kaggle-toxic-annotated-filtered
收藏Hugging Face2024-12-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tcapelle/kaggle-toxic-annotated-filtered
下载链接
链接失效反馈官方服务:
资源简介:
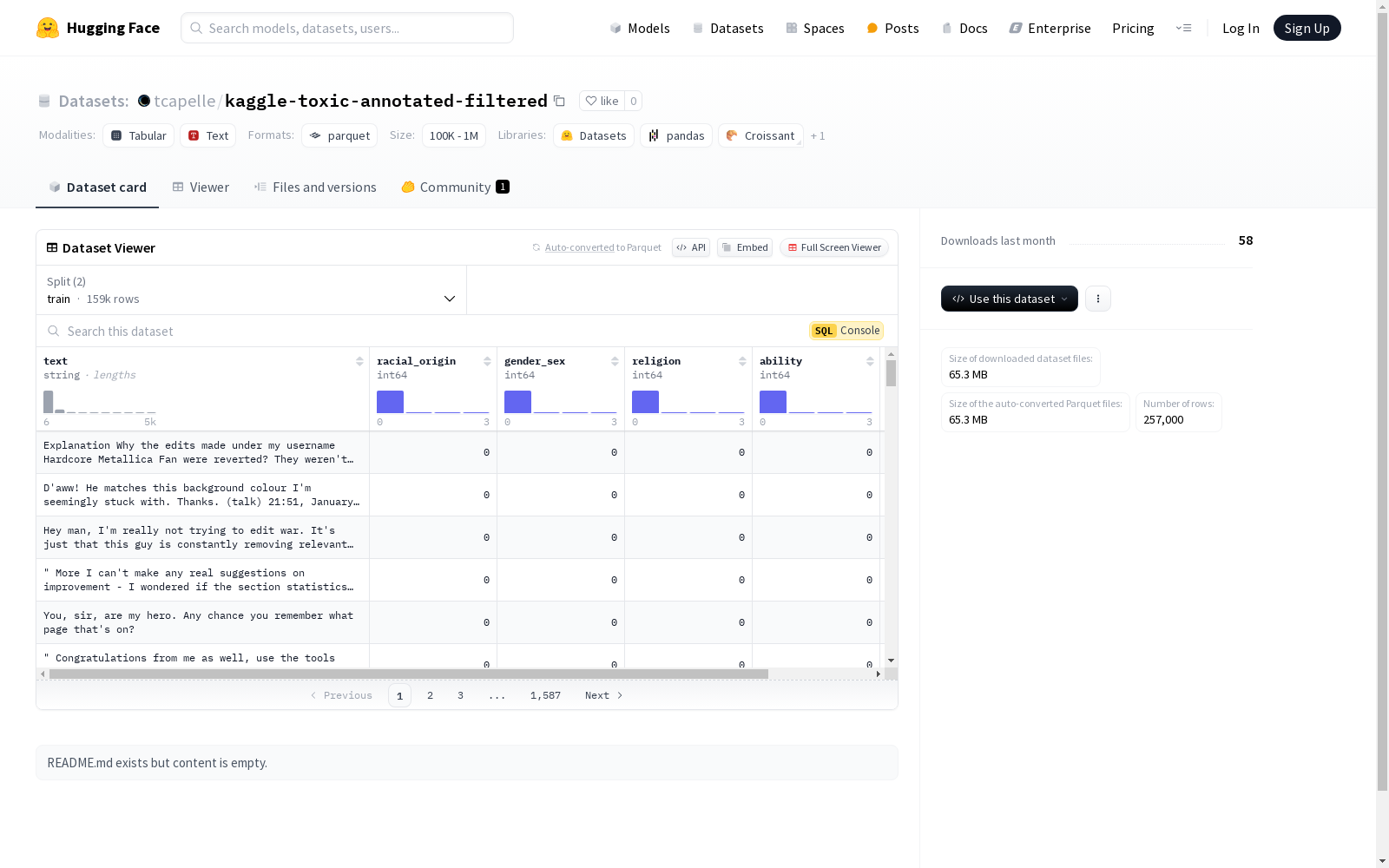
该数据集包含文本、种族起源、性别、宗教、能力和暴力倾向等多个特征,每个特征都有对应的数值类型。数据集分为训练集和测试集,分别包含158639和98361个样本。数据集的总下载大小为65326610字节,总大小为111573118.0字节。数据集配置为默认配置,数据文件路径分别指向训练集和测试集的文件。
创建时间:
2024-12-01
原始信息汇总
数据集概述
数据集信息
-
特征:
- text: 文本内容,数据类型为字符串。
- racial_origin: 种族起源,数据类型为整数。
- gender_sex: 性别,数据类型为整数。
- religion: 宗教,数据类型为整数。
- ability: 能力,数据类型为整数。
- violence: 暴力,数据类型为整数。
-
数据集划分:
- train: 训练集,包含158,639个样本,占用69,717,910字节。
- test: 测试集,包含98,361个样本,占用41,855,208字节。
-
数据集大小:
- 下载大小: 65,326,610字节。
- 总大小: 111,573,118字节。
配置信息
- 配置名称: default
- 数据文件路径:
- train: data/train-*
- test: data/test-*
- 数据文件路径:
搜集汇总
数据集介绍
构建方式
kaggle-toxic-annotated-filtered数据集的构建基于对文本内容的多维度标注,涵盖种族、性别、宗教、能力和暴力等多个敏感领域的标注。通过系统化的标注流程,确保每条文本在不同维度上的分类准确性,从而为研究者提供了一个多层次的毒性文本分析框架。
使用方法
使用kaggle-toxic-annotated-filtered数据集时,研究者可以通过加载'train'和'test'两个主要数据集分割,分别用于模型训练和验证。数据集的特征包括文本内容及其在种族、性别、宗教等维度的标注,研究者可以根据具体需求选择合适的特征进行模型训练和评估。
