gptclonebench
收藏Hugging Face2025-04-21 更新2025-04-22 收录
下载链接:
https://huggingface.co/datasets/ohassane/gptclonebench
下载链接
链接失效反馈官方服务:
资源简介:
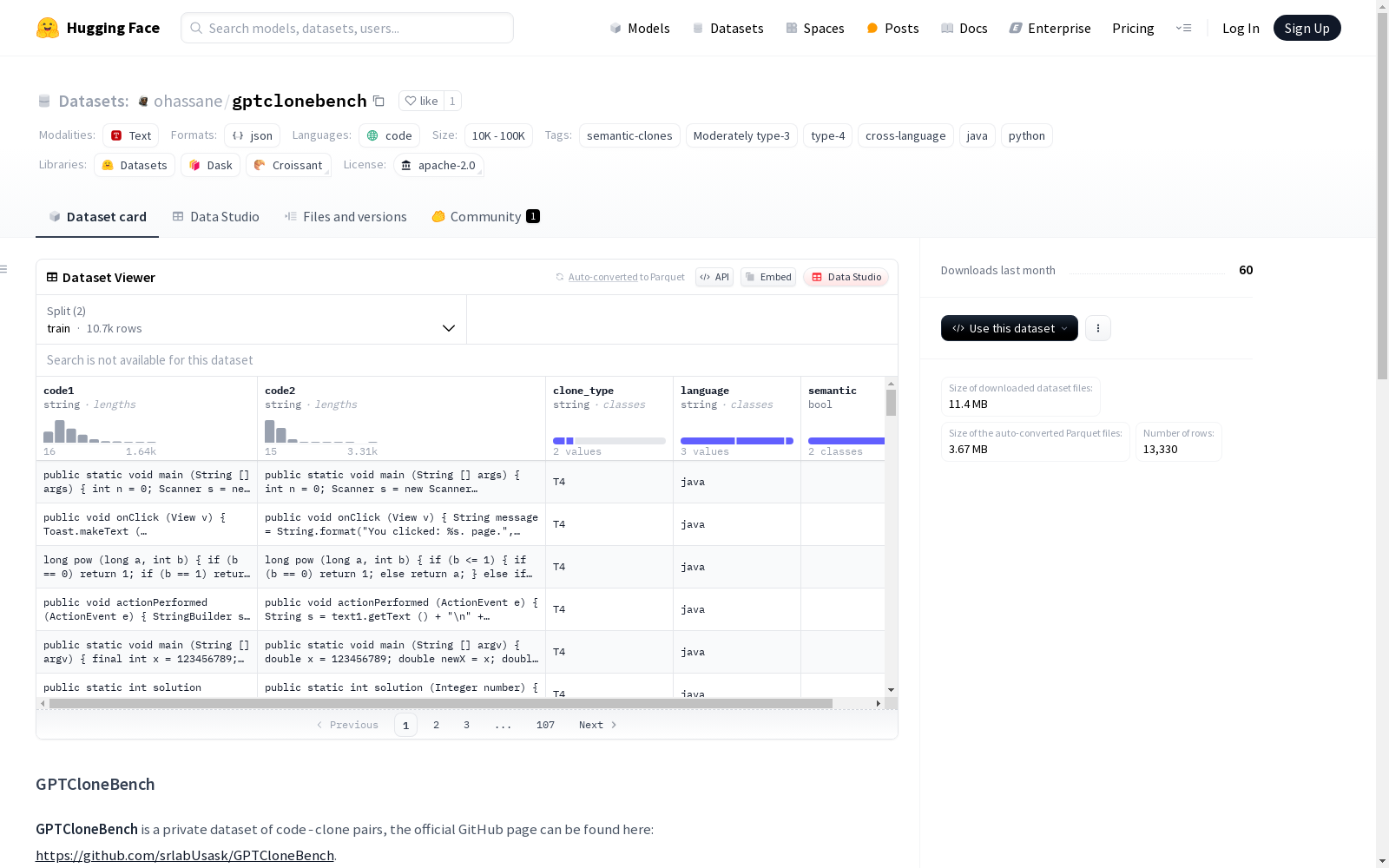
GPTCloneBench是一个代码克隆对的私有数据集,用于帮助训练大型语言模型。数据集包含Java、Python以及跨语言的代码片段,并标记了克隆类型和语义信息。数据集分为训练集和评估集,每个集都包含多个JSONL文件,文件中的每一行是一个包含两个代码片段、克隆子类型、语言和语义信息的JSON对象。
创建时间:
2025-04-19
搜集汇总
数据集介绍
构建方式
在代码克隆检测研究领域,GPTCloneBench数据集通过系统化采集Java和Python代码片段对构建而成。该数据集源自开源项目GPTCloneBench的代码库,采用跨语言配对策略,将原始数据重新组织为JSONL格式文件。为避免文件体积限制,训练集被智能分割为all_clones.jsonl和all_clones2.jsonl两个子文件,每个条目包含代码对、克隆类型、语言标识和语义相似性标注等多维元数据。
特点
作为专注于语义克隆检测的基准数据集,GPTCloneBench涵盖了中度Type-3到Type-4的克隆变体,特别包含Java-Python跨语言克隆对。数据条目中的semantic字段采用三态逻辑设计,既能表示单语言克隆的语义真值,又可标识跨语言克隆的特殊场景。该数据集通过严格的类型标注体系,为研究现代编程语言间的深层语义等价关系提供了重要实验素材。
使用方法
研究者可通过HuggingFace数据集库便捷加载该资源,使用load_dataset函数指定JSON格式解析器,并传入预定义的云端文件URL路径。数据加载支持训练集与验证集的分离式获取,其中训练集需合并两个分片文件。加载后的数据集可直接应用于代码克隆检测模型的训练与评估,其结构化字段设计便于特征提取和标签处理,为大规模语言模型的代码理解能力优化提供标准化测试平台。
