libritts-snac-tokens
收藏Hugging Face2026-05-15 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/Trelis/libritts-snac-tokens
下载链接
链接失效反馈官方服务:
资源简介:
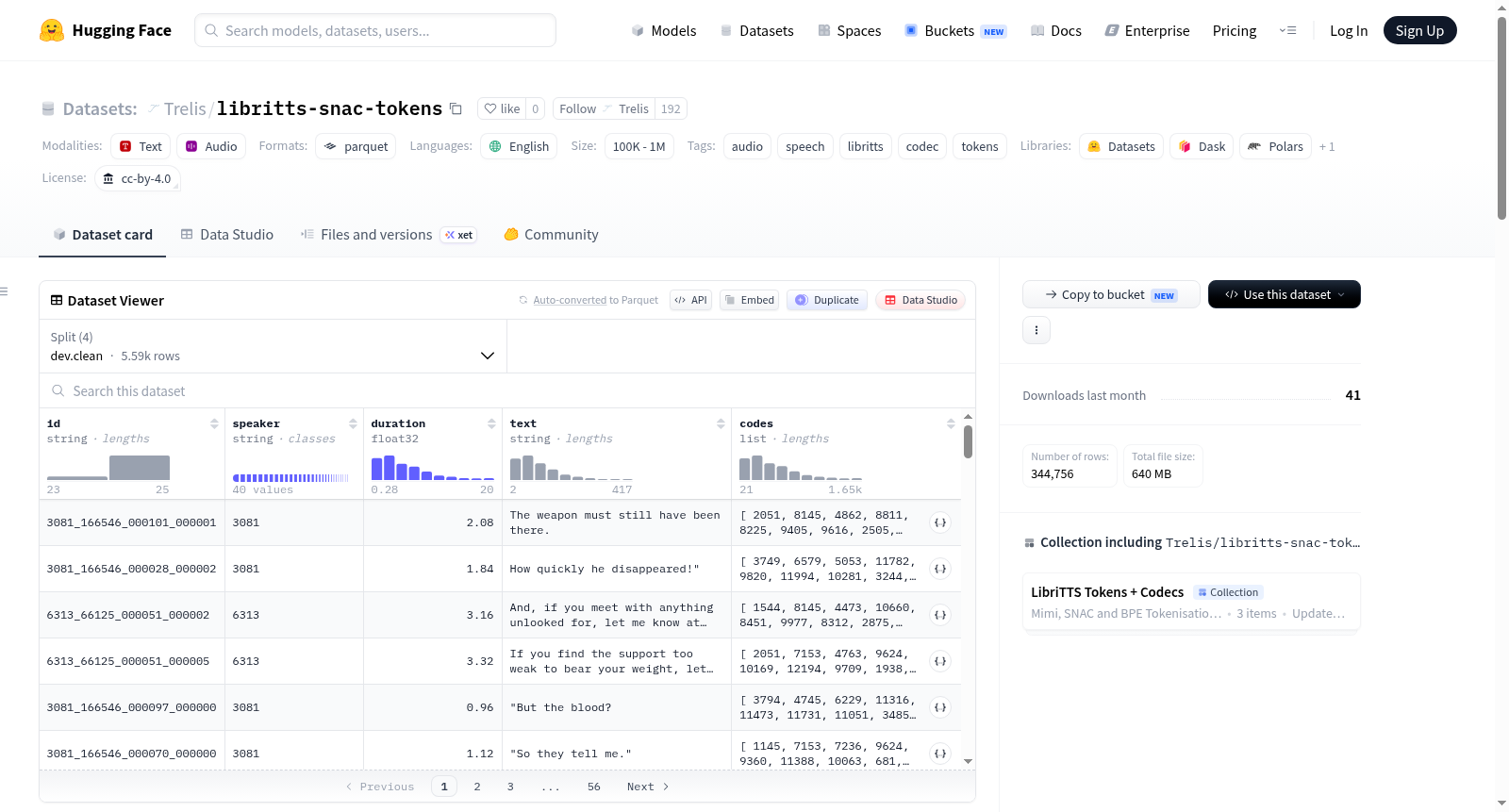
libritts-snac-tokens 是一个基于 LibriTTS-R 语音语料库构建的语音合成标记数据集。其核心内容是将原始的 24 kHz 音频信号,通过名为 hubertsiuzdak/snac_24khz 的分层残差向量量化(RVQ)编解码器进行编码,生成离散的标记序列。编码采用 Orpheus 风格的交错模式:每个音频帧(1/12秒)对应 7 个标记,分别来自三个量化层级(L0, L1, L2),从而形成一个平坦的 84 帧/秒的标记流。整个标记词汇表大小为 12,288,其中 L0、L1、L2 三个层级各占 4096 个条目。数据集的划分遵循源 LibriTTS-R 的划分(并经过 parler-tts 过滤),包含 train.clean.100、train.clean.360、train.other.500 和 dev.clean 四个子集,总计约 538 小时的音频内容。每个数据样本(对应一个话语)包含以下字段:唯一标识符 `id`、说话人ID `speaker`、音频时长(秒)`duration`、规范化文本 `text` 以及核心的编解码器标记序列 `codes`。该数据集适用于需要高质量、离散语音表示的语音合成模型训练、语音表示学习等任务,许可证为 CC-BY-4.0。
libritts-snac-tokens is a speech synthesis token dataset built on the LibriTTS-R speech corpus. Its core content is encoding the original 24 kHz audio signals using the hierarchical residual vector quantization (RVQ) codec named hubertsiuzdak/snac_24khz to generate discrete token sequences. The encoding adopts an Orpheus-style interleaved pattern: each audio frame (1/12 second) corresponds to 7 tokens from three quantization tiers (L0, L1, L2), resulting in a flat token stream at 84 tokens per second. The total size of the token vocabulary is 12,288, with each of the three tiers L0, L1 and L2 containing 4,096 entries respectively. The dataset split follows the original LibriTTS-R partition (filtered via parler-tts), including four subsets: train.clean.100, train.clean.360, train.other.500 and dev.clean, with a total of approximately 538 hours