背景与挑战
背景概述
kaggle-toxic-annotated-filtered数据集由Kaggle社区于近年创建,专注于检测和分类网络文本中的有害内容。该数据集的核心研究问题在于如何有效识别和标注涉及种族、性别、宗教、能力及暴力等方面的有害言论,旨在为自然语言处理领域的研究者提供一个标准化的基准数据集。通过该数据集,研究者可以开发和评估针对网络有害内容的检测算法,从而推动在线社区的健康发展。
当前挑战
该数据集在构建过程中面临的主要挑战包括:首先,有害内容的定义和分类标准复杂且主观,不同文化和语境下对有害言论的理解存在差异,导致标注的一致性和准确性难以保证。其次,数据集的规模庞大,涉及多种语言和表达方式,如何确保标注的全面性和代表性是一个技术难题。此外,随着网络语言的快速演变,数据集的时效性和更新频率也成为了一个持续的挑战。
常用场景
经典使用场景
在自然语言处理领域,kaggle-toxic-annotated-filtered数据集常用于构建和评估文本分类模型,特别是针对多标签分类任务。该数据集通过标注文本中的种族、性别、宗教、能力及暴力等多个维度的敏感信息,为研究者提供了一个丰富的资源库,用于开发能够识别和过滤有害内容的算法。
解决学术问题
该数据集解决了在多标签分类任务中,如何有效识别和区分不同类型敏感信息的关键问题。通过提供详细的标注信息,它为研究者提供了一个标准化的测试平台,促进了相关算法的开发和评估,从而推动了自然语言处理技术在内容审核和安全领域的应用。
实际应用
在实际应用中,kaggle-toxic-annotated-filtered数据集被广泛用于社交媒体平台的内容审核系统,帮助自动识别和过滤含有种族歧视、性别歧视、宗教偏见等有害内容的帖子。此外,它还被用于开发企业内部的沟通工具,以确保工作环境中的言论安全和尊重。
数据集最近研究
最新研究方向
在自然语言处理领域,kaggle-toxic-annotated-filtered数据集因其对文本中多维度毒性标注的精细处理而备受关注。该数据集不仅涵盖了传统的文本内容,还引入了种族、性别、宗教、能力及暴力等多个维度的标注,为研究者提供了更为丰富的分析视角。当前,该数据集在前沿研究中主要用于开发和评估多维度毒性检测模型,旨在提升社交媒体和在线平台的内容审核效率与准确性。此外,随着社会对多样性和包容性议题的日益重视,该数据集的研究成果有望为构建更加和谐的网络环境提供技术支持,具有重要的社会意义。
以上内容由遇见数据集搜集并总结生成


