dp-bench
收藏Hugging Face2024-10-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/upstage/dp-bench
下载链接
链接失效反馈官方服务:
资源简介:
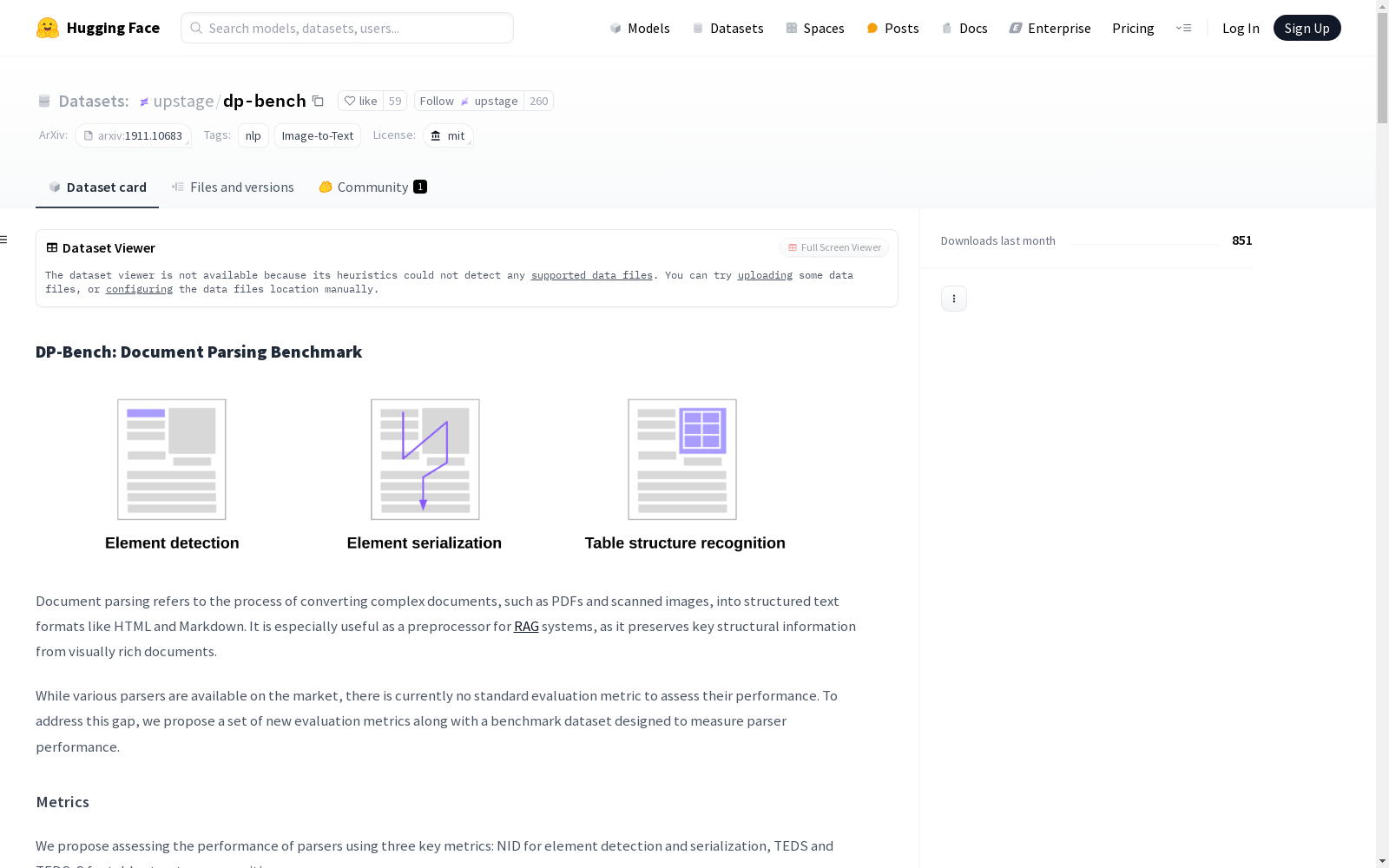
DP-Bench是一个用于文档解析的基准数据集,旨在评估解析器将复杂文档(如PDF和扫描图像)转换为结构化文本格式(如HTML和Markdown)的性能。数据集包含来自多个来源的样本,涵盖广泛的文档结构和复杂性。评估指标包括用于元素检测和序列化的NID,以及用于表格结构识别的TEDS和TEDS-S。数据集以JSON格式提供,包含每个元素的详细注释,包括坐标、类别和内容。
DP-Bench is a benchmark dataset for document parsing, aiming to evaluate the performance of parsers in converting complex documents such as PDF and scanned images into structured text formats including HTML and Markdown. The dataset contains samples from multiple sources, covering a wide range of document structures and complexities. Evaluation metrics include NID for element detection and serialization, as well as TEDS and TEDS-S for table structure recognition. The dataset is provided in JSON format, with detailed annotations for each element including coordinates, categories and content.
