msmarco
收藏Hugging Face2025-02-14 更新2025-02-15 收录
下载链接:
https://huggingface.co/datasets/sentence-transformers/msmarco
下载链接
链接失效反馈官方服务:
资源简介:
MS MARCO训练数据集,包含三个子数据集:triplets、bert-ensemble-mse和bert-ensemble-margin-mse。triplets为包含查询ID、正例ID和负例ID的三元组数据集;bert-ensemble-mse为包含查询ID、段落ID和分数的元组数据集;bert-ensemble-margin-mse为包含查询ID、正例ID、负例ID和分数的四元组数据集。同时提供queries和corpus两个辅助数据集,分别包含查询文本和段落文本。
The MS MARCO training dataset includes three sub-datasets: triplets, bert-ensemble-mse, and bert-ensemble-margin-mse. The triplets is a triple dataset containing query ID, positive passage ID, and negative passage ID; the bert-ensemble-mse is a tuple dataset containing query ID, passage ID, and score; the bert-ensemble-margin-mse is a quadruple dataset containing query ID, positive passage ID, negative passage ID, and score. Additionally, two auxiliary datasets named queries and corpus are provided, which contain query texts and passage texts respectively.
创建时间:
2025-02-14
搜集汇总
数据集介绍
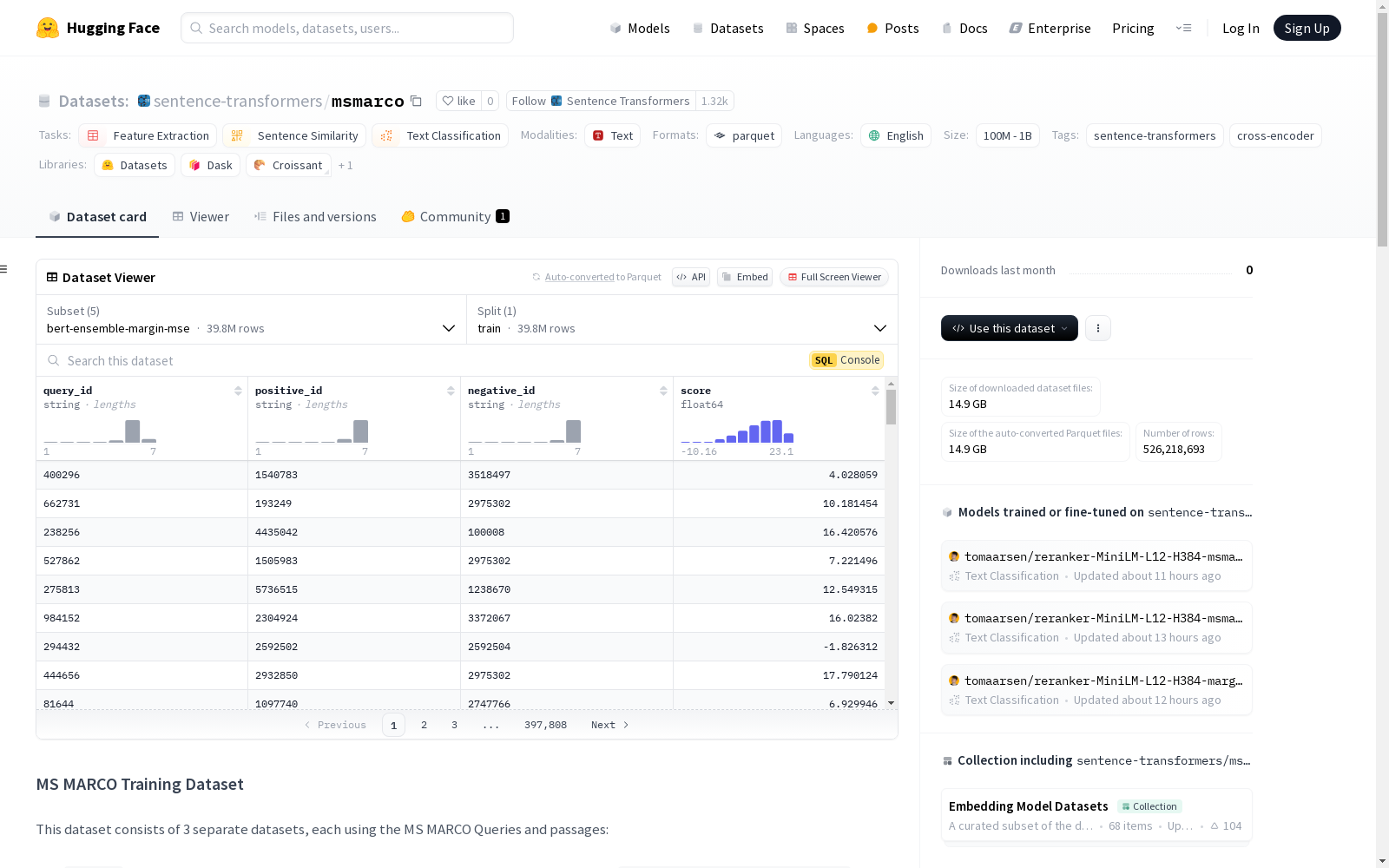
构建方式
MS MARCO数据集通过整合查询、段落以及它们之间的正负样本三元组构建而成。其中,查询和段落数据分别来源于MS MARCO的`queries.tar.gz`和`collection.tar.gz`,而三元组数据则通过对原始`qidpidtriples.train.full.2.tsv.gz`文件进行重新洗牌获取。此外,`bert-ensemble-mse`和`bert-ensemble-margin-mse`子集通过读取Hofstätter et al. 2020的BERT_CAT Ensemble分数,并计算相应的得分差构建而成。
