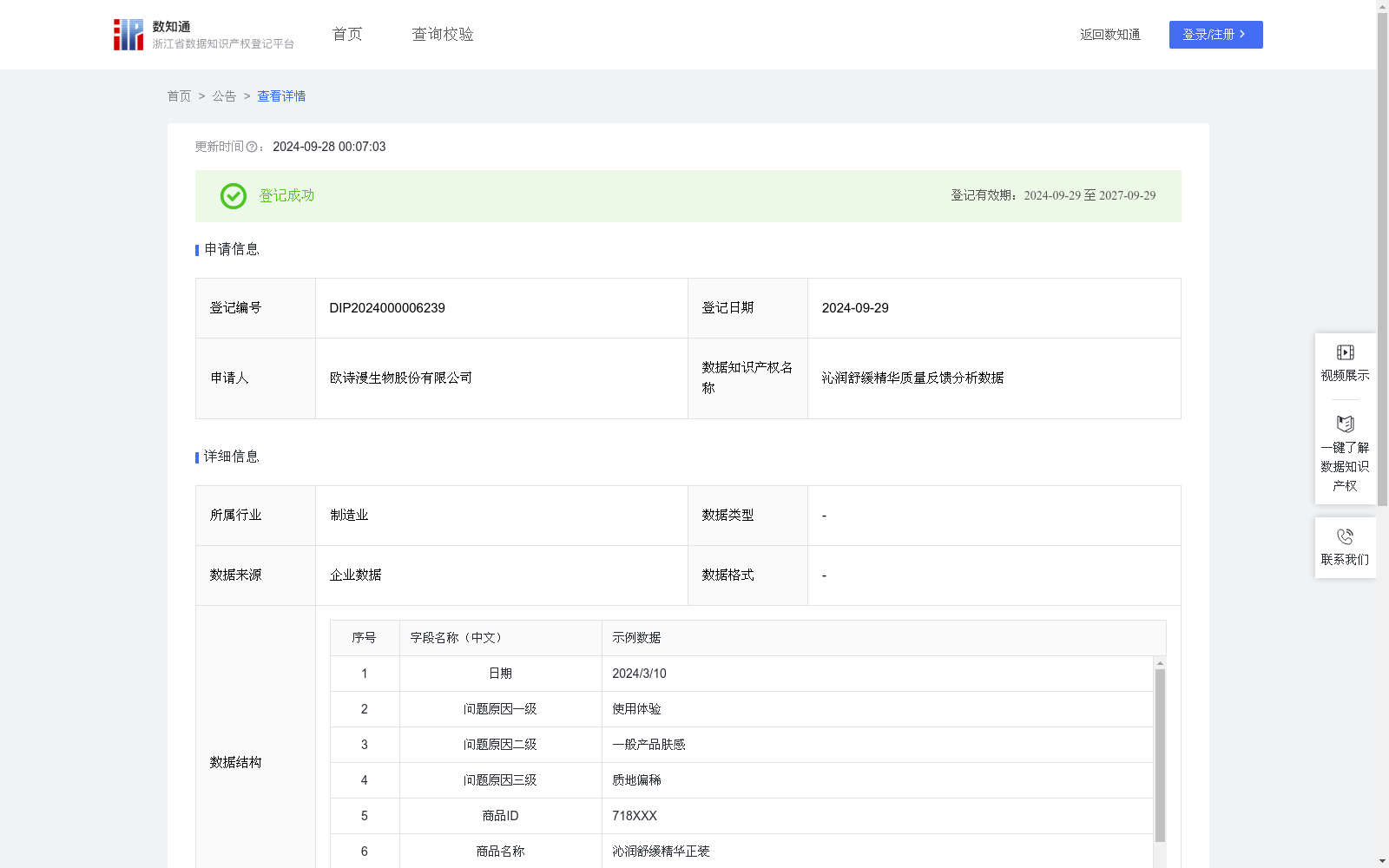
沁润舒缓精华质量反馈分析数据
收藏浙江省数据知识产权登记平台2024-09-28 更新2024-10-01 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/66611
下载链接
链接失效反馈官方服务:
资源简介:
产品的研发升级、更新换代需以大量数据为基础,线上交易为当下的主要交易途径,占据着庞大的交易比例,随之而来的是消费者反馈的海量数据,尤其对产品质量的反馈。通过系统性地收集、整理和分析这些反馈数据,第一、可以更快速、针对性地指导品牌方解决消费者的具体问题,提升用户体验,提高服务效率,第二、可以及时发现产品的质量问题,以用户反馈信息为参考,帮助本行业科研人员进行产品的迭代升级,为改良产品提供数据参考,第三、本数据的中问题原因情况,可为消费者选购适合自己的产品提供依据,第四,通过大量的反馈数据,反映出当前消费者最关注的产品功能,为行业内新产品研发,新功能开发提供参考。1、数据采集:消费者向客服反馈产品问题,客服将消费者的描述复制转述至关键词匹配模型。 2、识别、匹配:基于以往消费者反馈数据的积累,以及对关键词的标注,建立关键词匹配模型,通过海量的消费者反馈信息,对模型进行不断训练、校准,使其识别的精准度更高,根据消极词语,识别消费者的问题原因,3、判断算法:事先对关键词匹配算法进行问题级别的设定,使得模型可以基于消费者描述判定一、二、三级的问题原因,一步步由外在表现进行归因,如消费者反馈“使用后有点痒”,则三级问题原因为“痒”,二级问题原因为“过敏/不适”,一级问题原因为“不良反应”,若用户反馈均为积极表述,则三个级别的问题原因均为无,4、根据消费者的反馈,形成本数据,指导品牌分析产品质量原因,针对性地进行产品改进。
R&D upgrades and product iterations rely on massive volumes of data. Online transactions have become the primary trading channel, accounting for a large share of total transaction volume, accompanied by a vast amount of consumer feedback data, especially regarding product quality. The systematic collection, organization and analysis of this feedback data brings four key benefits:
1. It enables brands to quickly and targetedly resolve specific consumer issues, thereby improving user experience and service efficiency;
2. It allows timely detection of product quality problems, providing a reference for industry researchers to carry out product iteration and upgrade based on user feedback;
3. The analysis of problem causes in this dataset can provide consumers with a basis for selecting products suitable for their needs;