创建时间:
2024-10-08
原始信息汇总
DP-Bench: Document Parsing Benchmark
概述
DP-Bench 是一个用于评估文档解析器性能的基准数据集。该数据集旨在将复杂的文档(如PDF和扫描图像)转换为结构化的文本格式(如HTML和Markdown),并提供了一套新的评估指标来衡量解析器的性能。
评估指标
- NID (Normalized Indel Distance): 用于评估元素检测和序列化的性能。
- TEDS (Tree Edit Distance-based Similarity): 用于评估表格结构识别的性能。
- TEDS-S (Tree Edit Distance-based Similarity-Struct): 专门用于评估表格结构的相似性。
数据集来源
- Library of Congress: 90个样本
- Open Educational Resources: 90个样本
- Upstage: 20个样本
布局元素
数据集包含12种布局元素:
- Paragraph: 804
- Heading1: 194
- Footer: 168
- Caption: 154
- Header: 101
- List: 91
- Chart: 67
- Footnote: 63
- Equation: 58
- Figure: 57
- Table: 55
- Index: 10
数据集格式
数据集以JSON格式存储,每个元素包含位置、布局类别和内容。内容格式包括文本、HTML和Markdown。
文档领域
数据集涵盖多个领域,包括社会科学、自然科学、技术和数学与信息科学。
使用方法
设置
- 需要安装Git LFS来处理大文件。
- 通过克隆仓库并安装依赖项来设置环境。
推理
提供推理脚本以从各种文档解析服务请求结果。
评估
- Element detection and serialization evaluation: 使用NID指标评估文档布局结果。
- Table structure recognition evaluation: 使用TEDS和TEDS-S指标评估表格识别性能。
排行榜
| Source | Request date | TEDS ↑ | TEDS-S ↑ | NID ↑ | Avg. Time (secs) ↓ |
|---|---|---|---|---|---|
| upstage | 2024-10-10 | 92.06 | 93.81 | 96.23 | 3.79 |
| aws | 2024-10-10 | 86.39 | 90.22 | 95.94 | 14.47 |
| llamaparse | 2024-10-10 | 73.36 | 76.29 | 92.22 | 4.14 |
| unstructured | 2024-10-10 | 64.49 | 69.90 | 90.42 | 13.14 |
| 2024-10-10 | 64.64 | 70.95 | 90.09 | 5.85 | |
| microsoft | 2024-10-10 | 85.54 | 89.07 | 87.03 | 4.44 |
搜集汇总
数据集介绍
构建方式
DP-Bench数据集的构建基于多源文档的整合,涵盖了来自美国国会图书馆、开放教育资源以及Upstage内部文档的200个样本。这些文档经过精心挑选,以确保数据集的多样性和代表性。在构建过程中,文档被划分为12种布局元素,包括表格、段落、图表、标题等,特别注重表格结构的识别与评估。每个元素通过JSON格式进行标注,包含其位置、类别和内容信息,确保数据集的完整性和可扩展性。
特点
DP-Bench数据集以其多样化的文档来源和精细的布局元素划分而著称。数据集涵盖了社会科学、自然科学、技术等多个领域的文档,确保了评估的广泛适用性。特别值得一提的是,数据集对表格结构的识别进行了专门设计,通过TEDS和TEDS-S指标进行精确评估。此外,数据集还提供了丰富的文本元素标注,如段落、标题、脚注等,为文档解析系统的全面评估提供了坚实基础。
使用方法
使用DP-Bench数据集时,首先需安装Git LFS以处理大文件,随后克隆仓库并安装依赖项。数据集提供了推理脚本,支持从多种文档解析服务中获取结果。评估过程通过指定参考文件和预测文件的路径进行,支持布局元素检测和表格结构识别的评估。用户可通过运行特定命令计算NID、TEDS和TEDS-S指标,从而全面衡量文档解析系统的性能。数据集的结构化设计和详细标注为研究者和开发者提供了高效的评估工具。
背景与挑战
背景概述
DP-Bench数据集由Upstage团队于2024年推出,旨在为文档解析领域提供一个标准化的评估基准。文档解析是将复杂文档(如PDF和扫描图像)转换为结构化文本格式(如HTML和Markdown)的过程,尤其在检索增强生成(RAG)系统中具有重要应用。该数据集通过引入NID、TEDS和TEDS-S等新型评估指标,填补了现有文档解析器性能评估的空白。数据集涵盖了来自美国国会图书馆、开放教育资源以及Upstage内部文档的200个样本,包含12种布局元素,如表格、段落、图表等,为文档解析器的全面评估提供了丰富的数据支持。
当前挑战
DP-Bench数据集在构建和应用过程中面临多重挑战。首先,文档解析领域的复杂性要求评估指标能够准确反映解析器在文本检测、序列化以及表格结构识别等方面的性能。NID指标虽然能够有效评估文本元素的检测和排序,但在处理表格、图表等复杂元素时存在局限性。其次,数据集的构建需要从多样化的文档来源中提取并标注大量布局元素,这一过程不仅耗时,还需确保标注的一致性和准确性。此外,TEDS和TEDS-S指标虽然能够评估表格的结构和内容,但其计算复杂度较高,可能影响评估效率。这些挑战共同构成了DP-Bench数据集在推动文档解析技术发展中的关键障碍。
常用场景
经典使用场景
DP-Bench数据集在文档解析领域具有广泛的应用,特别是在将复杂文档(如PDF和扫描图像)转换为结构化文本格式(如HTML和Markdown)的过程中。该数据集通过提供多样化的文档布局元素,如表格、段落、图表等,为文档解析器的性能评估提供了标准化的基准。其经典使用场景包括作为RAG系统的预处理工具,确保从视觉丰富的文档中保留关键结构信息。
实际应用
在实际应用中,DP-Bench数据集被广泛用于优化文档解析器的性能,特别是在处理复杂文档时。例如,在法律、教育和技术等领域,该数据集帮助解析器更准确地提取和结构化文档内容,从而提升信息检索和数据分析的效率。此外,该数据集还为企业和研究机构提供了可靠的评估工具,确保其文档解析解决方案能够满足多样化的需求。
衍生相关工作
DP-Bench数据集的发布催生了一系列相关研究工作,特别是在文档解析和表格识别领域。基于该数据集,研究者开发了多种新型解析算法和模型,进一步提升了文档解析的准确性和效率。此外,该数据集还为其他领域的基准测试提供了参考,如自然语言处理和信息检索,推动了跨领域技术的融合与创新。
以上内容由遇见数据集搜集并总结生成


