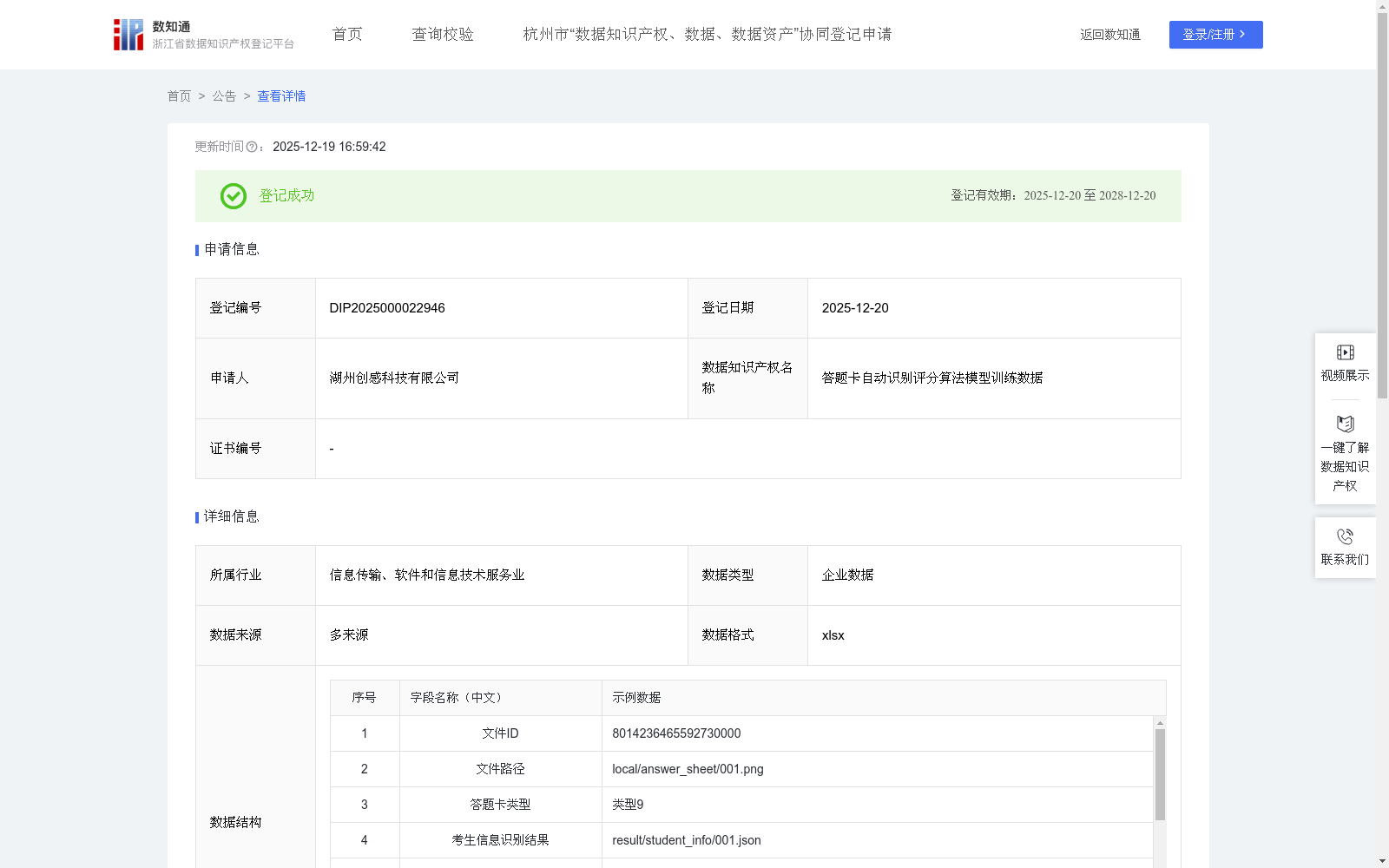
答题卡自动识别评分算法模型训练数据
收藏浙江省数据知识产权登记平台2025-12-19 更新2025-12-20 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8416773
下载链接
链接失效反馈官方服务:
资源简介:
随着现代化信息技术的发展,在答题卡阅卷领域已逐步实现计算机取代人工阅卷。计算机阅卷的优点:不但加快了阅卷速度,而且节约了人力资源,避免了人为错误的产生,增加了考试的公平性,进而提高了阅卷质量和效率。计算机识别答题卡后,还能直接读取学生的成绩进行存储并建立数据库,方便长久保存,省去了手工输入学生成绩的步骤。此外,学生答题卡图像识别技术能够和许多信息化技术相融合,便捷地获取答题成绩,进而将其应用到不同的教研系统中进行数据共享,方便数据分析,找出教学中存在的问题从而改进教学方法,具有非常重要的现实意义。1. 数据采集:通过多种途径收集获得历史主流答题卡模板,为保证数据集的训练数据量和多样性,通过对部分答题卡设计各种不同的干扰项,模拟不同光照条件,引入各类干扰因素。对所有的训练数据进行随机排序并设置文件ID。
2. 文件处理:使用PyTorch进行文件预处理,初始化并设置合理参数、数据集训练集路径和测试集路径。使用Hough变换对图像进行倾斜校正,保证文件的导入opencv对文件进行轮廓检测,确定答题卡的样式类型所属。使用label-studio对答题卡进行区域标注,分辨出答题卡的考生信息、选择题、填空题和主观题,得到需要识别的数据图片并对其进行分类和编号标记,确保答题卡后期总分计算等一系列处理。
3. 文件数据识别:因为主观题有多种解法和描述,目前只能人工审核,所以我们只针对考生信息、选择题和填空题进行训练识别。考生基本信息为准考证号+学生姓名,对考生信息通过ocr文字识别,获取到识别后的考生基本信息并整合为json文件,保存至student_info文件夹中。选择题通过图像平滑滤波+opencv技术识别,得到选择题的答案,对其进行整合为json文件,保存至choice_questions文件夹中。填空题使用ocr文字识别技术,得到各个填空题的答案,整合为json文件,并把它保存至fill_blank文件夹中。
4. 模型训练:通过文件数据识别得到的结果和答案进行对比,使用YOLOv10模型进行训练,将模型不断调整权重,固定学习率和批量大小的值,优化训练损失和验证损失,并且记录训练的训练时长。在训练过程中,模型的训练精度随着训练进度会逐步上升。
5. 模型评估:使用测试集对模型进行评估,计算模型在不同的样本数据下识别的训练精度、召回率、F1值、以及实时性能评估等性能指标,确保了模型的准确性与适应性。
6. 模型应用:将最终训练后得到的模型应用到实际具体的项目中。在实际应用中,通过对不同种类的答题卡进行针对性调整,确保模型识别的速率和准确性。
With the development of modern information technology, computerized grading has gradually replaced manual grading in the field of answer sheet marking. The advantages of computerized grading include speeding up grading efficiency, saving human resources, eliminating human errors, enhancing examination fairness, and thus improving overall grading quality and efficiency. After the computer identifies the answer sheets, it can directly read students' scores for storage and establish a database for long-term preservation, eliminating the need for manual score entry. In addition, answer sheet image recognition technology can be integrated with various information technologies to conveniently obtain test scores, which can then be applied to different teaching and research systems for data sharing, facilitating data analysis, identifying existing problems in teaching to improve teaching methods, and thus holding extremely important practical significance.
1. Data Collection: Collect historical mainstream answer sheet templates through multiple channels. To ensure the training data volume and diversity of the dataset, we add various interference items to some answer sheets, simulate different lighting conditions, and introduce various interference factors. All training data are randomly sorted and assigned file IDs.
