spider
收藏Hugging Face2025-02-11 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/NESPED-GEN/spider
下载链接
链接失效反馈官方服务:
资源简介:
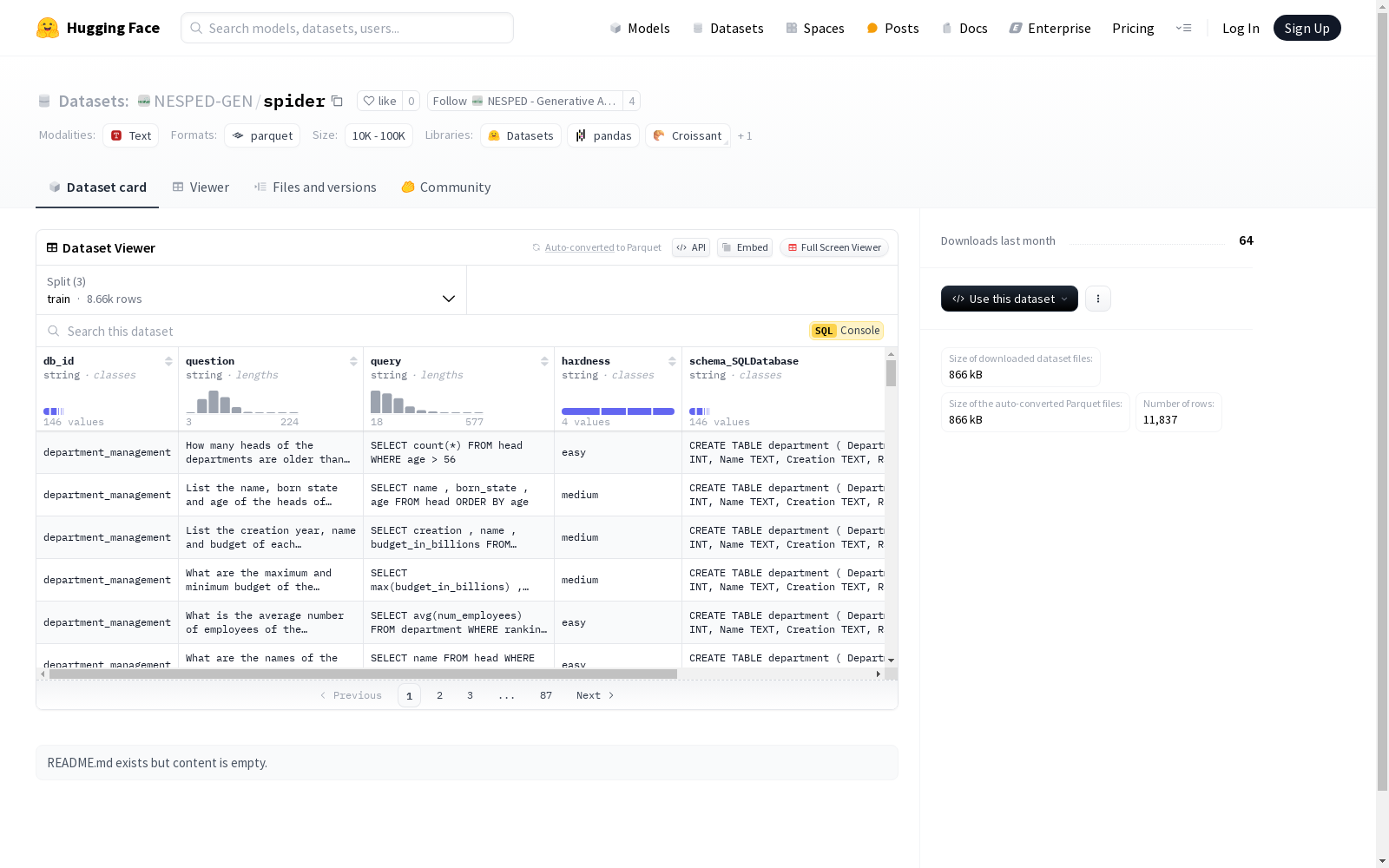
这是一个包含数据库问题的数据集,其中包括问题(question)、查询(query)、难度等级(hardness)、数据库模式(schema_SQLDatabase)和模式链接(schema_linking)等字段。数据集分为训练集、验证集和测试集,分别包含8656、1034和2147个示例。
This is a dataset consisting of database-related questions, which includes fields such as question, query, hardness (i.e., difficulty level), schema_SQLDatabase (i.e., database schema), and schema_linking. The dataset is divided into training, validation and test sets, which contain 8656, 1034 and 2147 instances respectively.
