kaggle-toxic-annotated
收藏Hugging Face2024-12-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tcapelle/kaggle-toxic-annotated
下载链接
链接失效反馈官方服务:
资源简介:
这是一个由Kaggle提供的毒性评论数据集,通过gpt-4o-mini模型标注,使用了与Toxic-Commons相同的提示。数据集包含评论的文本内容以及多个二进制标签,用于标记评论的毒性程度。此外,还有一个结构化特征,用于进一步细分和评分不同类型的歧视和暴力倾向。数据集分为训练集和测试集,分别包含159570和153163个样本。
This is a toxic comment dataset provided by Kaggle, annotated with the GPT-4o-mini model using the identical prompt as Toxic-Commons. The dataset includes the text content of comments and multiple binary labels for marking the toxicity level of the comments. Furthermore, a structured feature is provided to further categorize and score different types of discriminatory and violent tendencies. The dataset is split into training and test sets, which contain 159,570 and 153,163 samples respectively.
创建时间:
2024-12-01
原始信息汇总
数据集概述
数据集信息
- 数据集名称: Kaggle toxic dataset annotated with gpt-4o-mini
- 数据集大小: 370369620 字节
- 下载大小: 159301273 字节
数据集特征
- id: 字符串类型
- comment_text: 字符串类型
- toxic: 64位整数类型
- severe_toxic: 64位整数类型
- obscene: 64位整数类型
- threat: 64位整数类型
- insult: 64位整数类型
- identity_hate: 64位整数类型
- toxic_commons_label: 结构体类型
- ability_discrimination_reasoning: 字符串类型
- ability_discrimination_score: 64位整数类型
- aggressive_violent_reasoning: 字符串类型
- aggressive_violent_score: 64位整数类型
- gender_sex_discrimination_reasoning: 字符串类型
- gender_sex_discrimination_score: 64位整数类型
- racial_origin_discrimination_reasoning: 字符串类型
- racial_origin_discrimination_score: 64位整数类型
- religious_discrimination_reasoning: 字符串类型
- religious_discrimination_score: 64位整数类型
数据集分割
- train:
- 样本数量: 159570
- 字节数: 190721507
- test:
- 样本数量: 153163
- 字节数: 179648113
配置信息
- 配置名称: default
- 数据文件路径:
- train: data/train-*
- test: data/test-*
- 数据文件路径:
搜集汇总
数据集介绍
