deepseek-v4-pro-max-distillation-preview-shot
收藏Hugging Face2026-04-26 更新2026-04-27 收录
下载链接:
https://huggingface.co/datasets/beyoru/deepseek-v4-pro-max-distillation-preview-shot
下载链接
链接失效反馈官方服务:
资源简介:
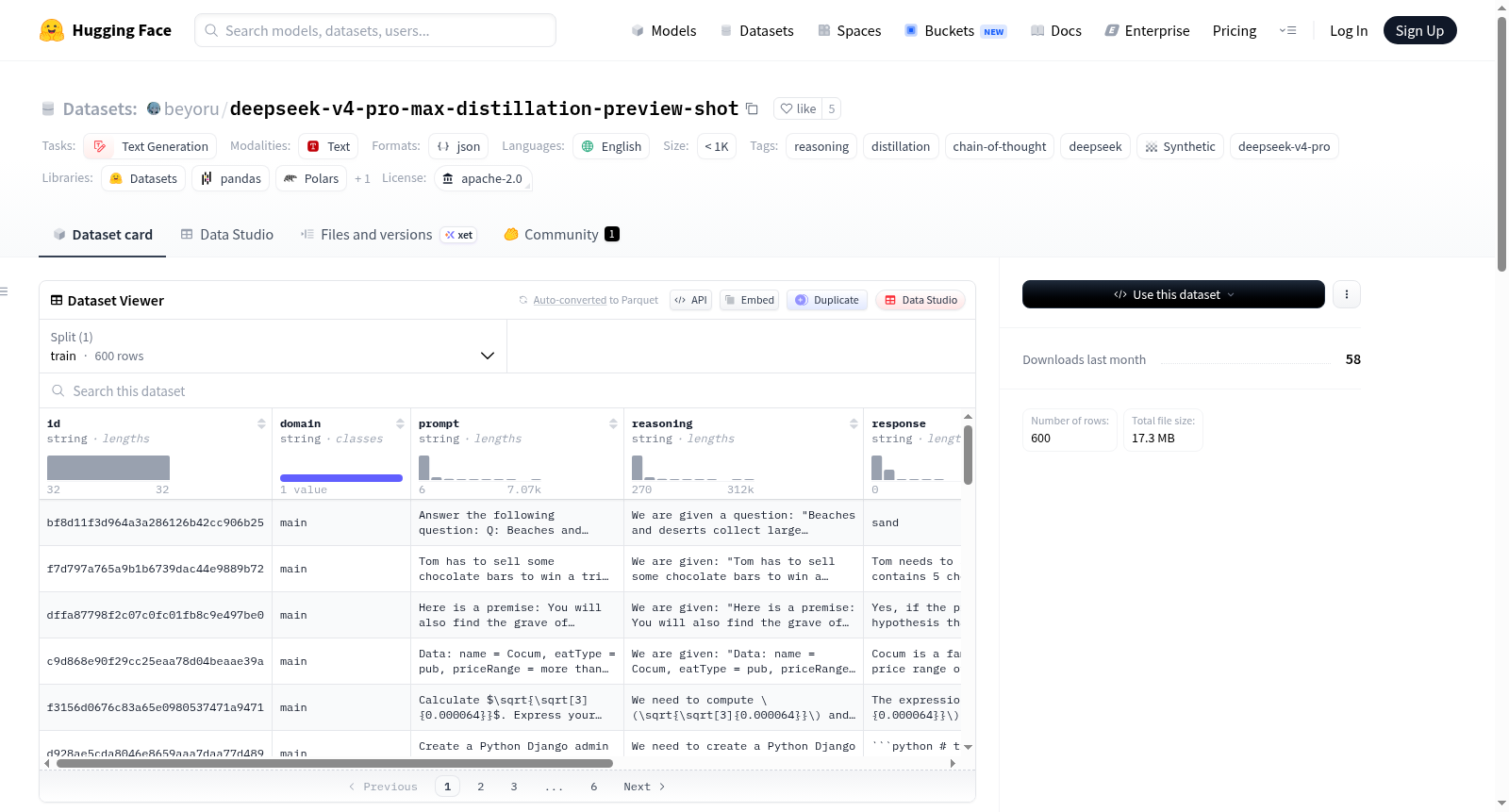
该数据集包含由DeepSeek-V4-Pro生成的推理轨迹和最终答案,使用来自Jackrong/GLM-5.1-Reasoning-1M-Cleaned数据集的提示样本。数据集旨在进行质量检查,并计划在2026年4月26日更新至1000个样本。数据集包含500个样本,主要语言为英语,部分包含中文或多语言STEM内容。数据格式为JSON Lines(output.jsonl)。每个JSON对象包含以下字段:id(原始数据集的MD5哈希)、domain(来源子集:main/PHD-Science/Multilingual-STEM/Math)、prompt(用户提示,来自源数据集的input字段)、reasoning(DeepSeek生成的思维链)、response(最终答案)、model(deepseek-v4-pro)和usage(令牌使用情况)。
创建时间:
2026-04-24
原始信息汇总
数据集概述:deepseek-v4-pro-max-distillation-preview-shot
基本信息
- 许可证:Apache-2.0
- 语言:主要使用英语,包含部分中文/多语言STEM内容
- 任务类别:文本生成
- 标签:推理、蒸馏、思维链、DeepSeek、合成数据
- 数据集规模:小于1K样本
数据集规模与来源
| 项目 | 内容 |
|---|---|
| 样本数量 | 500条 |
| 提示词来源 | Jackrong/GLM-5.1-Reasoning-1M-Cleaned 数据集的train拆分(取前500行,流式读取) |
| 教师模型 | deepseek-v4-pro(推理努力度=最大值,启用了thinking) |
| 格式 | JSON Lines(output.jsonl) |
数据集结构
每条数据为JSON对象,包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
id |
string | 原始数据集的MD5哈希值 |
domain |
string | 来源子集:main / PHD-Science / Multilingual-STEM / Math |
prompt |
string | 用户提示词(来自源数据集的input字段) |
reasoning |
string | DeepSeek生成的思维链推理过程(message.reasoning_content) |
response |
string | 最终答案(message.content) |
model |
string | 固定值:deepseek-v4-pro |
usage |
object | 令牌使用统计(包含prompt_tokens、completion_tokens、reasoning_tokens等) |
目的与更新计划
- 当前目标:仅用于质量检查
- 更新计划:预计在2026年4月26日更新至1000个样本
搜集汇总
数据集介绍
构建方式
本数据集由DeepSeek-V4-Pro模型通过蒸馏技术构建而成,其推理过程设定为最大推理深度(reasoning_effort=max)并启用了思考模式(thinking.enabled=true)。数据集的提示样本来源于Jackrong/GLM-5.1-Reasoning-1M-Cleaned数据集的训练分割部分,仅取前500条样本以进行质量验证。每条样本均包含原始提示、模型生成的思维链推理过程、最终答案及详细的token使用统计,格式为JSON Lines,便于后续处理与分析。
