nli-chatbot-prompt-categorization
收藏Hugging Face2024-12-05 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/reddgr/nli-chatbot-prompt-categorization
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含聊天机器人提示,这些提示被标注了自然语言推理(NLI)类别的假设和标签。主要目的是对聊天机器人对话进行自然语言推理分类。类别假设是根据聊天机器人对话中最相关和最常用的内容选择的,这些对话的语言环境和主要用例通常与从新闻、科学文章、新闻出版物等来源的最受欢迎的NLI数据集中的文本模式和类别有很大不同。
This dataset comprises chatbot prompts annotated with hypotheses and labels for natural language inference (NLI) categories. Its primary purpose is to perform natural language inference classification on chatbot conversations. The category hypotheses are selected based on the most relevant and frequently used content in chatbot dialogues. The linguistic contexts and core use cases of these dialogues typically differ significantly from the text patterns and categories found in the most popular NLI datasets sourced from materials such as news, scientific articles, and news publications.
创建时间:
2024-12-05
原始信息汇总
数据集概述
数据集信息
- 许可证: Apache 2.0
- 特征:
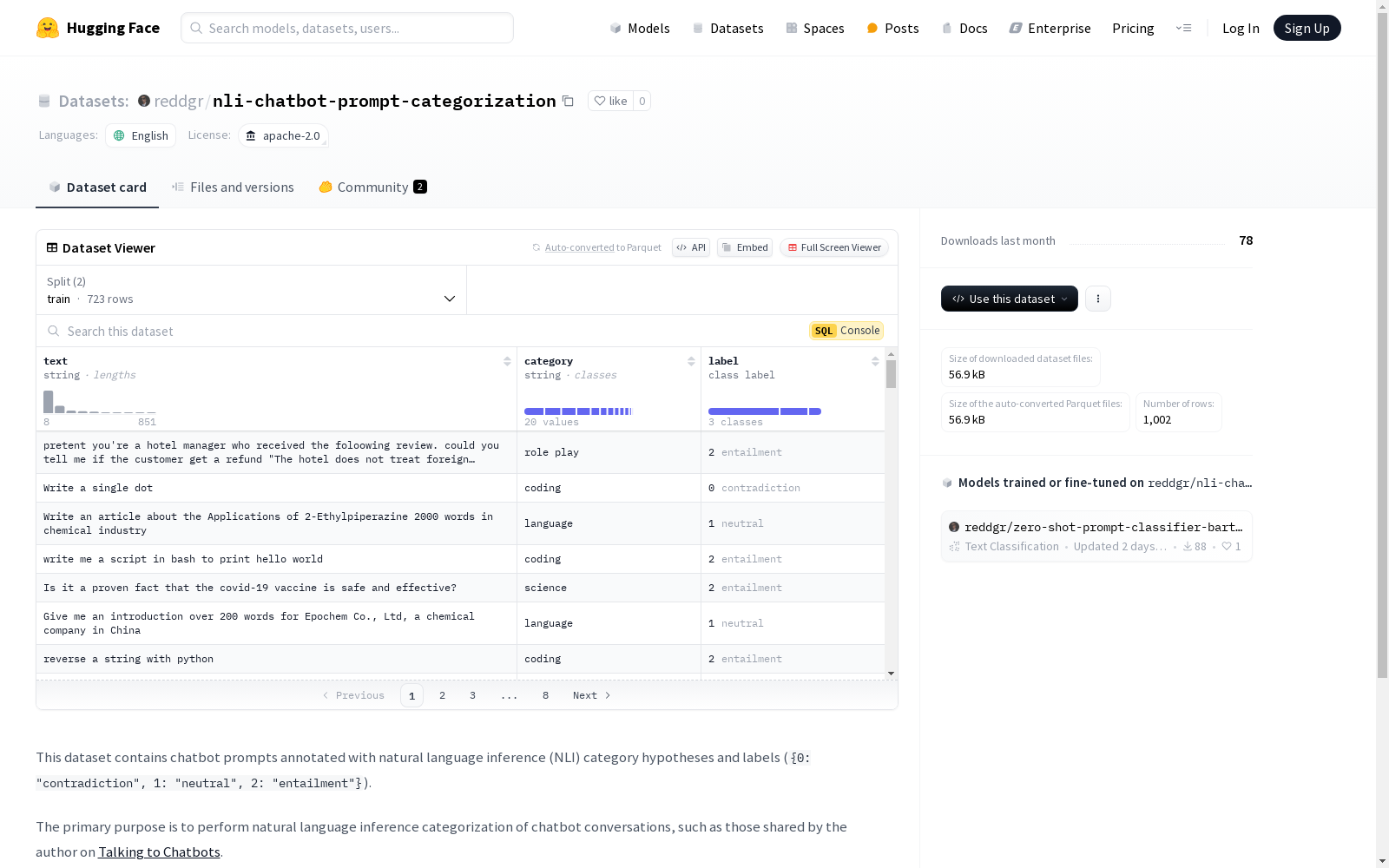
text: 文本类型,字符串category: 分类类型,字符串label: 标签类型,包含三个类别:0: 矛盾 (contradiction)1: 中性 (neutral)2: 蕴含 (entailment)
- 分割:
train: 训练集,包含207个样本,大小为30026字节test: 测试集,包含171个样本,大小为22534字节
- 下载大小: 28923字节
- 数据集大小: 52560字节
配置
- 配置名称:
default- 数据文件:
train:data/train-*test:data/test-*
- 数据文件:
数据集用途
- 主要用途: 用于自然语言推理(NLI)分类,特别是针对聊天机器人的对话进行分类。
- 类别假设: 类别假设(如语言、编码、角色扮演、科学等)是根据聊天机器人对话的上下文和主要用例选择的,这些用例通常与从新闻、科学文章、新闻出版物等来源的最流行NLI数据集中的文本模式和类别有显著差异。
搜集汇总
数据集介绍
构建方式
