human-style-preferences-images
收藏Hugging Face2024-12-12 更新2024-12-13 收录
下载链接:
https://huggingface.co/datasets/Rapidata/human-style-preferences-images
下载链接
链接失效反馈官方服务:
资源简介:
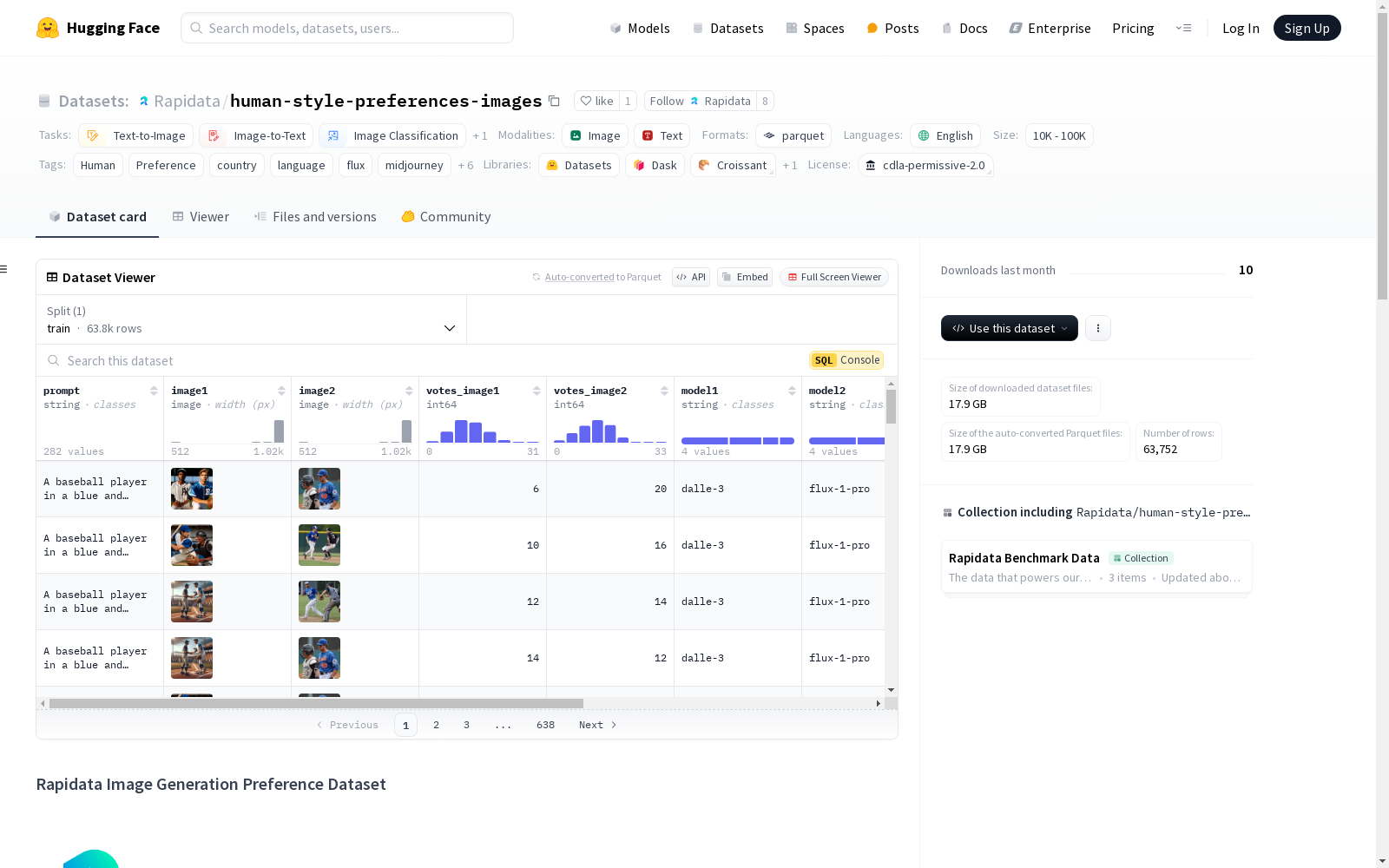
这是一个用于文本到图像模型的人类偏好数据集,包含了超过1,200,000个人类偏好投票。数据集的特征包括大规模、全球代表性、多样化的提示以及对领先图像生成模型的比较。数据集的应用包括基准测试新图像生成模型、开发更好的生成模型评估指标、理解全球偏好、训练和微调图像生成模型以及研究跨文化美学偏好。数据集的收集过程使用了Rapidata的创新标注平台,能够在短时间内大规模收集数据。
This is a human preference dataset for text-to-image models, containing over 1,200,000 human preference votes. The dataset features large-scale, globally representative and diverse prompts, as well as comparisons of leading image generation models. Its applications include benchmarking new image generation models, developing better evaluation metrics for generative models, understanding global preferences, training and fine-tuning image generation models, and researching cross-cultural aesthetic preferences. The dataset was collected using Rapidata's innovative annotation platform, which enables large-scale data collection within a short timeframe.