创建时间:
2025-02-11
原始信息汇总
数据集概述
数据集名称
NESPED-GEN/spider
数据集特点
-
字段信息:
- db_id:字符串类型
- question:字符串类型
- query:字符串类型
- hardness:字符串类型
- schema_SQLDatabase:字符串类型
- schema_linking:字符串类型
-
数据划分:
- 训练集:8656条数据,大小为17217136字节
- 验证集:1034条数据,大小为1536982字节
- 测试集:2147条数据,大小为3191523字节
-
下载大小:1135067字节
-
总数据大小:21945641字节
配置信息
- 配置名称:default
- 数据文件路径:
- 训练集:data/train-*
- 验证集:data/dev-*
- 测试集:data/test-*
搜集汇总
数据集介绍
构建方式
在自然语言处理与数据库查询结合的领域中,spider数据集的构建采取了对实际数据库操作任务进行细粒度语义解析的方法。该数据集涵盖了从自然语言形式的问题到结构化查询语言(SQL)的映射,包含了问题、查询、数据库模式等信息,共计8656个训练样本,1034个验证样本,以及2147个测试样本,旨在训练模型理解和执行自然语言提出的数据库查询任务。
特点
spider数据集显著的特点在于其涉及多个领域的真实数据库,如电影、音乐、体育等,每个数据库都拥有独特的模式和结构。此外,数据集的问题和查询均由人工设计,保证了数据的真实性和多样性。数据集的难度梯度明显,从简单到复杂,有助于评估和提升模型的适应性和泛化能力。
使用方法
使用spider数据集时,用户需先下载对应的数据文件,并根据提供的路径将训练集、验证集和测试集加载到模型训练框架中。数据集支持默认配置,简化了数据预处理和加载流程。在模型训练过程中,用户需要关注问题到SQL查询的映射准确性和执行效率,以及模型在不同难度级别上的表现。
背景与挑战
背景概述
SPIDER数据集,诞生于数据库与自然语言处理领域,由清华大学和北京大学的研究团队联合创建于2018年。该数据集致力于解决SQL查询生成任务,旨在推动自然语言处理技术在数据库查询接口中的应用。SPIDER数据集集合了多样化的数据库模式及对应的自然语言查询,成为该领域内首个大规模的跨数据库SQL查询生成数据集,对自然语言处理和数据库领域的结合产生了深远影响。
当前挑战
数据集在构建过程中所遇到的挑战主要包含两个方面:一是如何保证所生成的自然语言查询与SQL查询之间的精确对应,二是如何处理不同数据库模式间存在的异质性。此外,该数据集在解决领域问题——即自然语言到SQL的映射过程中,面临的挑战包括如何提升生成的SQL查询的准确性、如何降低查询生成过程中的误差率以及如何优化跨数据库的查询生成模型的适应性。
常用场景
经典使用场景
在自然语言处理与数据库查询交互领域,SPIDER数据集以其独特的结构化查询与自然语言问题相结合的特征,被广泛用于语义解析的研究中。该数据集提供了一个标准的平台,研究者可以在此基础上训练模型以理解自然语言形式的数据库查询,并生成相应的SQL代码。
解决学术问题
SPIDER数据集解决了学术研究中如何将自然语言有效映射到结构化查询语言(SQL)的难题,这对于构建能够理解自然语言查询意图并执行数据库操作的智能系统至关重要。它为评估和比较不同语义解析模型提供了一个统一的基准,推动了数据库查询解析技术的进步。
衍生相关工作
基于SPIDER数据集,研究者们衍生出了大量相关工作,包括但不限于查询生成、语义解析的改进算法,以及跨领域的数据集扩展。这些工作进一步拓展了自然语言处理技术在数据库查询领域的应用边界,促进了相关技术的成熟与发展。
以上内容由遇见数据集搜集并总结生成