of audio content. Each data sample, corresponding to one utterance, contains the following fields: unique identifier `id`, speaker ID `speaker`, audio duration (in seconds) `duration`, normalized text `text`, and the core codec token sequence `codes`. This dataset is suitable for tasks such as speech synthesis model training and speech representation learning that require high-quality discrete speech representations, and is licensed under CC-BY-4.0.
提供机构:
Trelis创建时间:
2026-05-15
搜集汇总
数据集介绍
构建方式
libritts-snac-tokens数据集构建于广为人知的LibriTTS-R语音语料库之上,通过引入先进的神经音频编解码模型hubertsiuzdak/snac_24khz进行编码转换。该编码器采用三级层次化残差矢量量化(hierarchical RVQ)架构,分别以每秒12、24和48帧的粒度对音频进行表征,每级包含4096个码本条目。每个1/12秒的音频帧被重组为Orpheus风格的交叉序列,即依次排列各级码本索引,最终形成每秒84个令牌的扁平化表示。令牌词汇表总数为12,288,通过按层级偏移的方式确保各级编码空间互不重叠。数据集沿用经parler-tts过滤后的LibriTTS-R划分方案,保留了训练集与开发集的说话人无重叠结构,总计约538小时语音内容。
使用方法
研究人员可通过HuggingFace的datasets库便捷地加载本数据集,支持选择全部划分或任意单一子集,亦可灵活组合多个训练划分进行模型训练。加载后每条样本的codes字段即为预计算的SNAC令牌序列,可直接用于序列建模或作为语音编解码任务的输入特征。对于需要原始音频的研究场景,本数据集与多个采用不同编码方案(如BPE、Mimi、NeuCodec)的同伴数据集共享相同音频源,便于进行编码方法对比分析。使用过程中应注意,超过20秒的语音段在编码时被截断,令牌数量严格对应编码器输出时间网格,确保了时序对齐的精确性。数据集遵循CC-BY-4.0许可协议,可自由用于学术与商业研究。
背景与挑战
背景概述
在神经音频编解码与语音生成交汇的学术前沿,对大规模、高质量且经过一致性处理的语音表征数据需求日益迫切。LibriTTS-SNAC-Tokens数据集由Trelis Research于2024年构建,基于广受认可的LibriTTS-R语料库(延续自卡内基梅隆大学与爱丁堡大学的经典工作),采用hubertsiuzdak/snac_24kHz层次化残差向量量化器将其编码为离散令牌序列。该数据集核心旨在为语音语言模型提供结构化的、层级化的声学表征——遵循Orpheus风格的交错模式,以每1/12秒音频帧产出7个令牌,最终形成每秒84帧的稠密令牌流。通过将三个量化层级分配至12,288词表的非重叠偏移区间,数据不仅支持直接解码重建,更天然适配于自回归或非自回归的语音生成框架。其约538小时、近40万句的规模与清晰划分的训练/开发集,使其在语音编解码、神经声码器训练以及基于令牌的文本到语音合成研究中具有不可忽视的基准地位。
当前挑战
