msmarco
收藏Hugging Face2025-08-27 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/hseb-benchmark/msmarco
下载链接
链接失效反馈官方服务:
资源简介:
HSEB MSMARCO基准数据集,基于MSMARCO数据集构建,包含文本、ID、嵌入向量等特征。数据集分为1K、100K、1M三种规模,每种规模都有对应的查询和语料库。数据集还根据过滤选择性的不同,提供了不同标签的文档。对于每个查询和每个选择性级别,都有预计算的确切k-NN搜索结果。
HSEB MSMARCO benchmark dataset, constructed based on the MSMARCO dataset, contains features such as text, IDs, and embedding vectors. This dataset is divided into three scales: 1K, 100K, and 1M, each with a corresponding query set and corpus. Additionally, the dataset provides documents with different labels based on varying filtering selectivities. Pre-computed exact k-NN search results are available for every query and each selectivity level.
创建时间:
2025-08-26
原始信息汇总
数据集概述
基本信息
- 数据集名称:HSEB MSMARCO benchmarking dataset
- 许可证:Apache 2.0
- 语言:英语(en)
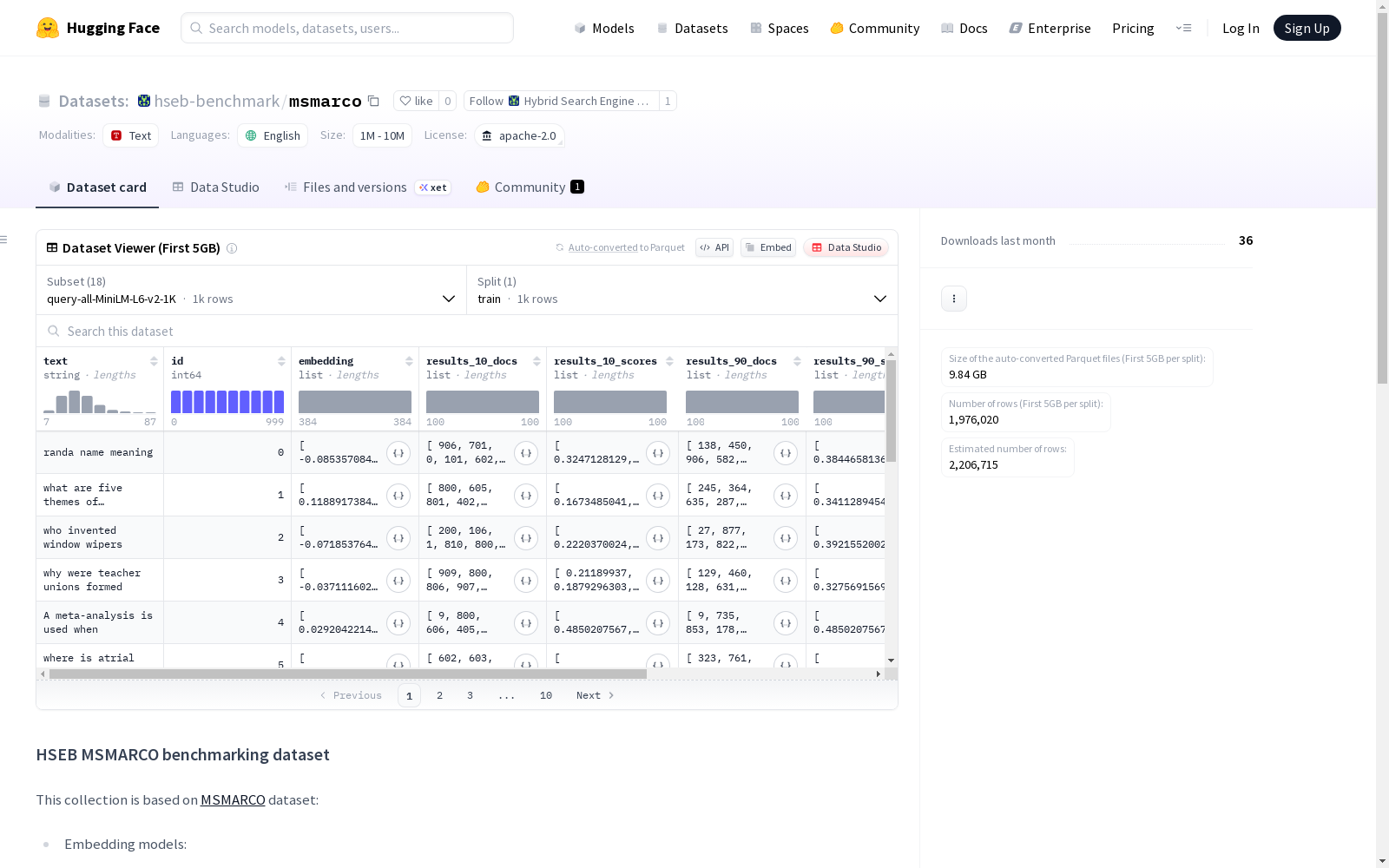
数据集结构
- 特征:
- text(字符串)
- id(int64)
- embedding(float32序列)
- results_10_docs(int64序列)
- results_10_scores(float32序列)
- results_90_docs(int64序列)
- results_90_scores(float32序列)
- results_100_docs(int64序列)
- results_100_scores(float32序列)
- tag(int64序列)
配置信息
- 配置名称:
- query-all-MiniLM-L6-v2-1K
- corpus-all-MiniLM-L6-v2-1K
- query-all-MiniLM-L6-v2-100K
- corpus-all-MiniLM-L6-v2-100K
- query-all-MiniLM-L6-v2-1M
- corpus-all-MiniLM-L6-v2-1M
- query-e5-base-v2-1K
- corpus-e5-base-v2-1K
- query-e5-base-v2-100K
- corpus-e5-base-v2-100K
- query-e5-base-v2-1M
- corpus-e5-base-v2-1M
- query-e5-large-v2-1K
- corpus-e5-large-v2-1K
- query-e5-large-v2-100K
- corpus-e5-large-v2-100K
- query-e5-large-v2-1M
- corpus-e5-large-v2-1M
数据集详情
- 基础数据集:基于MSMARCO数据集
- 嵌入模型:
- 384维度:sentence-transformers/all-MiniLM-L6-v2
- 768维度:intfloat/e5-base-v2
- 1024维度:intfloat-e5-large-v2
- 数据分割:
- 1K:1K文档,1K查询
- 100K:100K文档,1K查询
- 1M:1M文档,1K查询
- 过滤选择性:
- 10%为高选择性,90%为低选择性,100%无过滤