背景与挑战
背景概述
GPTCloneBench数据集由Saskatchewan大学软件研究实验室(srLabUsask)开发,专注于代码克隆检测领域,特别是跨语言(Java与Python)及语义克隆(Type-3与Type-4)的研究。该数据集通过构建成对的代码片段,旨在解决软件工程中代码复用导致的维护性难题,为机器学习模型提供识别功能相似但实现形式迥异的代码样本。其跨语言特性突破了传统克隆检测的单一语言局限,推动了代码语义相似性分析的边界扩展。
当前挑战
该数据集面临的核心挑战体现在两个维度:技术层面需解决跨语言语法差异对语义对齐的干扰,例如Java静态类型与Python动态类型的映射难题;数据构建层面则涉及克隆类型标注的粒度把控,尤其是Moderately Type-3与Type-4克隆的判别需结合控制流与数据结构等多维特征。此外,样本规模受限于代码片段的函数级粒度,可能影响模型对系统级克隆模式的捕捉能力。
常用场景
经典使用场景
在软件工程领域,代码克隆检测是保障代码质量和维护效率的关键技术。GPTCloneBench数据集通过提供Java和Python两种语言的代码片段对,支持类型3(MT3)和类型4(T4)克隆的识别,为研究者构建和评估克隆检测模型提供了标准化的测试平台。该数据集特别适用于跨语言克隆检测场景,填补了传统方法在语义相似性分析上的不足。
解决学术问题
该数据集有效解决了代码克隆研究中跨语言语义相似性判定的难题。通过标注克隆类型和语言属性,研究者能够量化分析不同克隆检测算法在跨语言场景下的性能差异。其包含的语义克隆样本为探索深度学习模型在抽象语法树(AST)和中间表示(IR)层面的特征提取能力提供了实验基础,推动了程序理解领域的理论发展。
衍生相关工作
该数据集已催生多项前沿研究,包括基于Transformer的跨语言克隆检测框架CLCDetector,以及结合图神经网络的语义克隆识别模型GraphClone。部分团队将其与BigCloneBench进行联合训练,开发出支持多粒度克隆检测的混合系统。相关成果发表在ICSE、FSE等软件工程顶会,显著提升了该领域的基准测试水平。
以上内容由遇见数据集搜集并总结生成