该数据集所应对的核心领域挑战集中于如何高效、细粒度地表示复杂语音信号以服务于下游生成任务,具体体现在:首先,传统的连续声学特征(如梅尔谱)难以被离散化语言模型直接建模,而SNAC三层级变帧率分层量化(12/24/48 fps)的方案需在保证重构音质与降低序列长度间取得精确权衡;其次,同源音频的多版本令牌化(如BPE、Mimi、NeuCodec)对比研究对数据集的一致划分与对齐策略提出严苛要求。在构建层面,挑战主要涵盖:对超过20秒的超长语音片段执行截断时,需确保文本与音频的完整性不因截断而被破坏;不同编解码器(如16 kHz NeuCodec与24 kHz SNAC)对原始音频的采样率要求差异迫使引入抗混叠多相重采样流水线以维持频谱保真度;此外,为保持与经典LibriTTS-R划分结构(如说话人不重叠)的兼容性,需从经过parler-tts过滤的子集中精确还原并验证分片无泄露,这对数据处理管线的鲁棒性与可复现性构成了显著考验。
常用场景
经典使用场景
在语音合成与音频生成领域,libritts-snac-tokens数据集被广泛用于训练和评估基于离散编码的语音生成模型。该数据集将LibriTTS-R大规模朗读语音语料库,通过hubertsiuzdak/snac_24khz分级残差矢量量化(RVQ)编码器转化为层次化声学令牌,形成三层级(L0、L1、L2)的帧级令牌序列,每帧输出7个令牌,频率高达84 fps。这种结构化的令牌表示不仅保留了丰富的声学细节,还通过Orpheus风格的交错排列,为自回归语言模型和音频编解码器提供了理想的训练素材。研究人员可以基于这些令牌直接建模语音的音色、韵律和语调变化,进而实现高质量的零样本语音合成或多说话人语音克隆。
解决学术问题
该数据集有效解决了语音生成领域中离散声学表示与语言模型融合的学术难题。传统语音合成依赖连续声学特征(如mel谱),难以直接嵌入自回归生成框架。libritts-snac-tokens通过分层量化策略,将24kHz语音信号压缩为4096个码本条目的离散令牌,并保持三个时间粒度(12、24、48 fps),使得语音信息可被大型语言模型直接处理。这一表示为探索语音与文本的联合建模、跨模态语义对齐,以及提升语音合成的自然度和多样性提供了关键数据基础。其对说话人身份与语义内容的解耦能力,推进了多说话人、多风格语音生成的理论研究,并在语音压缩与重建的保真度评估中树立了新基准。
实际应用
在实际应用中,libritts-snac-tokens驱动的模型主要部署于智能语音助手、有声读物自动生成、虚拟主播与数字人语音交互等场景。基于该数据集训练的语音生成系统,能以极低的比特率实现接近自然人声的合成效果,适合带宽受限的移动端和物联网设备。同时,其层级化的令牌结构使得系统能够灵活调整生成语音的音高、语速和情感色彩,可广泛应用于个性化语音定制、语言教育中的发音示范,以及为言语障碍人士提供辅助发音工具。此外,该数据集与Trelis企业语音服务结合,正在赋能呼叫中心的自动化应答和沉浸式语音导航系统,显著提升了用户交互的流畅性和自然度。
数据集最近研究
最新研究方向
基于分层残差矢量量化(SNAC)的语音编解码令牌化技术在神经编解码语言模型(如Orpheus架构)中展现出前沿价值,通过将LibriTTS-R高质量语音语料库编码为三层时间分辨率(12/24/48 fps)的离散令牌序列,实现了从粗粒度声学结构到细粒度音质细节的层次化建模。该数据集与同期发布的BPE、Mimi、NeuCodec等令牌化变体共同构成多模态表征对比实验的基石,推动语音合成领域从传统的连续特征预测向自回归离散令牌生成范式演进。其Orpheus风格的交错令牌排列(每音频帧7令牌)直接服务于实时交互式语音系统,显著提升了语音生成的时间一致性,为高表现力、低延迟的语音合成技术开辟了新路径。
以上内容由遇见数据集搜集并总结生成