特点
该数据集的特点在于其丰富的文本信息和结构化的三元组数据,适合于进行句子相似度、特征提取和文本分类等任务。数据集包含大量查询和对应的正负段落样本,有助于训练具有高度区分度的嵌入模型或重排模型。同时,通过BERT_CAT Ensemble得分,可以直接应用于多种损失函数的训练,如InfoNCE损失和MarginMLE损失。
使用方法
使用该数据集时,首先需要根据具体的任务选择合适的子集,如进行排名损失训练可选择`triplets`子集,而使用MLE损失训练则可选择`bert-ensemble-mse`或`bert-ensemble-margin-mse`子集。通过将id转换为实际文本,可以更直观地进行模型训练和评估。各个子集的数据均通过对应的路径进行读取,确保了数据加载的灵活性和高效性。
背景与挑战
背景概述
MS MARCO(Microsoft Machine Reading Comprehension)数据集,由微软研究院于2016年创建,是自然语言处理领域中的重要资源。该数据集旨在推进机器阅读理解技术的发展,特别是对问答系统的性能提升具有显著影响。MS MARCO的核心研究问题是如何提高机器对自然语言查询的理解能力,以及如何从大量非结构化文本中检索出最相关的答案。该数据集的构建集合了来自真实用户在微软的Bing搜索引擎上的查询数据,以及对应的网页文本,其规模之大和数据的真实性使其在学术界和工业界产生了广泛的影响。
当前挑战
MS MARCO数据集在构建和应用过程中面临的挑战包括:1) 处理大规模数据集时,如何保持高效的文本检索和相关性评分;2) 数据集的多样性和复杂性对模型提出了更高的要求,需要模型能够理解查询和文档之间的微妙差异;3) 如何在训练中避免偏见,确保模型对不同类型查询的泛化能力;4) 在构建过程中,还需克服数据清洗、预处理以及数据不平衡等实际问题。
常用场景
经典使用场景
在自然语言处理领域,MS MARCO数据集的经典使用场景主要涉及构建和训练检索型问答系统。该数据集提供了大规模的查询-文档对,以及正负样本三元组,使得研究者能够利用这些信息来训练模型,从而学习到如何根据查询返回最相关的文档。
实际应用
在实际应用中,MS MARCO数据集被广泛用于搜索引擎优化、智能问答系统构建等领域。它使得开发出的系统能够更好地理解和响应用户查询,为用户提供更为准确和高效的信息检索服务。
衍生相关工作
基于MS MARCO数据集,研究者们衍生出了一系列相关工作,如使用不同的损失函数和模型架构进行实验,探索更有效的信息检索算法。这些研究进一步推动了问答系统领域的发展,并促进了相关技术的进步。
以上内容由遇见数据集搜集并总结生成


