synthweb-qwen3-8b-multiscale-inference
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/cds-jb/synthweb-qwen3-8b-multiscale-inference
下载链接
链接失效反馈官方服务:
资源简介:
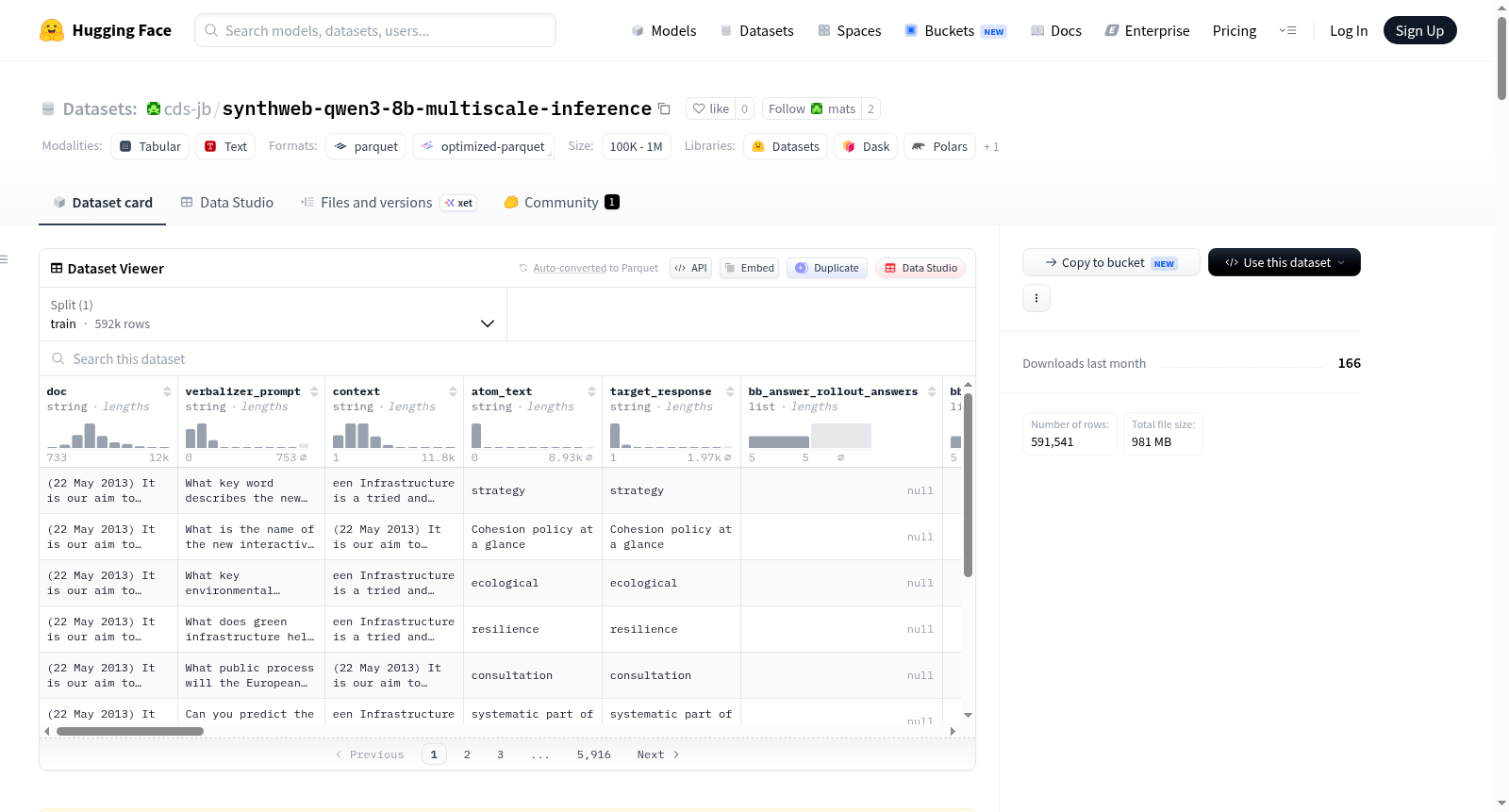
synthweb-qwen3-8b-multiscale-inference 是一个用于评估语言模型隐藏状态信息解码能力的探测问题数据集。该数据集基于 Qwen3-8B 模型对 FineWeb 文本前缀生成的续写内容构建,专门用于测试一种称为方法 M的激活预言机方法,该方法旨在从模型在文本分割点处的隐藏状态中恢复尚未在表面文本中显现的内容。数据集的核心设计原则是确保每个探测问题同时满足两个关键约束:1) 难以从文本中推断,即仅通过分割另一侧的文本无法可靠得出答案;2) 易于从潜在状态中推断,即答案应是源语言模型在分割点处已在其隐藏状态中承诺即将生成的内容。数据集共包含 591,541 个探测问题,覆盖五个不同粒度的范围组:单词(185,220个)、镜头(185,040个)、句子(110,995个)、段落(74,073个)和整体(35,679个)。每个源文档(FineWeb 前缀及其 Qwen3-8B 续写)最多生成16个探测问题,分配规则为:5个单词、5个镜头、3个句子、2个段落和1个整体探测。对于句子、段落和整体范围的探测,数据集还包含了由 Claude Haiku 4.5 模型生成的5次随机答案者回答以及对应的评判分数(0.0-1.0),其中最大分数是筛选难以从文本中推断探测的主要信号。数据集的每个数据行代表一个探测问题,包含丰富的元数据字段,如文档标识、字符分割偏移、目标侧、典型性标签、原子文本、提问提示、错误但合理的答案、协同性检查、分布检查、难度论证、生成模型、源模型、答案者回答与评分、完整信息下的正确答案以及上下文文本等。该数据集采用分轮次构建以确保可重复性和可扩展性,遵循与上游 FineWeb 数据集相同的许可证(ODC-By 1.0),适用于研究语言模型内部表示、激活解码和推理能力评估等任务。
The synthweb-qwen3-8b-multiscale-inference dataset is a probe question dataset designed to evaluate the hidden state information decoding capabilities of language models. This dataset is constructed from continuations generated by the Qwen3-8B model on FineWeb text prefixes, and is specifically tailored to test an activation oracle method named Method M, which aims to recover content that has not yet appeared in the surface text from the model’s hidden states at text split points.
The core design principle of the dataset is to ensure that each probe question satisfies two key constraints: 1) Difficulty to infer from text: the answer cannot be reliably derived solely from the text on the opposite side of the split; 2) Ease of inference from latent states: the answer should be the content that the source language model has committed to generating imminently in its hidden states at the split point.