- 每个文档基于采样选择性有标签,10%的文档标签为10,50%的文档标签为50
- 精确匹配结果:
- 每个选择性级别为每个查询预计算了前100个文档的精确k-NN搜索结果
加载方式
使用Huggingface datasets库加载: python from datasets import load_dataset query = load_dataset("hseb-benchmark/msmarco", "query-all-MiniLM-L6-v2-1M") corpus = load_dataset("hseb-benchmark/msmarco", "corpus-all-MiniLM-L6-v2-1M")
配置名称格式:<query|corpus>-<model>-<size>
搜集汇总
数据集介绍
构建方式
在信息检索领域,MSMARCO数据集以其大规模真实查询文档对著称。本基准数据集基于原始MSMARCO语料,采用三种不同维度的嵌入模型(all-MiniLM-L6-v2、e5-base-v2和e5-large-v2)生成向量表示,通过分层抽样构建了1K、100K和1M三种规模的文档集合。每个文档根据选择性过滤策略被赋予特定标签,并预先计算了不同选择性层级下的精确k近邻搜索结果,形成多维度评估体系。
特点
该数据集最显著的特征在于其多维度的评估架构,提供384维、768维和1024维三种不同嵌入空间的向量表示,满足不同复杂度模型的测试需求。数据集采用分级选择性设计,包含10%、90%和100%三种过滤层级,每个文档配有选择性标签。预计算的top-100文档检索结果极大简化了评估流程,而三种规模子集的设计则支持从轻量级到大规模的全方位性能验证。
使用方法
研究人员可通过HuggingFace datasets库灵活加载数据集,使用形如'query-all-MiniLM-L6-v2-1M'的配置名称指定需要加载的模块。配置名称采用三段式结构:首段区分查询/文档集,中段指定嵌入模型类型,末段确定数据规模。这种模块化设计允许用户根据实验需求自由组合不同嵌入维度与数据规模,为信息检索系统的性能评估提供标准化测试环境。
背景与挑战
背景概述
MSMARCO数据集由微软研究院于2016年推出,旨在推动机器阅读理解与信息检索领域的发展。该数据集基于真实网络搜索查询构建,包含百万级人工生成的问答对和相关文档,为核心研究问题——开放域问答和文档检索——提供了大规模评估基准。其创新性在于模拟真实搜索场景,通过精细的标注体系为自然语言处理模型提供了丰富的训练与测试资源,显著提升了对话系统和搜索引擎的智能化水平。
当前挑战
该数据集致力于解决开放域问答中精准文档检索的挑战,包括对复杂查询意图的理解和多文档证据融合问题。构建过程中面临大规模人工标注的一致性保障、噪声数据处理以及检索结果相关性评估的标准化等难题。不同嵌入模型与规模配置的引入进一步增加了跨模型性能对比和计算效率优化的复杂性,需平衡检索精度与系统开销。
常用场景
经典使用场景
在信息检索领域,MSMARCO数据集作为大规模机器阅读理解语料库,其经典使用场景聚焦于评估神经检索模型的性能。该数据集通过模拟真实网络搜索环境,为研究者提供了丰富的查询-文档对及其相关性标注,成为测试排序算法和深度匹配模型的基准平台。嵌入向量与预计算结果的结合,使得该数据集能够高效支撑k近邻搜索与语义相似度计算的实验验证。
解决学术问题
MSMARCO数据集有效解决了信息检索中语义匹配精度评估的难题,为稠密检索模型提供了标准化测试环境。通过引入多维度嵌入表示和分层选择性标注,该数据集推动了检索模型在查询理解、文档表示学习方面的理论突破。其结构化设计显著降低了学术界对大规模检索系统进行可重复实验的门槛,促进了检索模型与自然语言处理的跨领域融合。
衍生相关工作
MSMARCO数据集催生了诸多里程碑式的研究成果,包括基于BERT的Cross-Encoder排序模型、ANCE异步负采样训练框架以及DPR稠密段落检索系统。这些工作通过利用该数据集的层次化标注和嵌入特征,推动了端到端检索模型的发展。后续研究进一步拓展了其在多语言检索、跨模态搜索等方向的应用边界,形成了完整的神经检索研究体系。
以上内容由遇见数据集搜集并总结生成


