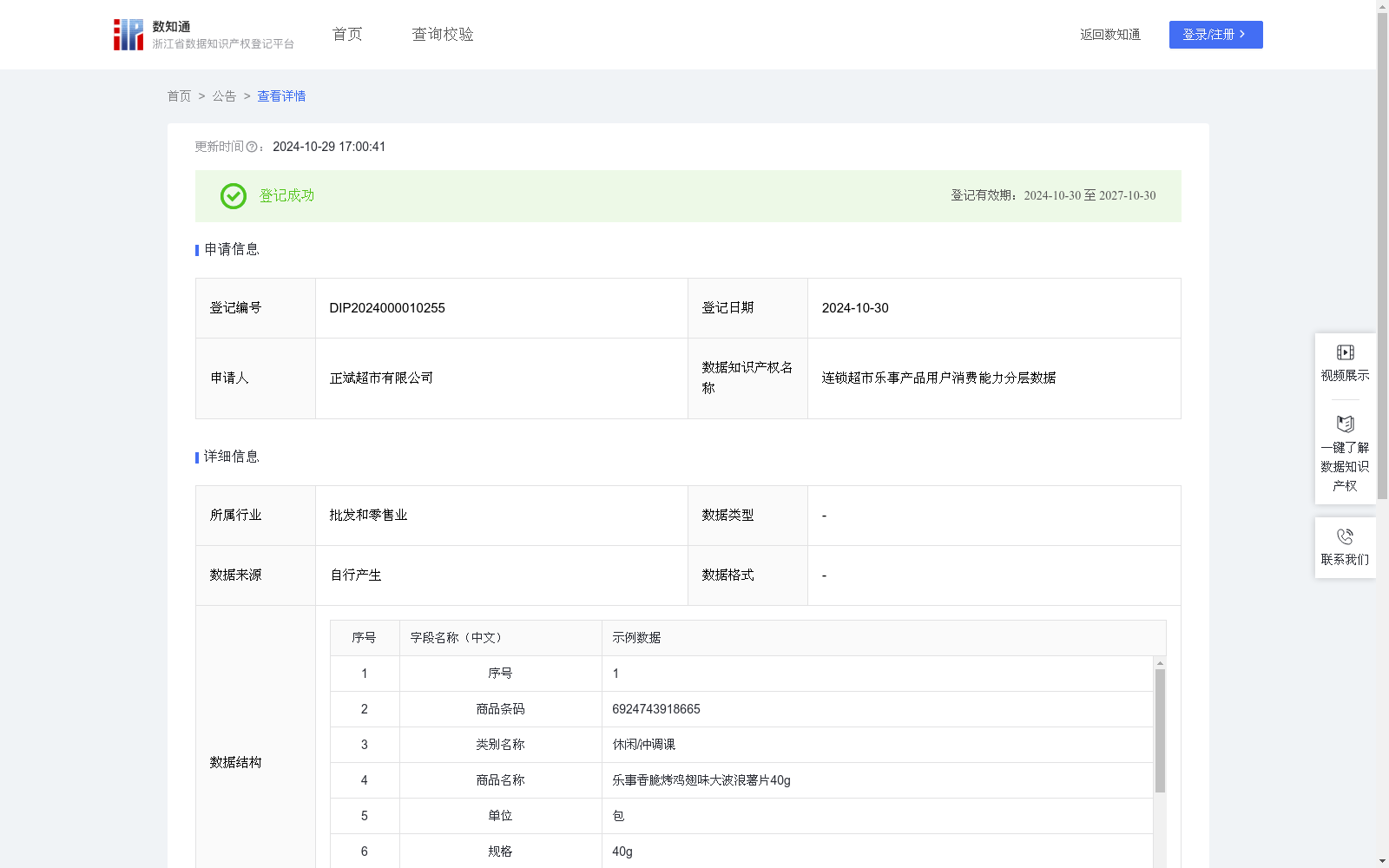
连锁超市乐事产品用户消费能力分层数据
收藏浙江省数据知识产权登记平台2024-10-29 更新2024-10-30 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/77735
下载链接
链接失效反馈官方服务:
资源简介:
为了更有效地管理连锁超市在台州各地的产品周转,并制定更有针对性的产品营销策略。超市可通过对历史下单用户画像建立,对用户进行标签制定,定位用户消费级别,为超市在台州各地设立产品周转仓及针对各地区消费者对乐事产品的销售量和销售额,制定营销策略提供数据支持,从而帮助超市更准确地掌握产品市场动态,提升客户满意度和竞争力。1.数据采集:对超市用户一个月乐事产品销售数量、销售金额做数据记录。2.数据处理:销售乐事该规格产品金额占总销售乐事产品金额的比例=销售该规格乐事产品金额/总销售乐事产品数量*100%;3.数据分类:该规格产品占该类产品总消费的比例按从大到小进行排名。消费分类运用ABCDEF分类法,对占比大于等于0.2%以上,给予“A类消费”分层;占比在小于0.2%到大于等于0.15%区间,则给予“B类消费”分层;占比在小于0.15%到大于等于0.1%区间,则给予“C类消费”分层;占比在小于0.1%到大于等于0.05%区间,则给予“D类消费”分层;占比在小于0.05%到大于等于0.01%区间,则给予“E类消费”分层;占比在小于0.01%以下,则给予“F类消费”分层。4.数据应用:通过这样的分析流程,超市不仅能够更准确地把握市场动态和客户喜好,还能够有效提升客户满意度和市场竞争力。
To more effectively manage product turnover of chain supermarkets across Taizhou and formulate more targeted product marketing strategies, supermarkets can establish user portraits based on historical order data, develop user tags, and classify user consumption levels. This provides data support for supermarkets to set up product turnover warehouses across Taizhou and formulate marketing strategies tailored to regional consumers' sales volume and sales amount of Lay's products, thereby helping supermarkets accurately grasp product market dynamics, improve customer satisfaction and market competitiveness.
1. Data Collection: Record the sales volume and sales amount of Lay's products of supermarket users over a one-month period.
2. Data Processing: Calculate the proportion of the sales amount of Lay's products of a specific specification in the total sales amount of all Lay's products using the formula: (sales amount of the specific specification Lay's products / total sales quantity of all Lay's products) × 100%.
3. Data Classification: Rank the proportion of the specific specification product in the total consumption of its category in descending order. Adopt the ABCDEF classification method for consumption stratification: assign "Class A consumption" to products with a proportion greater than or equal to 0.2%; assign "Class B consumption" to products with a proportion less than 0.2% and greater than or equal to 0.15%; assign "Class C consumption" to products with a proportion less than 0.15% and greater than or equal to 0.1%; assign "Class D consumption" to products with a proportion less than 0.1% and greater than or equal to 0.05%; assign "Class E consumption" to products with a proportion less than 0.05% and greater than or equal to 0.01%; assign "Class F consumption" to products with a proportion less than 0.01%.
4. Data Application: Through such an analytical process, supermarkets can not only accurately grasp market trends and customer preferences, but also effectively enhance customer satisfaction and market competitiveness.
提供机构:
正斌超市有限公司
创建时间:
2024-09-27
搜集汇总
数据集介绍
特点
该数据集记录了连锁超市乐事产品的销售数据,包括商品信息、销售数量和金额等,通过ABCDEF分类法对用户消费能力进行分层,旨在帮助超市优化产品周转和营销策略。
以上内容由遇见数据集搜集并总结生成


