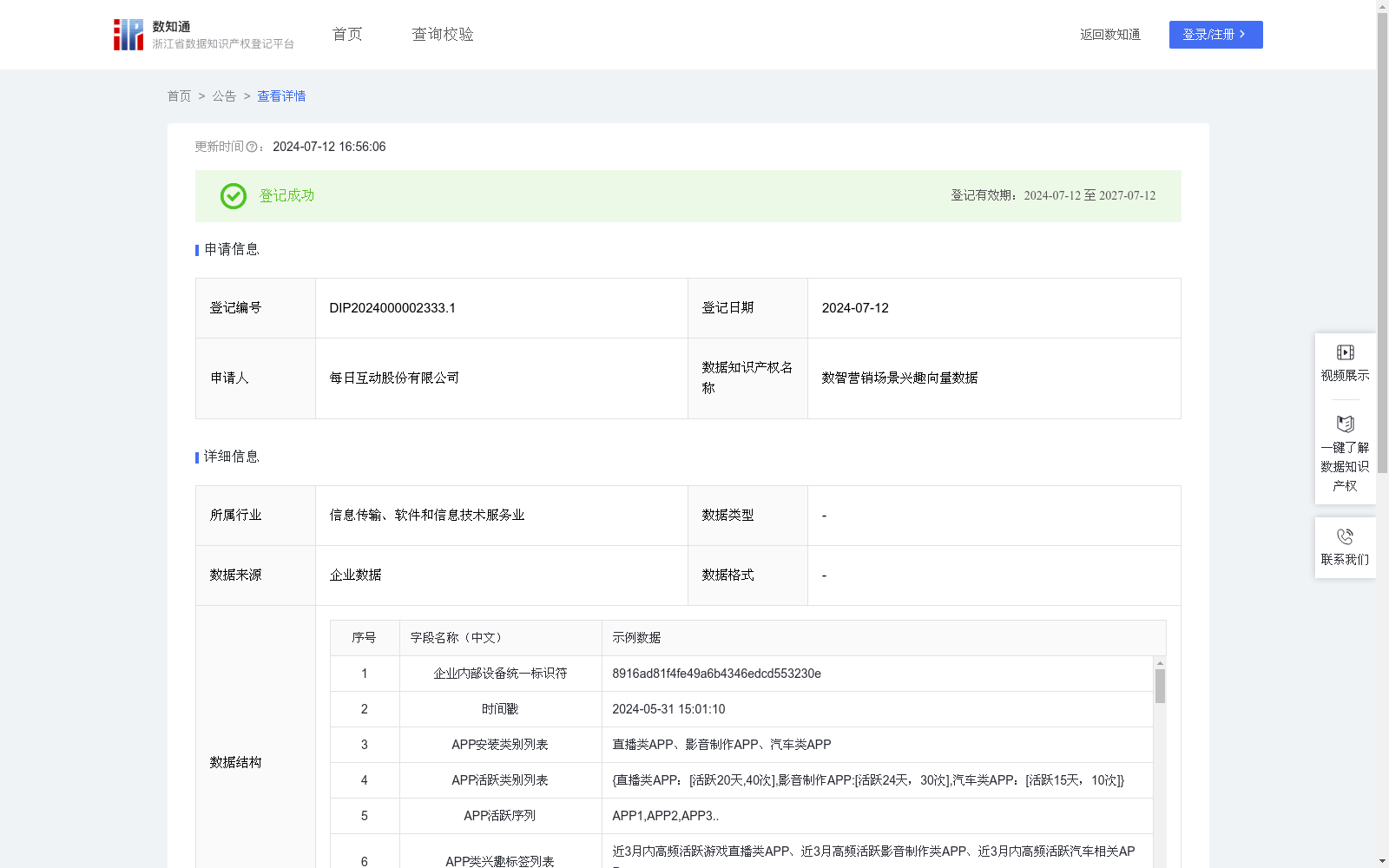
数智营销场景兴趣向量数据
收藏浙江省数据知识产权登记平台2024-07-12 更新2024-07-13 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/37799
下载链接
链接失效反馈官方服务:
资源简介:
依托开发者服务积累的数据,通过图模型、深度学习模型和技术,建立数据向量化技术,助力效果广告模型能力提升,帮助互联网广告平台、品牌方建立和优化广告投放策略,实现广告精准营销和广告投放ROI提升。在自研的每日治数平台上,构建用户线上行为偏好序列,并利用图和深度学习模型进行训练,最终生成用户的兴趣向量数据。
一、数据抽取、清理和处理
数据抽取:从数据库中抽取用户的APP活跃序列。
数据清理:去除重复、错误或无效的数据记录,处理缺失值和异常值
数据处理:对数据进行必要的转换和整合,如时间戳格式化、APP编码等
二、数据仓库层建设
1.数据模型设计
2.ETL过程
3.数据仓库优化
三、图模型和深度学习模型预训练
图模型构建:根据用户行为偏好序列(APP活跃序列),构建用户与APP之间的图结构,其中节点可以代表用户或APP,边可以代表用户与APP之间的交互行为。
图嵌入学习:利用图嵌入算法(如Node2Vec、GraphSAGE等)学习节点(用户和APP)的嵌入表示,捕捉节点之间的关系和用户的兴趣偏好。
深度学习模型构建:基于用户行为偏好序列和图嵌入结果,构建深度学习模型(如循环神经网络RNN、长短期记忆网络LSTM、Transformer等)来进一步学习用户的兴趣偏好。
四、生成用户兴趣向量数据
将训练好的深度学习模型应用于预测新用户或新数据,通过模型推理生成用户的兴趣向量数据。
Leveraging data accumulated from developer services, this dataset establishes data vectorization technology through graph models, deep learning models and related technologies, to enhance the capabilities of performance advertising models, assist internet advertising platforms and brands in establishing and optimizing advertising delivery strategies, and achieve precise advertising marketing and improved return on investment (ROI) of advertising campaigns. Based on the self-developed daily data governance platform, user online behavioral preference sequences are constructed, trained using graph and deep learning models, and finally generate user interest vector data.
1. Data Extraction, Cleaning and Processing
- Data Extraction: Extract users' APP activity sequences from databases.
- Data Cleaning: Remove duplicate, erroneous or invalid data records, and handle missing values and outliers.
- Data Processing: Perform necessary conversions and integrations on the data, such as timestamp formatting, APP encoding, etc.
2. Data Warehouse Layer Construction
1. Data Model Design
2. ETL Process
3. Data Warehouse Optimization
3. Pre-training of Graph Models and Deep Learning Models
- Graph Model Construction: Construct a graph structure between users and APPs based on user behavioral preference sequences (APP activity sequences), where nodes represent users or APPs, and edges represent interactive behaviors between users and APPs.
- Graph Embedding Learning: Use graph embedding algorithms (such as Node2Vec, GraphSAGE, etc.) to learn the embedding representations of nodes (users and APPs), capturing the relationships between nodes and users' interest preferences.
- Deep Learning Model Construction: Build deep learning models (such as Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM), Transformer, etc.) based on user behavioral preference sequences and graph embedding results to further learn users' interest preferences.
4. Generation of User Interest Vector Data
Apply the trained deep learning models to predict new users or new data, and generate user interest vector data through model inference.
提供机构:
每日互动股份有限公司
创建时间:
2024-06-27
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