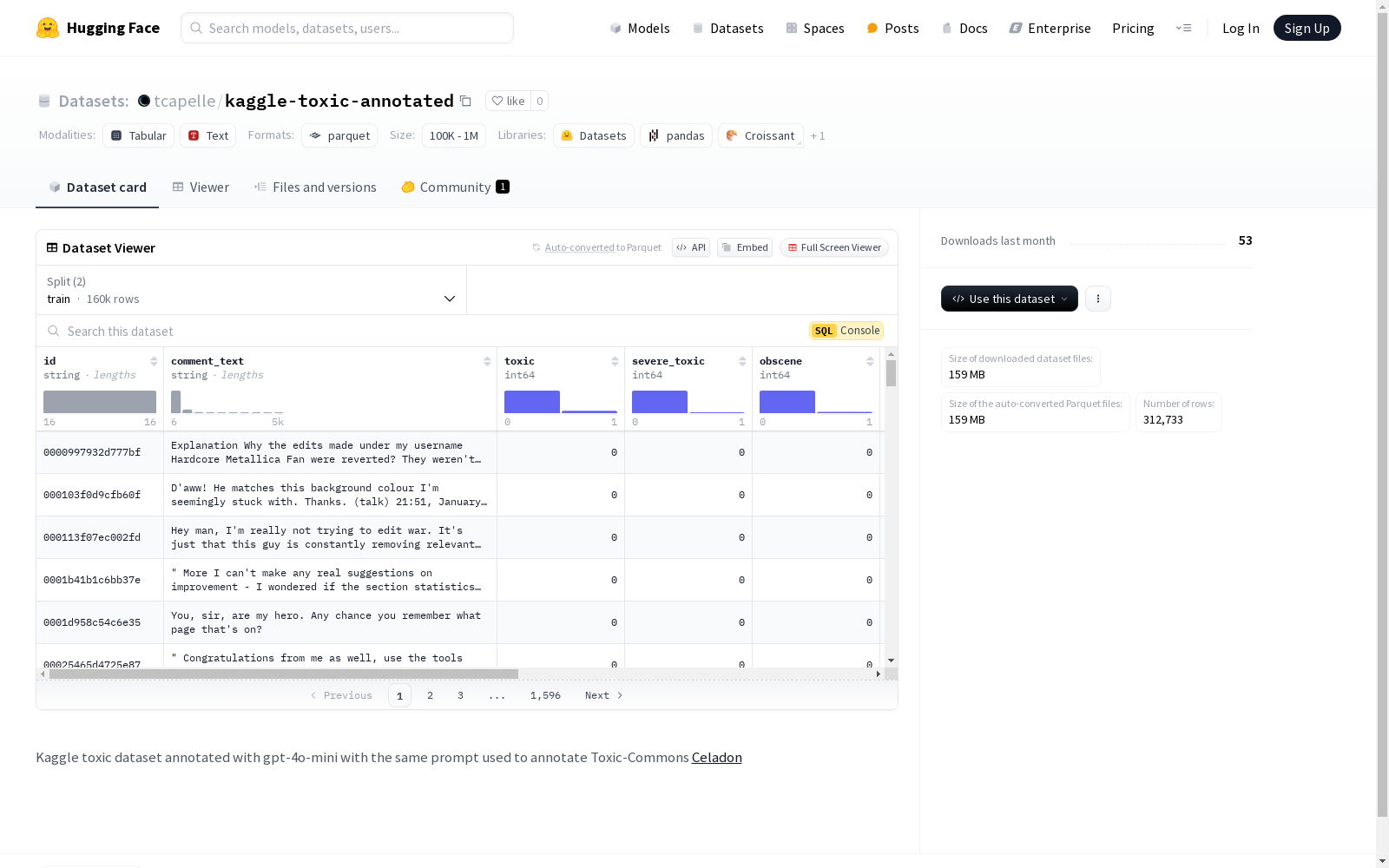
构建方式
kaggle-toxic-annotated数据集的构建基于Kaggle上的原始toxic数据集,并通过GPT-4o-mini模型进行进一步的标注。具体而言,该数据集不仅保留了原始的toxic分类标签,如toxic、severe_toxic、obscene、threat、insult和identity_hate,还引入了更为细致的toxic_commons_label结构,涵盖了能力歧视、性别歧视、种族歧视和宗教歧视等多个维度的评分与推理。这种多层次的标注方式使得数据集能够更全面地反映评论中的潜在毒性,为后续的模型训练提供了丰富的信息支持。
使用方法
kaggle-toxic-annotated数据集适用于多种自然语言处理任务,尤其是涉及文本分类和情感分析的研究。用户可以通过加载数据集中的train和test两个子集进行模型训练和评估。在实际应用中,数据集的toxic_commons_label结构可以用于构建更为复杂的分类模型,或作为解释性分析的依据。此外,该数据集还可用于探索不同歧视类型在文本中的表现形式,为社会科学研究提供数据支持。
背景与挑战
背景概述
在当今数字化社会中,网络言论的监管与分类成为了一个亟待解决的问题。kaggle-toxic-annotated数据集应运而生,旨在通过机器学习技术对网络评论进行毒性分类。该数据集由Kaggle平台发布,并由主要研究人员使用GPT-4o-mini模型进行标注,确保了数据的高质量和一致性。数据集的核心研究问题是如何准确识别和分类网络评论中的毒性内容,包括但不限于侮辱、威胁和种族歧视等。这一研究不仅推动了自然语言处理技术的发展,也为网络环境的净化提供了有力的技术支持。
当前挑战
kaggle-toxic-annotated数据集在构建过程中面临多项挑战。首先,如何确保标注的准确性和一致性是一个关键问题,尤其是在处理复杂和模糊的评论时。其次,数据集的多样性和覆盖范围也是一个挑战,因为网络言论的多样性极高,涵盖了各种语言风格和文化背景。此外,模型的训练和评估也需要克服数据不平衡的问题,以确保模型在不同类型的毒性评论上都能表现出色。最后,随着网络环境的快速变化,数据集的更新和维护也是一个持续的挑战,以确保其能够反映最新的网络言论趋势。
常用场景
经典使用场景
在自然语言处理领域,kaggle-toxic-annotated数据集的经典使用场景主要集中在文本分类任务中,特别是针对网络评论的毒性检测。该数据集通过标注多种毒性类别,如‘toxic’、‘severe_toxic’、‘obscene’等,为研究者提供了一个丰富的资源,用于训练和评估模型在识别和分类有害内容方面的能力。
解决学术问题
该数据集解决了在社交媒体和在线论坛中广泛存在的毒性内容检测问题,为学术界提供了一个标准化的基准,用于评估和比较不同模型的性能。通过提供详细的标注和多维度的毒性分类,kaggle-toxic-annotated数据集有助于推动自然语言处理技术在内容审核和用户安全保障方面的研究。
实际应用
在实际应用中,kaggle-toxic-annotated数据集被广泛用于开发和优化社交媒体平台的内容过滤系统。通过训练模型识别和过滤有害评论,平台可以有效减少网络欺凌、仇恨言论和其他形式的毒性内容,从而提升用户体验和社区健康。
数据集最近研究
最新研究方向
在自然语言处理领域,kaggle-toxic-annotated数据集的最新研究方向主要集中在多维度情感分析与歧视性语言检测的深度学习模型优化上。该数据集通过引入GPT-4o-mini模型进行注释,不仅丰富了文本的情感标签,还提供了详细的歧视性语言推理和评分,为研究者提供了更为精细的分析工具。这一进展使得模型在识别和分类有毒、威胁性、侮辱性等复杂情感时表现更为精准,尤其在处理性别、种族、宗教等敏感话题时,模型的鲁棒性和公平性得到了显著提升。此外,该数据集的应用还推动了社交媒体内容审核、在线社区管理等实际场景中的技术革新,具有重要的社会意义和应用价值。
以上内容由遇见数据集搜集并总结生成


