家族等)和task.toml(标准Harbor任务配置,包含CPU/内存/超时默认值)。转换过程采用安全构建原则:数据集内容不会插入到shell、Python或Dockerfile源代码中,所有值通过tests/verifier_data.json(JSON格式,运行时解析)传递;基础镜像名称固定;文本字段去除控制字符;tarball路径经过遍历/NUL/绝对路径攻击验证;tarball具有确定性(排序条目、mtime=0、uid/gid=0),确保可复现性。验证器家族为llm_judge,使用LiteLLM和默认的openai/gpt-4o-mini模型,根据原则性评分标准进行评分。数据集适用于强化学习、安全验证和智能体评估任务。
This dataset is a Harbor format conversion version of nvidia/Nemotron-RL-Safety-v1, part of the NVIDIA NeMo-Gym collection. It is designed for reinforcement learning tasks with a focus on safety verification. Each data row contains two fields: path (a deterministic short ID in the format <family>-<sha256[:12]>.tar.gz) and task_binary (a gzip-compressed tar file containing the complete Harbor task). Task content follows the Harbor standard layout, including: instruction.md (prompt shown to the agent), environment/Dockerfile (based on python:3.11-slim-bookworm with task-specific dependencies added), tests/test.sh (verifier entry point), tests/verifier.py (verifier implementation), tests/verifier_data.json (verifier input data for each task, in JSON format), metadata.json (source information: original dataset, row index, family, etc.), and task.toml (standard Harbor task configuration with CPU/memory/timeout defaults). The conversion process employs secure build principles: dataset content is not inserted into shell, Python, or Dockerfile source code; all values are passed via tests/verifier_data.json (JSON format, parsed at runtime); base image name is fixed; text fields have control characters removed; tarball paths are validated against traversal/NUL/absolute path attacks; tarballs are deterministic (sorted entries, mtime=0, uid/gid=0), ensuring reproducibility. The verifier family is llm_judge, using LiteLLM and the default openai/gpt-4o-mini model for scoring based on principled criteria. The dataset is suitable for reinforcement learning, safety verification, and agent evaluation tasks.
提供机构:
LAION eV创建时间:
2026-05-16
原始信息汇总
数据集概述:laion/nemotron-gym-safety
核心信息
该数据集是 nvidia/Nemotron-RL-Safety-v1 的 Harbor 格式转换版本,专注于强化学习(RL)中的可验证奖励(verifiable rewards)场景,提供安全相关的训练任务。
标识与规模
- 许可证:CC-BY-4.0
- 任务类别:强化学习(reinforcement-learning)
- 语言:英语(en)
- 样本数量:10K < n < 100K(数万级别)
数据格式与结构
每行样本包含两个字段:
| 字段 | 类型 | 描述 |
|---|---|---|
path |
string | 确定性短ID(格式:<family>-<sha256[:12]>.tar.gz) |
task_binary |
binary | 压缩的 tar 包(gzip),包含完整的 Harbor 任务 |
Tar 包内部结构(遵循 Harbor 任务布局):
instruction.md:向智能体展示的提示(prompt)environment/Dockerfile:基础镜像为python:3.11-slim-bookworm,包含任务特定的 pip 依赖tests/test.sh:验证器入口,将结果写入/logs/verifier/reward.txttests/verifier.py:验证器实现(内嵌、确定性)tests/verifier_data.json:任务特定的验证器输入(JSON 格式,无代码插值)metadata.json:来源信息(source_dataset、row_index、family 等)task.toml:标准 Harbor 任务配置(CPU、内存、超时默认值)
验证机制
- 验证器系列:
llm_judge(基于 LiteLLM,默认模型为openai/gpt-4o-mini,按照principle准则评分) - 安全性设计:
- 数据集内容永不插值到 shell、Python 或 Dockerfile 中;所有数据通过
tests/verifier_data.json在运行时解析 - 基础镜像名称固定(
python:3.11-slim-bookworm);pip 规格经过严格白名单正则验证 - 文本字段已清除 C0/C1 控制字符,长度受限,tar 包路径经过遍历/NUL/绝对路径攻击验证
- Tar 包是确定性的(排序条目、
mtime=0、uid/gid=0),保证字节可重复
- 数据集内容永不插值到 shell、Python 或 Dockerfile 中;所有数据通过