The dataset contains a total of 591,541 probe questions, covering five range groups with distinct granularities: words (185,220), shots (185,040), sentences (110,995), paragraphs (74,073), and full-length texts (35,679). Each source document (the FineWeb prefix and its Qwen3-8B-generated continuation) yields up to 16 probe questions, following the allocation rule: 5 word-level, 5 shot-level, 3 sentence-level, 2 paragraph-level, and 1 full-level probe questions.
For probes at the sentence, paragraph, and full-length levels, the dataset also includes 5 random responses generated by the Claude Haiku 4.5 model, along with their corresponding judgment scores (ranging from 0.0 to 1.0). The maximum score among these serves as the primary signal for filtering probe questions that are difficult to infer from surface text.
Each data row in the dataset represents one probe question, with comprehensive metadata fields including document identifier, character split offset, target side, "typicality label", atomic text, query prompt, incorrect yet plausible answers, consistency check, distribution check, justification for difficulty, generation model, source model, answerer responses and scores, correct answer under full information, and context text, among others.
The dataset is constructed in rounds to ensure reproducibility and scalability, and adopts the same license (ODC-By 1.0) as the upstream FineWeb dataset. It is suitable for research tasks such as investigating internal representations of language models, activation decoding, and reasoning ability evaluation.
创建时间:
2026-05-13
原始信息汇总
数据集概述
数据集名称
synthweb-qwen3-8b-multiscale-inference
核心目的
该数据集是用于评估方法M(一种“激活解读器”,将隐藏状态内容解码为自然语言)的测试工具。每个数据行是一个探测问题,测试在字符级分割点的前缀+续写内容中,某一侧的信息能否从源语言模型的潜在隐藏状态中恢复出来。
关键约束
| 约束 | 描述 |
|---|---|
| HARD-FROM-TEXT | 仅从目标相反侧的文本中,无法自信得出答案(无逐字引用或清晰释义) |
| EASY-FROM-LATENT | 答案正是源语言模型在分割点隐藏状态中已承诺的内容 |
数据集规模
- 总探测数:591,541 个
- 源文档数:37,042 个(3 轮构建)
- 每文档插槽分配:16 个探测(5 单词 + 5 上下文窗口 + 3 句子 + 2 段落 + 1 全文)
探测范围分组(五个范围组)
| 范围 | 数量(本轮) | 原子(待恢复内容) | 评分方式 |
|---|---|---|---|
| word(单词) | 185,220 | 单个内容词 | 本地(精确匹配/标记对数概率) |
| lens(上下文窗口) | 185,040 | 分割点前后连续 N 个标记 | 本地(Qwen 分词器) |
| sentence(句子) | 110,995 | 一个完整句子 | Haiku 回答器 + 裁判 |
| paragraph(段落) | 74,073 | 一个段落 | Haiku 回答器 + 裁判 |