创建时间:
2024-12-02
原始信息汇总
Rapidata Image Generation Preference Dataset
数据集概述
- 数据集名称: Rapidata Image Generation Preference Dataset
- 数据集大小: 26,229,461,236 字节
- 下载大小: 17,935,847,407 字节
- 样本数量: 63,752 个样本
- 语言: 英语
- 标签: Human, Preference, country, language, flux, midjourney, dalle3, stabeldiffusion, alignment, flux1.1, flux1, imagen3
- 任务类别:
- 文本生成图像
- 图像生成文本
- 图像分类
- 强化学习
- 规模类别: 100K<n<1M
数据集特征
- prompt: 字符串类型
- image1: 图像类型
- image2: 图像类型
- votes_image1: 整数类型
- votes_image2: 整数类型
- model1: 字符串类型
- model2: 字符串类型
- detailed_results: 字符串类型
- image1_path: 字符串类型
- image2_path: 字符串类型
数据集配置
- 配置名称: default
- 数据文件:
- 训练集: data/train-*
数据集应用
- 基准测试新的图像生成模型
- 开发更好的生成模型评估指标
- 理解全球范围内对AI生成图像的偏好
- 训练和微调图像生成模型
- 研究跨文化审美偏好
数据集特点
- 大规模: 超过1,200,000个人类偏好投票,收集时间不到100小时
- 全球代表性: 从全球参与者中收集
- 多样化提示: 精心策划的提示测试图像生成的各个方面
- 领先模型: 比较最先进的图像生成模型
数据集许可
- 许可证: cdla-permissive-2.0
搜集汇总
数据集介绍
构建方式
该数据集通过Rapidata的Python API在短短四天内收集而成,利用其高效的注释平台,实现了大规模数据收集。数据集包含了超过120万个人类偏好投票,涵盖了全球范围内的参与者,确保了数据的广泛代表性。通过精心设计的提示,测试了多种图像生成模型的不同方面,从而构建了一个全面且多样化的偏好数据集。
特点
该数据集的主要特点在于其大规模和全球代表性。数据集包含了超过120万个人类偏好投票,这些投票在不到100小时内收集完成,展示了Rapidata平台在数据收集速度上的优势。此外,数据集涵盖了来自全球145多个国家的参与者,确保了跨文化的多样性。数据集还包含了多种领先图像生成模型的比较,如Imagen-3、Flux-1.1、Dalle-3等,为研究不同模型间的性能差异提供了丰富的资源。
使用方法
该数据集可广泛应用于多个领域,包括但不限于:基准测试新的图像生成模型、开发更优的生成模型评估指标、理解全球范围内对AI生成图像的偏好、训练和微调图像生成模型,以及研究跨文化的美学偏好。用户可以通过Rapidata的Python API轻松访问和分析数据,利用这些数据进行模型优化和研究。
背景与挑战
背景概述
在人工智能生成图像领域,随着模型如Midjourney、DALL-E 3、Stable Diffusion等的快速发展,评估和优化这些模型生成图像的质量成为关键问题。human-style-preferences-images数据集由Rapidata公司主导,于短时间内收集了超过120万条人类对不同生成模型输出图像的偏好投票。该数据集不仅涵盖了全球范围内的参与者,还包含了多样化的提示词,用以测试图像生成的各个方面。通过对比多个领先模型的表现,该数据集为图像生成模型的基准测试、评估指标开发以及跨文化美学偏好的研究提供了宝贵的资源。
当前挑战
该数据集在构建过程中面临的主要挑战包括:首先,如何在短时间内收集大规模的全球性数据,确保数据的多样性和代表性;其次,如何设计有效的提示词以全面测试图像生成模型的能力;最后,如何在保证数据质量的同时,实现快速且成本效益高的数据收集。此外,该数据集的应用也面临挑战,如如何利用这些偏好数据开发更精确的评估指标,以及如何通过这些数据训练和优化生成模型,以更好地反映全球用户的审美偏好。
常用场景
经典使用场景
该数据集在图像生成模型的评估与优化中展现了其经典应用场景。通过收集全球范围内用户对不同生成模型所产生图像的偏好投票,研究者能够量化并比较各模型在特定提示下的表现。这种基于人类偏好的评估方法,不仅为模型间的性能对比提供了客观依据,还为模型参数的微调提供了方向性指导。
衍生相关工作
基于该数据集,研究者们开展了多项经典工作,包括开发新的评估指标以量化人类偏好、设计跨文化审美模型以及探索生成模型的可解释性。这些研究不仅深化了对图像生成技术的理解,还为后续的模型改进和应用拓展奠定了基础。
数据集最近研究
最新研究方向
在图像生成领域,human-style-preferences-images数据集的最新研究方向主要集中在通过大规模的人类偏好投票来优化和评估文本到图像生成模型的性能。该数据集不仅提供了对多种先进模型(如Dalle-3、Midjourney、Stable Diffusion等)的比较,还揭示了全球不同文化背景下用户对AI生成图像的审美偏好。这一研究方向有助于开发更精准的评估指标,推动生成模型在跨文化场景中的适应性,并为模型训练和微调提供了宝贵的反馈数据。此外,该数据集的应用还扩展到研究跨文化美学差异,为AI生成艺术的未来发展提供了新的视角和方法。
以上内容由遇见数据集搜集并总结生成