该数据集的构建旨在为聊天机器人的自然语言推理(NLI)分类提供支持,通过对聊天对话中的提示进行标注,将其分为矛盾、中立和蕴含三类。数据集的构建过程中,选择了与聊天机器人对话场景最为相关的类别假设,如语言、编码、角色扮演、科学等,以确保其语言上下文和主要使用场景与传统NLI数据集(如新闻、科学文章等)有显著差异。
使用方法
该数据集可用于训练和评估自然语言推理模型,特别是在聊天机器人对话场景中的应用。用户可以通过加载数据集的训练和测试分割,利用其中的文本、类别和标签特征进行模型训练和验证。数据集的结构设计使其适用于多种机器学习框架,便于研究人员和开发者进行实验和应用。
背景与挑战
背景概述
在自然语言处理领域,对话系统的自然语言推理(NLI)分类任务一直是研究的热点。nli-chatbot-prompt-categorization数据集由主要研究人员或机构创建,旨在解决对话系统中自然语言推理分类的特定问题。该数据集的核心研究问题是如何在聊天机器人对话的特定语境中,准确地对提示进行分类,包括矛盾、中立和蕴含等类别。通过引入这一数据集,研究人员能够更好地理解和处理聊天机器人对话中的语言模式,从而提升对话系统的交互质量和推理能力。
当前挑战
构建nli-chatbot-prompt-categorization数据集面临的主要挑战包括:首先,聊天机器人对话的语言环境和使用场景与传统NLI数据集(如新闻、科学文章等)有显著差异,因此需要重新定义和选择相关类别假设。其次,数据标注的准确性和一致性是一个关键问题,因为不同标注者可能对同一对话提示的理解存在差异。此外,如何在有限的训练数据中实现高效的模型训练,以确保分类的准确性和鲁棒性,也是该数据集面临的重要挑战。
常用场景
经典使用场景
nli-chatbot-prompt-categorization数据集的经典使用场景在于其能够对聊天机器人的对话进行自然语言推理(NLI)分类。通过分析对话中的文本,数据集将对话内容划分为矛盾(contradiction)、中性(neutral)和蕴含(entailment)三类,从而帮助研究人员和开发者更好地理解和处理聊天机器人中的对话逻辑。
解决学术问题
该数据集解决了在聊天机器人领域中,如何有效分类和推理对话内容的学术问题。传统的NLI数据集多来源于新闻、科学文章等,而聊天机器人的对话内容具有独特的语言模式和应用场景。nli-chatbot-prompt-categorization通过提供专门针对聊天机器人对话的分类标签,填补了这一领域的研究空白,为提升聊天机器人的对话理解和推理能力提供了重要支持。
实际应用
在实际应用中,nli-chatbot-prompt-categorization数据集可用于优化聊天机器人的对话管理系统。通过准确分类对话内容,系统能够更好地理解用户意图,提供更精准的回复,从而提升用户体验。此外,该数据集还可用于训练和评估自然语言处理模型,特别是在需要处理复杂对话逻辑的场景中,如客户服务、教育辅导等。
数据集最近研究
最新研究方向
在自然语言处理领域,nli-chatbot-prompt-categorization数据集的最新研究方向主要集中在对话系统中的自然语言推理(NLI)任务上。该数据集通过为聊天机器人对话提供分类标注,旨在解决传统NLI数据集在处理聊天机器人对话时所面临的语言模式和上下文差异问题。研究者们正探索如何利用这一数据集提升聊天机器人对话的推理能力,特别是在多轮对话中的上下文理解和推理准确性方面。这一研究不仅有助于提升聊天机器人的交互质量,还为开发更智能、更自然的对话系统提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


