webfaq-v2-bitexts
收藏Hugging Face2026-02-15 更新2026-02-16 收录
下载链接:
https://huggingface.co/datasets/michaeldinzinger/webfaq-v2-bitexts
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个多语言文本检索数据集,支持包括南非荷兰语、阿姆哈拉语、阿拉伯语、阿塞拜疆语、白俄罗斯语、孟加拉语、波斯尼亚语、保加利亚语、加泰罗尼亚语、宿务语、捷克语、威尔士语、丹麦语、德语、希腊语、英语、世界语、爱沙尼亚语、巴斯克语、波斯语、芬兰语、法语、弗里斯兰语、苏格兰盖尔语、爱尔兰语、加利西亚语、古吉拉特语、海地克里奥尔语、希伯来语、印地语、克罗地亚语、匈牙利语、亚美尼亚语、印尼语、冰岛语、意大利语、爪哇语、日语、卡纳达语、格鲁吉亚语、哈萨克语、高棉语、吉尔吉斯语、韩语、库尔德语、老挝语、拉丁语、拉脱维亚语、立陶宛语、卢森堡语、马拉雅拉姆语、马拉地语、马其顿语、马尔加什语、马耳他语、蒙古语、马来语、缅甸语、尼泊尔语、荷兰语、挪威语、旁遮普语、波兰语、葡萄牙语、普什图语、罗马尼亚语、俄语、僧伽罗语、斯洛伐克语、斯洛文尼亚语、信德语、西班牙语、阿尔巴尼亚语、塞尔维亚语、巽他语、斯瓦希里语、瑞典语、泰米尔语、泰卢固语、塔吉克语、他加禄语、泰语、土耳其语、乌克兰语、乌尔都语、乌兹别克语、越南语、意第绪语和中文在内的多种语言。数据集适用于文本检索任务,特别是文件检索。
This dataset is a multilingual text retrieval dataset that supports a diverse set of languages including Afrikaans, Amharic, Arabic, Azerbaijani, Belarusian, Bengali, Bosnian, Bulgarian, Catalan, Cebuano, Czech, Welsh, Danish, German, Greek, English, Esperanto, Estonian, Basque, Persian, Finnish, French, Frisian, Scottish Gaelic, Irish, Galician, Gujarati, Haitian Creole, Hebrew, Hindi, Croatian, Hungarian, Armenian, Indonesian, Icelandic, Italian, Javanese, Japanese, Kannada, Georgian, Kazakh, Khmer, Kyrgyz, Korean, Kurdish, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Malayalam, Marathi, Macedonian, Malagasy, Maltese, Mongolian, Malay, Burmese, Nepali, Dutch, Norwegian, Punjabi, Polish, Portuguese, Pashto, Romanian, Russian, Sinhala, Slovak, Slovenian, Sindhi, Spanish, Albanian, Serbian, Sundanese, Swahili, Swedish, Tamil, Telugu, Tajik, Tagalog, Thai, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Yiddish, and Chinese. It is tailored for text retrieval tasks, particularly document retrieval.
创建时间:
2026-02-12
原始信息汇总
数据集概述
基本信息
- 数据集名称: webfaq-v2-bitexts
- 托管平台: Hugging Face
- 地址: https://huggingface.co/datasets/michaeldinzinger/webfaq-v2-bitexts
语言信息
- 语言覆盖: 包含多种语言,具体包括南非荷兰语、阿姆哈拉语、阿拉伯语、阿塞拜疆语、白俄罗斯语、孟加拉语、波斯尼亚语、保加利亚语、加泰罗尼亚语、宿务语、捷克语、威尔士语、丹麦语、德语、希腊语、英语、世界语、爱沙尼亚语、巴斯克语、波斯语、芬兰语、法语、西弗里西亚语、苏格兰盖尔语、爱尔兰语、加利西亚语、古吉拉特语、海地克里奥尔语、希伯来语、印地语、克罗地亚语、匈牙利语、亚美尼亚语、印度尼西亚语、冰岛语、意大利语、爪哇语、日语、卡纳达语、格鲁吉亚语、哈萨克语、高棉语、吉尔吉斯语、韩语、库尔德语、老挝语、拉丁语、拉脱维亚语、立陶宛语、卢森堡语、马拉雅拉姆语、马拉地语、马其顿语、马尔加什语、马耳他语、蒙古语、马来语、缅甸语、尼泊尔语、荷兰语、挪威语、旁遮普语、波兰语、葡萄牙语、普什图语、罗马尼亚语、俄语、僧伽罗语、斯洛伐克语、斯洛文尼亚语、信德语、西班牙语、阿尔巴尼亚语、塞尔维亚语、巽他语、斯瓦希里语、瑞典语、泰米尔语、泰卢固语、塔吉克语、他加禄语、泰语、土耳其语、乌克兰语、乌尔都语、乌兹别克语、越南语、意第绪语、中文。
- 多语言性: 多语言
任务与用途
- 任务类别: 文本检索
- 任务ID: 文档检索
- 标签: 文本检索
数据集结构
- 该数据集详情页面未提供关于具体数据字段、样本数量、分割方式或数据来源的详细信息。
搜集汇总
数据集介绍
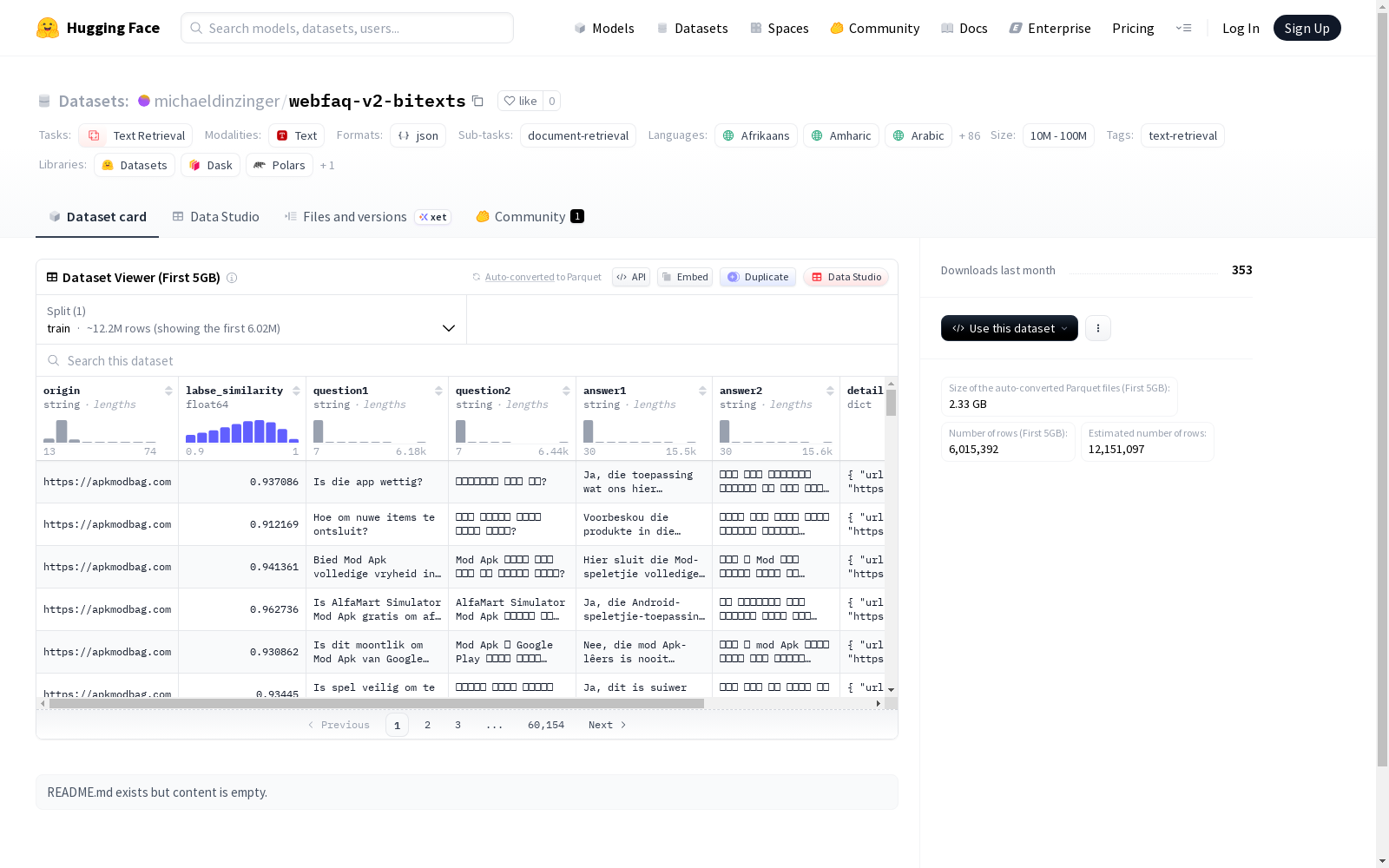
构建方式
在跨语言信息检索领域,构建高质量的多语言平行语料库是推动模型泛化能力的关键。WebFAQ-v2-bitexts数据集通过自动化网络爬取技术,从互联网上搜集了涵盖超过100种语言的网页内容,并运用先进的句子对齐算法,将不同语言版本的同一文档进行精准匹配,形成大规模的双语句对。这一过程不仅确保了数据的多样性和覆盖面,还通过多轮质量过滤机制,有效剔除了噪声和低质量样本,为跨语言检索任务提供了坚实的语料基础。
特点
