eksisozluk-ekonomi-ve-finans-tr
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/LLMbender/eksisozluk-ekonomi-ve-finans-tr
下载链接
链接失效反馈官方服务:
资源简介:
Ekşi Sözlük Türkçe Teknoloji Dataset是一个从土耳其平台Ekşi Sözlük的技术类别用户条目中收集的数据集,专为土耳其语自然语言处理(NLP)研究和大型语言模型(LLM)训练而设计。数据集包含39个不同主题的条目,涵盖宏观经济概念、投资工具、加密货币以及当前经济发展等内容。每个条目以JSONL格式存储,包含主题、文本内容、作者昵称、日期和唯一条目ID等字段。原始数据经过清理,移除了引用标记、URL,并过滤了少于10个单词的条目。该数据集适用于土耳其语LLM的预训练和微调、情感分析、日常土耳其语口语研究以及社交媒体文本分析等场景。数据集采用CC BY-NC 4.0许可,允许在非商业用途下使用,但需注明来源。
The Ekşi Sözlük Türkçe Teknoloji Dataset is a collection of user entries from the technology category of the Turkish platform Ekşi Sözlük, designed specifically for Turkish natural language processing (NLP) research and large language model (LLM) training. The dataset includes entries on 39 different topics, covering macroeconomic concepts, investment tools, cryptocurrencies, and current economic developments. Each entry is stored in JSONL format and contains fields such as topic, text content, author nickname, date, and unique entry ID. The raw data has been cleaned by removing quotation marks, URLs, and filtering out entries with fewer than 10 words. This dataset is suitable for pre-training and fine-tuning Turkish LLMs, sentiment analysis, research on everyday Turkish colloquial language, and social media text analysis. The dataset is licensed under CC BY-NC 4.0, allowing use for non-commercial purposes with attribution required.
创建时间:
2026-05-08
原始信息汇总
数据集概述
数据集名称:Ekşi Sözlük Türkçe Teknoloji Dataset
基本信息
- 语言:土耳其语 (tr)
- 许可证:CC BY-NC 4.0(非商业用途,需注明出处)
- 数据集规模:10,000 < N < 100,000 条记录
- 标签:turkish, nlp, web-scraped, instruction-tuning, eksisozluk, technology