| whole(全文) | 35,679 | 半个文档(分割点一侧的所有段落) | Haiku 回答器 + 裁判 |
关键概念与字段
探测目标(target)
- prefix-target:方法 M 看到后缀,需回溯文档前部的原子
- suffix-target:方法 M 看到前缀,需预测文档后部的原子
典型性(typicality,仅 suffix-target)
- typical:该声明/事件在至少 3 个其他兄弟续写中重复出现
- atypical:该声明在所选兄弟中唯一,其他兄弟中不存在
不正确但合理的答案(IPA)
每个探测携带一个假设性的错误但合理的备选答案,用于对比评分(logP(atom) vs logP(IPA))
数据生成
| 属性 | 详情 |
|---|---|
| 生成模型 | Claude Haiku 4.5(claude-haiku-4-5-20251001) |
| 生成方式 | 扩展思考模式(8K 思考预算,28K 最大输出标记) |
| 校准等级 | 等级 -2(适度困难,确保文本读者有基础但具体内容需方法 M 恢复) |
| JSON 健壮性 | 约 1.3% 的响应存在 JSON 问题,通过 json-repair 修复,最终完成率从 86% 升至 98.8% |
评分机制
回答器 + 裁判(针对句子/段落/全文探测)
- 回答器:Haiku 4.5(temperature=1.0,max_tokens=800),5 次随机采样
- 裁判:另一个 Haiku 4.5 调用,输出 0.0–1.0 浮点分数
| 分数 | 含义 |
|---|---|
| 0.0 | 完全错误/无关 |
| 0.5 | 部分正确或主题正确但具体内容错误 |
| 1.0 | 与真实内容基本一致 |
最大分数直方图(本轮构建)
[0.0, 0.2) 26,852 (14.0%) HARD [0.2, 0.4) 40,599 (21.2%) [0.4, 0.6) 26,112 (13.6%) 谷值 [0.6, 0.8) 60,997 (31.8%) [0.8, 1.0] 37,301 (19.4%) EASY
- 平均值:0.503,标准差:0.289
- HARD(最大 < 0.4):35.2%
- EASY(最大 ≥ 0.8):19.4%
评分成本
- 191,792 个 spw 探测被评分
- 总计约 958,960 次回答器调用 + 958,960 次裁判调用
- 估计成本:约 1,019 美元(通过 Anthropic Message Batches API)
数据集模式(每行关键字段)
| 字段 | 类型 | 含义 |
|---|---|---|
doc_id |
str | FineWeb 派生的文档 ID |
doc_source |
str | 原始 FineWeb URL |
split_char_offset |
int | 该探测范围组的字符级分割偏移 |
scope |
str | 范围(word / lens / sentence / paragraph / whole) |
target |
str | 目标侧(prefix 或 suffix) |
atom_text |
str/null | 目标原子文本 |
verbalizer_prompt |
str/null | 探测问题 |
incorrect_plausible_answer |
str/null | 错误但合理的备选答案 |
bb_answer_score_max |
float/null | 主要过滤信号(5 次回答的最大分) |
target_response |
str | 完整信息下的正确答案 |
数据来源
- 源数据集:
cds-jb/synthweb-qwen3-8b(Qwen3-8B 对 FineWeb 前缀的续写) - 原始 FineWeb 数据集许可证:ODC-By 1.0
可复现性与增量构建
数据集按轮次构建,每轮采样新的文档 ID(与先前轮次不重叠),通过确定性种子确保无重叠。构建脚本包括提交、轮询、评分和提示构建等模块。
搜集汇总
数据集介绍
构建方式
该数据集基于Qwen3-8B模型对FineWeb语料前缀的续写结果构建,旨在评估一种名为‘激活神谕’的方法——该方法声称能从语言模型的隐藏态中解码出尚未显化为表面文本的信息。每个数据点对应一个探针,测试在字符级切分点两侧的内容能否从源语言模型的潜在隐藏态中恢复。数据集包含591,541个探针,跨越五个粒度组:单词、连续词块、句子、段落和整段。单词和词块探针通过Python模板生成,其余由Claude Haiku 4.5在扩展思维模式下编写,并遵循‘文本困难、潜在容易’的双重约束。Haiku为每个探针选择目标方向(前缀或后缀),并标注典型性(针对后缀目标),确保探针能有效区分文本可推导性与隐藏态带来的额外信息。
特点