该数据集以其广泛的语言覆盖和精细的语料对齐而著称,囊括了从常见语言如英语、中文到资源稀缺语言如阿姆哈拉语、吉尔吉斯语等,显著提升了多语言场景下的研究潜力。每个语对均经过严格的语义对齐验证,确保了跨语言检索任务中查询与文档的相关性。数据集的规模庞大且结构清晰,支持多种下游任务,如机器翻译评估和跨语言检索模型训练,为自然语言处理领域的多语言研究提供了重要资源。
使用方法
研究人员可利用该数据集进行跨语言检索系统的训练与评估,通过加载预处理后的双语句对,构建查询-文档匹配模型。在实际应用中,数据集支持多种机器学习框架,用户可依据语言代码筛选特定语种,进行定制化实验。此外,数据集还可作为基准测试集,用于衡量模型在多语言环境下的性能表现,推动跨语言信息检索技术的创新与发展。
背景与挑战
背景概述
随着全球互联网信息的爆炸式增长,跨语言信息检索与机器翻译的需求日益凸显,多语言文本对齐数据集成为自然语言处理领域的关键资源。webfaq-v2-bitexts数据集由研究机构或团队于近年构建,旨在应对多语言环境下高质量平行语料稀缺的挑战,其核心研究问题聚焦于从网络常见问题解答(FAQ)中提取精准的双语句对,以支持跨语言检索、翻译模型训练及低资源语言处理。该数据集覆盖超过80种语言,包括非洲语、亚洲语及欧洲语系等多种低资源语言,显著提升了多语言NLP模型的泛化能力,对推动全球化信息无障碍访问具有重要影响力。
当前挑战
在领域问题层面,webfaq-v2-bitexts数据集致力于解决多语言文本检索与对齐中的核心挑战,包括低资源语言数据稀疏性、语言间语义对齐的精确度不足,以及跨文化语境下FAQ表达的多样性导致的匹配困难。构建过程中,研究人员面临数据收集与清洗的复杂性,需从异构网络源中提取高质量双语句对,同时确保语言覆盖的广度与语料平衡性;此外,处理非拉丁字符编码、方言变体及噪声过滤等技术障碍,进一步增加了数据集构建的难度。
常用场景
经典使用场景
在跨语言信息检索领域,webfaq-v2-bitexts数据集凭借其覆盖近百种语言的平行文本对,为构建多语言检索系统提供了关键资源。该数据集常用于训练和评估跨语言检索模型,使模型能够跨越语言障碍,从不同语言的文档中准确匹配相关问答内容。其大规模、高质量的对齐文本,有效支持了检索算法在复杂多语言环境下的性能优化,成为推动跨语言信息处理技术发展的基础工具。
衍生相关工作
围绕webfaq-v2-bitexts数据集,已衍生出一系列经典研究工作,特别是在跨语言检索模型与多语言预训练领域。例如,基于该数据集的检索模型对比研究、多语言BERT等预训练语言模型的微调实验,以及针对低资源语言的检索增强技术探索。这些工作不仅验证了数据集的有效性,也进一步推动了多语言自然语言处理技术的创新与标准化进程。
数据集最近研究
最新研究方向
在跨语言信息检索领域,webfaq-v2-bitexts数据集凭借其覆盖超过100种语言的平行文本资源,已成为推动多语言模型发展的关键基础设施。当前研究焦点集中于利用该数据集训练高效的神经检索系统,以应对全球化数字环境中低资源语言的查询需求,同时结合对比学习与自监督技术提升跨语言语义对齐的精度。这一趋势与近期多语言大模型如mT5和XLM-R的兴起紧密相连,显著促进了机器翻译、问答系统等应用的性能突破,为消除语言障碍、构建包容性人工智能生态系统提供了坚实的数据支撑。
以上内容由遇见数据集搜集并总结生成