数据来源
该数据集来源于土耳其知名平台 Ekşi Sözlük 的“科技”类别,收录了用户撰写的土耳其语条目(entry)。
数据内容
数据集涵盖 39 个不同的标题,涉及以下六大主题领域:
| 领域 | 涵盖标题示例 |
|---|---|
| 经济危机与总体状况 | 2025-2026 经济危机、货币贬值、通胀税、最低工资 |
| 宏观经济概念 | 通货膨胀、利率、美元、经济衰退、滞胀、通缩性衰退 |
| 投资工具 | 黄金、定期存款、投资基金、房地产、股票市场 |
| 加密货币 | 比特币、加密货币交易所、加密货币税 |
| 比较与分析 | 黄金 vs 美元、比特币 vs 黄金、加息分析 |
| 教育与概念解释 | 经济学 101、简易经济学、实例讲解经济学 |
数据格式
数据集采用 JSONL 格式,每条记录包含以下字段:
| 字段 | 说明 |
|---|---|
topic |
条目所属的标题名称 |
text |
经过清洗的条目文本内容 |
author |
用户昵称 |
date |
条目发布的时间(格式:dd.mm.yyyy hh:mm) |
entry_no |
在 Ekşi Sözlük 上的唯一条目 ID |
数据清洗
对原始数据进行了以下预处理:
- 移除了
(bkz: ...)形式的内部引用 - 清除了所有 URL 链接
- 过滤掉长度少于 10 个单词的条目
- 对多余空格进行了归一化处理
潜在应用场景
- 土耳其语大语言模型(LLM)的预训练与微调
- 土耳其语语言模型的评估
- 情感分析
- 日常土耳其语口语研究
- 社交媒体文本分析
搜集汇总
数据集介绍
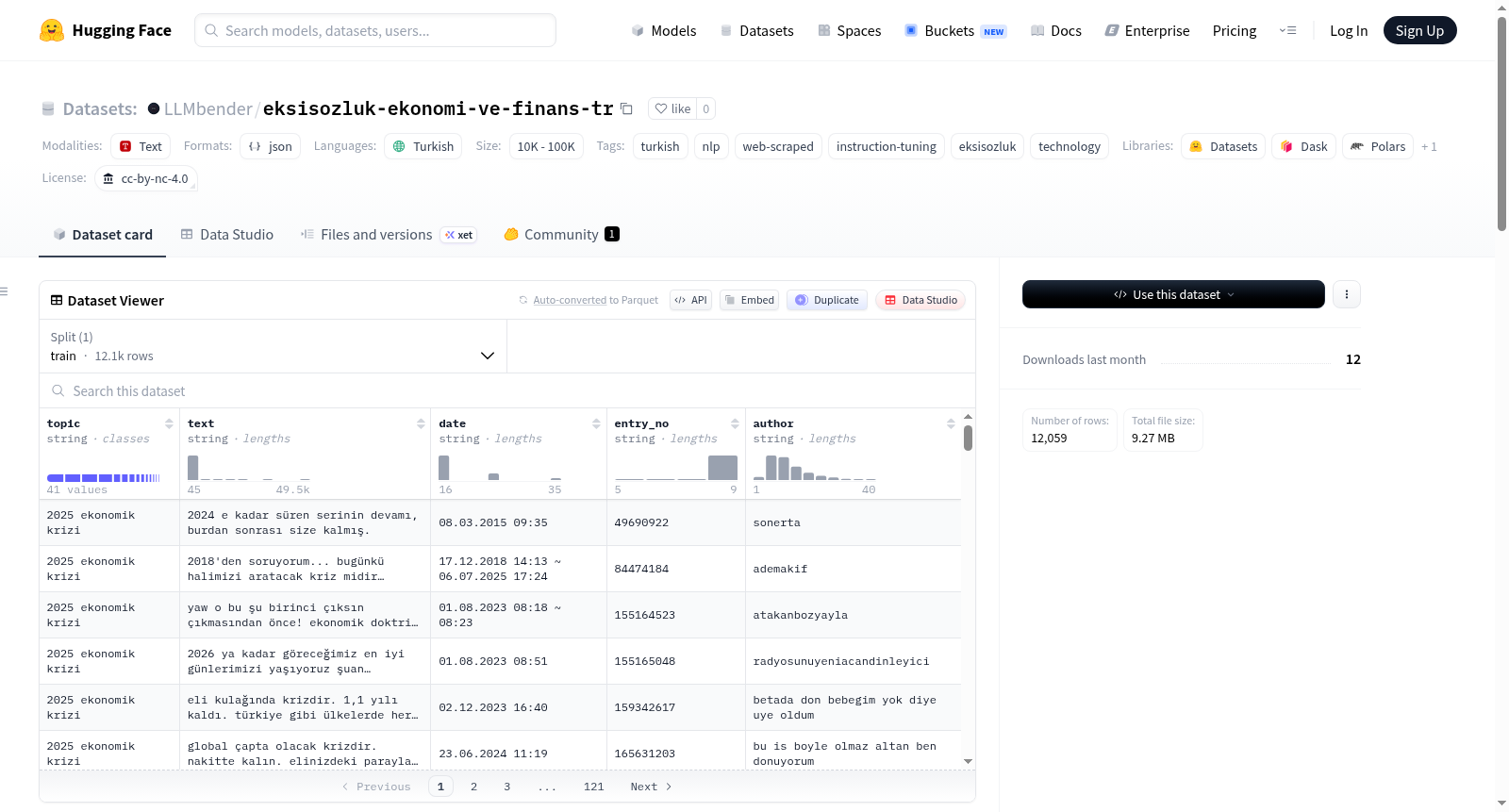
构建方式
本数据集源自土耳其知名网络社区Ekşi Sözlük,聚焦于科技与经济金融领域。通过定向爬取技术,收集了涵盖宏观经济概念、投资工具、加密货币及经济危机等39个细分话题的用户评论内容。原始数据经过系统性清洗,包括移除交叉引用标记、过滤短文本(不足10词)、标准化空白字符等预处理步骤,最终以JSONL格式存储,每条记录包含话题标签、评论正文、作者昵称、时间戳及唯一条目ID。数据集规模介于1万至10万条之间,为高质量土耳其语非结构化文本资源。
特点
该数据集具有多维度特性:其一,内容覆盖宏观经济学、投资比较(如黄金与美元)、加密货币税务等多元主题,兼具知识性与时效性;其二,数据保留原始社交语境,包括作者信息与时间戳,适用于时间序列分析;其三,文本源自用户自发贡献,语言风格贴近日常土耳其语口语,反映真实社会语义;其四,采用CC BY-NC 4.0许可协议,明确标注非商业用途,支持学术研究中的引用溯源。
使用方法
数据集适用于土耳其语自然语言处理的多项任务:可直接用于大语言模型的预训练与指令微调,提升模型对语境化俚语的理解能力;亦可用于情感分析,通过话题标签作为标注线索。研究者可依据话题字段进行领域筛选,或利用时间戳分析经济事件期间的用语演变。推荐在使用时保留原始条目ID以追踪来源,并在学术出版物中标注Hugging Face仓库作为引用依据。
背景与挑战
背景概述
Ekşi Sözlük Ekonomi ve Finans Türkçe Veri Seti, Türkiye'nin en köklü çevrimiçi sözlük platformlarından Ekşi Sözlük'ten derlenmiş, ekonomi ve finans kategorilerine odaklanan bir doğal dil işleme (NLP) kaynağıdır. 