使用方式
加载数据(Python): python from datasets import load_dataset ds = load_dataset("laion/nemotron-gym-safety", split="train") print(ds[0]["path"], len(ds[0]["task_binary"]))
运行单个任务(命令行): bash python - <<PY import gzip, io, tarfile from datasets import load_dataset ds = load_dataset("laion/nemotron-gym-safety", split="train") row = ds[0] with tarfile.open(fileobj=io.BytesIO(row["task_binary"]), mode="r:gz") as tar: tar.extractall("/tmp/safety-task") PY harbor run -t /tmp/safety-task -e daytona # 或 -e docker
来源与衍生
- 原始数据集:nvidia/Nemotron-RL-Safety-v1(NVIDIA 的 NeMo-Gym 合集 的一部分)
- 转换工具:由 OpenThoughts-Agent 中的
data/nemotron_gym适配器生成,转换过程保证安全性(secure-by-construction)
搜集汇总
数据集介绍
构建方式
nemotron-gym-safety数据集是基于nvidia/Nemotron-RL-Safety-v1的Harbor格式转换产物,由OpenThoughts-Agent项目中的数据适配器生成。在构建过程中,每一条数据被封装为包含确定性短ID的gziptar包,其内部严格遵循Harbor任务布局,涵盖指令文件(instruction.md)、基于python:3.11-slim-bookworm的环境配置、验证器脚本(verifier.py)及其数据文件(verifier_data.json),以及元数据和任务配置文件。转换设计秉持安全优先原则:所有数据仅通过JSON文件传递,避免与脚本或Dockerfile内容直接插值;基础镜像名称固定,pip依赖经过严格正则白名单验证;文本字段经过去除控制字符和长度限制处理,同时确保tarball路径无遍历或绝对路径风险。生成的tarball具备确定性,即通过排序条目、设置时间戳和用户组为零实现字节级可复现。
使用方法
使用nemotron-gym-safety数据集时,用户可通过HuggingFace Datasets库直接加载,利用load_dataset函数获取训练集,每条数据包含‘path’字符串和‘task_binary’二进制字段。对于单任务运行,可将task_binary中的gziptar包解压至指定目录,随后借助Harbor工具执行任务,支持daytona或docker等执行引擎。具体操作上,先用Python标准库的gzip和tarfile模块将二进制数据还原为文件,再通过harbor run命令指定任务路径和环境类型即可启动验证。该流程设计简洁,从数据获取到任务执行的衔接自然流畅,降低了研究者在RL安全验证场景中应用数据集的复杂度。
背景与挑战
背景概述
在大规模强化学习与语言模型对齐的交汇领域,可靠且安全的奖励信号是驱动智能体行为优化的核心瓶颈。为回应这一需求,NVIDIA研究团队于2024年推出了Nemotron-RL-Safety-v1数据集,并由LAION社区将其转化为标准化的Harbor格式,形成了nemotron-gym-safety数据集。该数据集由NVIDIA的NeMo-Gym项目衍生,专注于为强化学习提供基于可验证奖励的对抗性安全评估场景,其设计强调安全约束与可复现性。通过采用LiteLLM框架与大语言模型判分器,该数据集能够自动化评估智能体在复杂安全原则下的表现,对推动安全对齐研究、提升强化学习系统的鲁棒性具有重要影响。
当前挑战
该数据集面临的挑战集中于双重层面。首先,在领域问题层面,它旨在解决强化学习中奖励稀疏与安全性难以量化评估的困境,尤其是在对抗性环境下如何通过可验证奖励信号引导模型回避有害行为。其次,在构建过程中,数据集严格规避了内容注入攻击风险,确保指令和验证器数据仅通过JSON文件传递,不直接嵌入到Python或Shell脚本中;同时,其验证器依赖外部大语言模型判分器(如GPT-4o-mini),这引入了第三方模型输出不确定性及可复现性难题。此外,数据集的Harbor格式转换要求对Docker镜像、文件路径和文本字段进行层层安全过滤,增加了维护与扩展的复杂性。
常用场景
经典使用场景
在强化学习与安全对齐的交汇领域,nemotron-gym-safety数据集为训练与评估语言模型的安全行为提供了标准化环境。该数据集将NVIDIA构建的Nemotron-RL-Safety-v1原始数据转换为Harbor格式,每个样本封装为一个包含指令、环境配置、验证器脚本及元数据的完整强化学习任务包。研究者可借助Harbor框架快速加载这些任务,用于训练代理模型遵循安全原则的能力,或作为奖励模型微调中的可验证信号来源。其经典使用模式是作为强化学习环境,让智能体在多样化安全场景中交互,通过内置的LLM裁判自动评估行为是否符合预设安全规范。
解决学术问题
该数据集系统性地解决了语言模型安全性评估中缺乏标准化、可复现的强化学习任务基准这一核心难题。传统安全评测多依赖静态问答或人工评估,难以捕捉动态交互中的越狱、偏见或有害内容生成行为。nemotron-gym-safety通过提供确定性构建且防注入的任务包,使研究者能够严格量化不同对齐算法对模型安全性的改善效果。它推动了两类学术问题的深入探索:一是如何设计通用且鲁棒的安全奖励信号,二是如何在强化学习框架下实现原则驱动的行为约束,其影响力体现在为可验证奖励研究提供了标准化实验场域。
实际应用
在实际产业部署中,nemotron-gym-safety支撑着对话系统、内容审核助手和自动化决策代理的安全护栏建设。企业利用该数据集构建的强化学习管道,可针对客服机器人定制合规性训练,确保其不泄露隐私信息或生成歧视性回复。教育平台借助其安全场景模拟,训练辅导代理在讨论敏感话题时遵循伦理规范。金融与医疗领域的AI助手通过在该数据集环境中反复演练,学会拒绝不恰当指令并主动规避风险。此外,该数据集的Harbor格式天生适配容器化部署,使得安全策略的持续验证能无缝集成到CI/CD流水线中。
数据集最近研究
最新研究方向
在人工智能安全与强化学习交叉领域,nemotron-gym-safety数据集的问世标志着可验证奖励机制在红队测试与对齐研究中的关键突破。该数据集源自NVIDIA的Nemotron-RL-Safety-v1,经Harbor格式转换后,以结构化任务形式提供安全场景的指令、环境及验证器,尤其利用LLM裁判(如GPT-4o-mini)对响应进行原则性评分。这为自动化评估大模型安全行为提供了可复现的基准,推动从人工审计向可扩展、可验证的强化学习反馈闭环演进,深刻影响着AI安全治理中的可审计性与标准化进程。
以上内容由遇见数据集搜集并总结生成


