sample-dataset-test-neural-nopack
收藏Hugging Face2026-02-13 更新2026-02-14 收录
下载链接:
https://huggingface.co/datasets/Trelis/sample-dataset-test-neural-nopack
下载链接
链接失效反馈官方服务:
资源简介:
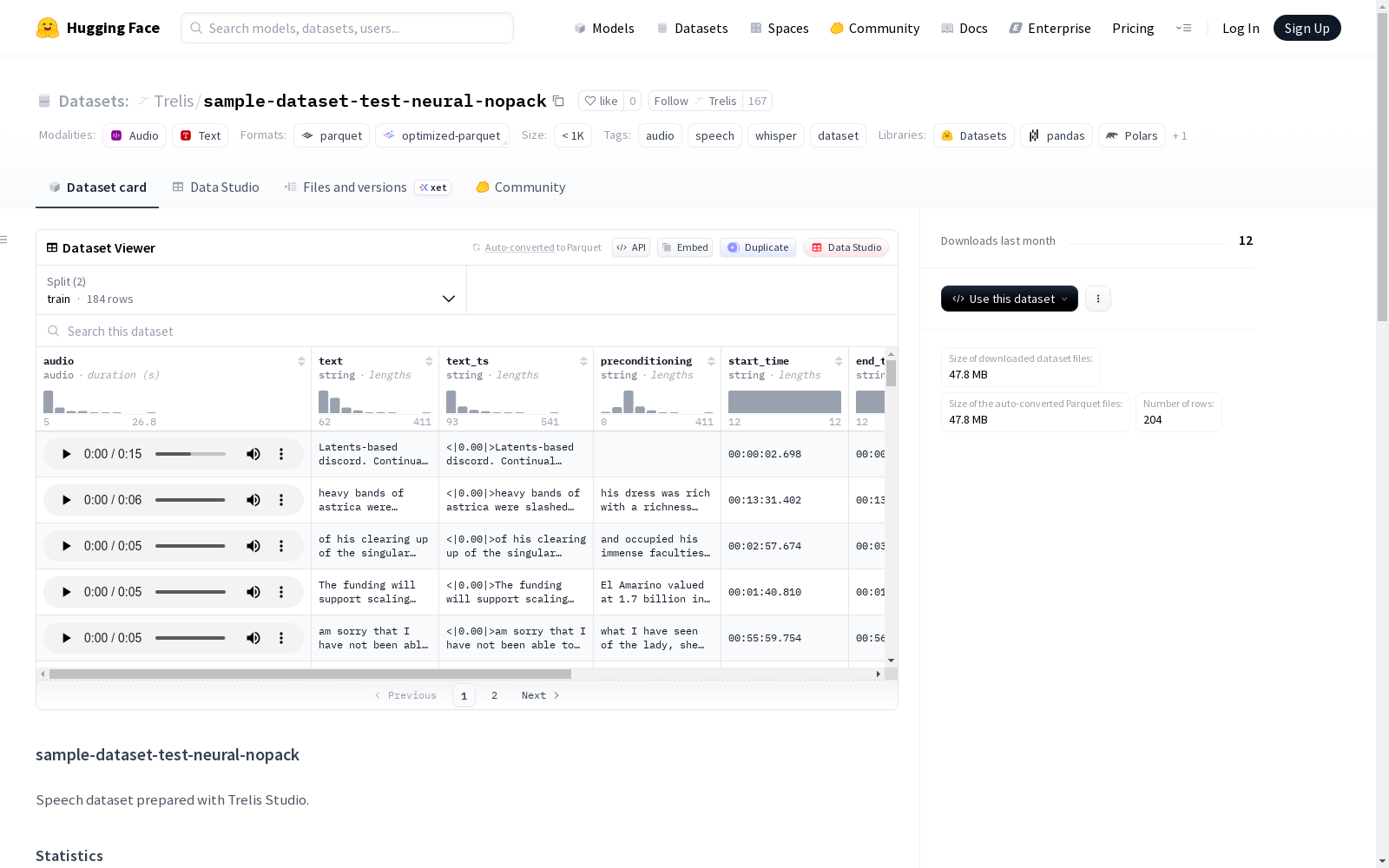
该数据集是一个专为语音处理任务设计的音频数据集,特别适用于Whisper模型。数据集由Trelis Studio准备,包含经过语音活动检测(VAD)处理的音频片段,去除了静音部分。数据集统计信息显示,共有6个源文件,包含184个训练样本和20个验证样本,总时长为62.6分钟。数据集的列包括音频片段(16kHz)、纯文本转录、带时间戳的转录、片段起始和结束时间、语音持续时间、词级时间戳以及源文件名。音频片段经过Silero VAD处理,确保仅保留语音区域,时间戳相对于拼接后的语音音频。数据集适用于Whisper时间戳训练,建议使用两桶方法:50%使用纯文本转录,50%使用带时间戳的转录。
This dataset is an audio dataset tailored for speech processing tasks, particularly suitable for the Whisper model. Prepared by Trelis Studio, it includes audio segments processed via Voice Activity Detection (VAD) with silent parts removed. Statistical summary of the dataset shows 6 source files, 184 training samples, 20 validation samples, with a total duration of 62.6 minutes. The dataset contains the following columns: 16kHz audio segments, raw text transcripts, timestamped transcripts, segment start and end times, speech duration, word-level timestamps, and source file names. All audio segments are processed with Silero VAD to retain only speech regions, and the timestamps are relative to the