特点
该数据集规模精巧,仅含500条样本,但覆盖了数学、PHD-Science、Multilingual-STEM及主领域等多个知识域,语言以英语为主,兼有中文及多语言STEM内容。其核心价值在于提供了DeepSeek-V4-Pro在最大推理努力下的完整推理轨迹,包括详细的思维链内容与token消耗记录,为评估高级推理模型的性能与行为提供了高质量的参考基准。此外,数据集采用Apache-2.0许可,开放性强。
使用方法
数据集以标准JSON Lines格式存储,每行包含id、domain、prompt、reasoning、response、model及usage等字段。用户可直接使用Python的json库逐行读取,提取prompt作为输入,将reasoning与response分别作为思维链标签与最终答案标签,用于监督微调或推理链分析。usage字段中的token统计可用于计算推理成本或优化模型调用策略。该数据集尤其适合用于蒸馏研究的对比实验与模型输出的质量审计。
背景与挑战
背景概述
在大型语言模型飞速演进的当下,知识蒸馏与思维链推理已成为提升模型性能的关键技术路径。DeepSeek-V4-Pro-Max-Distillation-Preview-Shot数据集于2026年由相关研究团队创建,依托DeepSeek-V4-Pro这一先进教师模型,从GLM-5.1-Reasoning-1M-Cleaned数据集中精心采样500条推理轨迹与最终答案,旨在探索高质量蒸馏样本对模型推理能力的塑造作用。该数据集聚焦于多领域STEM内容与多语言场景,其发布为后续更大规模(计划扩展至1000条样本)的蒸馏数据构建奠定了方法论基础,对推动轻量化推理模型的研发具有重要示范意义。
当前挑战
当前该数据集面临的核心挑战涵盖两大层面。其一,在领域问题层面,尽管思维链蒸馏已被证实能有效迁移推理能力,但如何从教师模型中提取出对下游任务泛化性最强的推理轨迹,以及如何避免蒸馏过程中教师错误知识(如幻觉)被放大,仍是未竟之题。其二,在构建过程中,数据集仅包含500条样本,规模过小难以支撑鲁棒的模型训练与评估;同时,数据来源单一依赖于GLM-5.1数据集的清理版本,可能导致领域覆盖的偏差,且计划中的更新(1000条样本)尚未完成,限制了其在更复杂推理任务上的适用性。
常用场景
经典使用场景
该数据集专为高级推理与链式思维(Chain-of-Thought)蒸馏研究而设计,其经典使用场景在于利用DeepSeek-V4-Pro模型生成的高质量推理痕迹与最终答案,对小型模型进行知识蒸馏。通过提供‘max’推理努力程度下的丰富思维链,研究者能有效训练轻量级模型模仿复杂推理过程,从而在资源受限环境下提升模型的逻辑推导与逐步解决问题的能力。此外,数据集的领域涵盖数学、多语言STEM及PHD科学等高难度主题,使其成为评估和增强模型在专业学术推理任务上表现的理想基准。
解决学术问题
在自然语言处理领域,大规模语言模型虽展现出惊人推理能力,但其高昂的计算成本与封闭的推理过程限制了研究。该数据集巧妙地解决了蒸馏研究中高质量推理数据稀缺的瓶颈,为研究者提供了经过DeepSeek-V4-Pro精心标注的思维链与答案对,使得探索‘推理能力的可迁移性’成为可能。它支撑起从模型压缩、跨领域推理泛化到链式思维机制解析等一系列学术探索,推动了关于‘为何链式思维能提升准确性’以及‘蒸馏过程中的知识损失与保留’等关键问题的深入理解,具有里程碑式的实验支撑价值。
衍生相关工作
该数据集的诞生催生了若干重要的衍生研究方向。其一,基于其推理痕迹的可解释性,衍生了‘思维链可视化与错误定位’研究,旨在剖析模型推理路径中的逻辑谬误。其二,针对其多领域覆盖特性,涌现出‘跨学科推理迁移’的工作,探索如何将一个领域的推理模式应用于另一个陌生领域。其三,以该数据为标杆,研究者构建了‘推理努力程度与质量关系’的评估框架,系统性地对比不同‘reasoning_effort’设置下的蒸馏效果。最后,数据集的持续更新计划也为‘增量式知识蒸馏’与‘终身学习推理’等前沿课题提供了宝贵的标准评估集。
以上内容由遇见数据集搜集并总结生成