数据集的核心特点是其精心设计的探针结构,每个探针同时携带硬文本约束和潜在态友好性度量。硬文本约束通过Big Brother评分系统量化——使用5次随机Haiku回答器滚动,取最高分作为过滤信号,分值低于0.4的探针被视为可直接保留用于评估。潜在态友好性则通过对比全信息回答(target_response)与盲回答(bb_answer_*)的差距来体现。此外,每个探针均包含一个‘错误但合理的答案’,用于对比评分,增强了评估的严谨性。数据集在句子、段落和整段粒度上还集成了协同性检查,确保多词原子需要综合整个片段的信息而非仅子区域。
使用方法
该数据集主要作为评估激活神谕方法的测试平台。用户可通过bb_answer_score_max字段筛选硬文本探针(建议阈值<0.4),保留的数据点用于衡量方法M相对于纯文本阅读器的增量能力。对于句子、段落和整段探针,可运行scripts/score_probes.py脚本重新评分,增加滚动次数以降低单次估计噪声。数据集按轮次构建,每轮采样新的文档ID,确保与之前轮次无重叠,支持增量扩展。用户可通过scripts/submit_multiscale_inference.py和scripts/poll_multiscale_inference.py提交和收集新轮次的数据。所有探针的atom_text、verbalizer_prompt、incorrect_plausible_answer等字段可直接用于对比评分和案例研究。
背景与挑战
背景概述
深植于可解释人工智能与大型语言模型内部机制探索的沃土,synthweb-qwen3-8b-multiscale-inference数据集于近期由研究团队基于Qwen3-8B模型对FineWeb数据前缀的续写结果构建而成。该数据集的核心研究问题聚焦于验证一种名为“激活神谕”的方法M,其声称能够从语言模型的潜在隐藏状态中解码出尚未显现在表面文本中的信息。通过精心设计的探测问题,该数据集旨在量化模型内部表征与输出文本之间的信息鸿沟,为理解语言模型如何进行“预决策”与隐式知识编码提供了关键的评估基准,在人工智能安全性与模型可解释性领域具有深远影响力。
当前挑战
该数据集面临的核心挑战在于精准构建满足双重约束的探测:探测必须“文本难度高”,即仅凭互补侧文本的审慎读者无法确切推断出目标答案,确保方法M的附加值可测;同时必须“隐藏状态易提取”,即目标答案恰好是源语言模型在字符切分点处已承诺于隐藏状态的内容。在构建过程中,团队需克服五类探针(词、序列、句、段、全篇)的协同约束,确保多标记原子需整合跨片段信息,并设计合理的错误但合理答案以进行对比评分。此外,大规模LLM批调用产生的约1020美元计算成本与1.3%的JSON解析异常率,亦构成了评估部署的现实壁垒。
常用场景
经典使用场景
该数据集核心服务于一种名为“激活预言机”(activation oracle)的方法论评估,旨在探测大语言模型隐藏状态中编码但尚未在表层文本中显现的信息。通过精心设计的探针(probe),数据集要求模型在字符级分割点处,基于源语言模型的潜在隐藏状态,恢复分割一侧的内容。每个探针都严格遵循“文本难解但潜在易解”的双重约束,即从互补文本侧无法轻易推断答案,而隐藏状态中已承诺该信息。这种设计使得synthweb-qwen3-8b-multiscale-inference成为衡量隐藏状态解码能力的标准测试集,广泛应用于表征分析、可解释性与模型内部机制研究。
衍生相关工作
围绕该数据集已衍生出一系列标杆性工作,其中最具代表性的是“激活预言机”方法的提出与迭代——该方法利用语言模型在分割点处的隐藏状态,解码出尚未输出的内容,其性能完全依赖synthweb-qwen3-8b-multiscale-inference提供的“文本难解”探针进行量化评价。研究者在数据集构建过程中开发的Haiku探针生成器、多轮校准策略(addendum levels)、以及基于JSON修复的数据打磨管道,已成为同类探针数据集的设计范式。此外,针对探针的“最大回答分数”直方图分析催生了硬探针筛选准则,后续工作在此基础上构建了对比性评分框架(正确答案对数概率与错误合理答案对数概率之差),并推动了对语言模型内部状态“预承诺”现象的系统性研究。
数据集最近研究
最新研究方向
该数据集聚焦于语言模型隐层状态的可解释性前沿,通过构建多尺度探测问题(词、句、段落、整篇),系统评估一种名为“激活神谕”的方法从隐层表征中解码未显式文本化信息的能力。其核心创新在于严格区分“文本困难”与“隐层容易”两类探测,利用Haiku 4.5生成的近60万条探针及五轮随机打分,实现对隐层信息恢复程度的量化标定。这一设计直指当前大模型推理“黑箱”难题,为理解模型内部知识承诺、追踪实体与叙事轨迹提供了高保真评估工具,其应用可能推动模型安全性解释、幻觉溯源与知识编辑等热点的技术突破。
以上内容由遇见数据集搜集并总结生成