2025-2026 ekonomik krizi, enflasyon, dolar, bitcoin gibi güncel ve tarihsel makroekonomik kavramları kapsayan 39 farklı başlık altında toplanan kullanıcı entry'leri ile, Türkçe dil modellerinin eğitimi ve değerlendirilmesi için hazırlanmıştır. Veri seti, CC BY-NC 4.0 lisansı ile ticari olmayan araştırmalara sunulmuş olup, özellikle hissiyat analizi ve sosyal medya metin analizi gibi alanlarda Türkçe NLP araştırmalarına katkı sağlamayı hedeflemektedir.
当前挑战
Bu veri setinin geliştirilmesindeki temel zorluk, Ekşi Sözlük gibi kullanıcı tarafından oluşturulan içeriklerin doğasından kaynaklanan dilsel düzensizlikleri gidermektir. Ekonomi ve finans gibi hassas konularda argo, mizah, ironi ve öznel yorumların yoğunluğu, metinlerin nesnel analizini karmaşıklaştırmaktadır. Ayrıca, platformdaki (bkz: ...) referansları, URL'ler ve kısa entry'lerin temizlenmesi, veri kalitesini artırmak için önemli bir ön işleme adımı oluşturmuştur. Veri seti, 10K ile 100K arasında örnek barındırarak sınırlı bir kapsama sahip olduğundan, geniş kapsamlı dil modellerinin eğitimi için yetersiz kalabilir ve daha fazla başlık ile genişletilmeye ihtiyaç duymaktadır.
常用场景
经典使用场景
该数据集源自土耳其知名网络社区Ekşi Sözlük,聚焦于经济与金融领域,收录了涵盖宏观经济概念、投资工具、加密货币及当前经济动态等39个不同主题的用户条目。作为土耳其语自然语言处理研究的关键资源,它常被用于大规模语言模型的预训练与微调,也广泛服务于情感分析、日常口语理解及社交媒体文本挖掘等任务,为探索土耳其语在经济语境下的表达模式提供了独特而丰富的语料。
实际应用
在实际应用中,该数据集可被用于构建面向土耳其金融市场的舆情监控系统,帮助金融机构实时追踪公众对利率、通胀或汇率变动的情绪。此外,它还能支撑开发面向土耳其用户的智能投资顾问或经济教育问答系统,通过提取海量众包知识中的精粹,实现复杂经济概念的通俗化解释,从而提升金融服务的可及性与普惠性。
衍生相关工作
基于该数据集,研究人员已衍生出多项经典工作,例如针对土耳其语经济文本的情感词典构建与情感分类基准测试、面向特定投资话题(如比特币与黄金对比)的立场检测模型,以及利用条目时间戳追踪经济危机期间公众情绪动态的时序分析研究。这些工作深化了对土耳其网络社群经济认知模式的理解,并为后续跨语言经济NLP研究提供了可复用的方法论范式。
以上内容由遇见数据集搜集并总结生成