4. The massive feedback data reflects the product functions that consumers currently care most about, providing references for new product development and new function design within the industry.
The dataset construction process includes four steps:
1. Data Collection: Consumers submit product-related issues to customer service, and the customer service copies and forwards the consumers' descriptions to the keyword matching model.
2. Recognition and Matching: Based on accumulated historical consumer feedback data and annotated keywords, a keyword matching model is established. Through massive consumer feedback information, the model is continuously trained and calibrated to enhance recognition accuracy, and identifies the causes of consumer problems by leveraging negative words.
3. Judgment Algorithm: The issue levels are preset for the keyword matching algorithm, enabling the model to determine first-level, second-level and third-level problem causes based on consumers' descriptions, and attribute the causes layer by layer from external manifestations. For example, if a consumer feedbacks "Itchy after use", the third-level problem cause is "itchy", the second-level is "allergy/discomfort", and the first-level is "adverse reaction". If the user's feedback is entirely positive, all three levels of problem causes are defined as "none".
4. Form the final dataset based on consumer feedback, to guide brands in analyzing product quality issues and carry out targeted product improvements.
提供机构:
欧诗漫生物股份有限公司
创建时间:
2024-08-20
搜集汇总
数据集介绍
特点
该数据集为沁润舒缓精华产品的质量反馈分析数据,包含608条消费者反馈记录,涵盖问题原因、商品信息等字段,主要用于产品研发升级和质量改进。数据通过关键词匹配模型和问题级别判定算法处理,确保准确性和实用性。
以上内容由遇见数据集搜集并总结生成