2. File Processing: Use PyTorch for file preprocessing, initialize and set reasonable parameters, as well as the training set path and test set path of the dataset. Use Hough Transform to perform tilt correction on images to ensure correct file import, then use OpenCV to conduct contour detection and determine the style and type of the answer sheet. Use Label Studio to annotate regions of the answer sheet, distinguish examinee information, multiple-choice questions, fill-in-the-blank questions and subjective questions, obtain the required recognition data images, classify and number them, to facilitate subsequent processing such as total score calculation of the answer sheets.
3. File Data Recognition: Since subjective questions have multiple solutions and descriptions, manual review is currently required, so we only train and recognize examinee information, multiple-choice questions and fill-in-the-blank questions. The basic examinee information includes admission ticket number and student name. Perform OCR on the examinee information to obtain the recognized basic examinee information, integrate it into a JSON file, and save it to the student_info folder. For multiple-choice questions, use image smoothing filtering plus OpenCV technology to identify the answers, integrate them into a JSON file, and save it to the choice_questions folder. For fill-in-the-blank questions, use OCR technology to obtain the answers of each fill-in-the-blank question, integrate them into a JSON file, and save it to the fill_blank folder.
4. Model Training: Compare the results obtained from file data recognition with standard answers, use the YOLOv10 model for training, continuously adjust the model weights, fix the values of learning rate and batch size, optimize training loss and validation loss, and record the training duration. During the training process, the model's training accuracy will gradually improve as the training progresses.
5. Model Evaluation: Use the test set to evaluate the model, calculate performance indicators such as recognition accuracy, recall rate, F1 score and real-time performance of the model under different sample data, so as to ensure the accuracy and adaptability of the model.
6. Model Application: Apply the final trained model to practical specific projects. In practical applications, make targeted adjustments to different types of answer sheets to ensure the model's recognition speed and accuracy.
提供机构:
湖州创感科技有限公司
创建时间:
2025-09-24
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于训练答题卡自动识别评分算法模型的训练数据,由湖州创感科技有限公司登记,包含2683条xlsx格式记录,涵盖答题卡图像文件、识别结果(如考生信息、选择题和填空题)、正确答案以及YOLOv10模型的训练参数和性能指标(如训练精度、召回率)。其特点是模拟不同干扰条件进行数据采集,通过图像处理和OCR技术实现自动化识别,旨在提升计算机阅卷的效率和准确性,支持教育领域的数据分析和教学改进。
以上内容由遇见数据集搜集并总结生成