concatenated speech audio. This dataset is intended for Whisper timestamp training, and the two-bucket approach is recommended: 50% of the data uses raw text transcripts, while the other 50% uses timestamped transcripts.
提供机构:
Trelis创建时间:
2026-02-13
搜集汇总
数据集介绍
构建方式
在语音处理领域,高质量数据集的构建对模型性能具有决定性影响。该数据集通过Trelis Studio平台精心制备,原始音频文件共计6个,经过严格的语音活动检测处理,利用Silero VAD技术剥离静音部分,仅保留纯净语音区域。处理过程中,音频被分割为204个样本,其中训练集包含184个样本,验证集20个样本,总时长达62.6分钟。每个样本均标注了起始时间、结束时间及语音持续时间,并提供了兼容Whisper模型的带时间戳文本标注,确保了数据与推理行为的高度一致性。
使用方法
为充分发挥该数据集在语音识别模型训练中的价值,建议采用双桶策略进行训练数据配置。具体操作时,可将50%的训练样本配置为使用纯文本转录字段,另外50%则采用带时间戳的文本转录字段,这种混合训练方式有助于模型同时掌握内容识别与时间定位能力。技术实现上,用户可通过Hugging Face数据集库直接加载,调用load_dataset函数并指定相应路径即可便捷获取完整数据。数据加载后,开发者可根据研究需求灵活调用不同字段,进行端到端语音识别训练或时间戳预测等专项任务。
背景与挑战
背景概述
在语音识别与处理领域,高质量标注数据集的构建是推动模型性能提升的关键。sample-dataset-test-neural-nopack数据集由Trelis机构通过其Studio平台精心制备,专注于为Whisper等先进语音模型提供训练与验证支持。该数据集的核心研究问题在于如何有效整合语音活动检测(VAD)技术与时间戳标注,以生成既包含纯净语音片段又具备精确时间信息的结构化数据,从而优化模型在真实场景下的推理表现。其设计理念强调了数据与推理行为的一致性,为语音识别领域的时间戳预测与端到端处理提供了重要的实验基础。
当前挑战
该数据集旨在应对语音识别中时间戳预测与端到端处理的挑战,具体包括如何在连续语音流中准确分割语音与非语音区域,以及如何生成与模型推理相匹配的时间戳标注。在构建过程中,挑战主要源于语音活动检测的精度控制,需确保沉默部分被有效剥离而不损失语音完整性;同时,时间戳标注需与Whisper模型的令牌格式对齐,这要求细致的后处理与数据一致性校验。此外,数据集的规模相对有限,在覆盖多样语音风格与口音方面存在扩展空间,可能影响模型的泛化能力。
常用场景
经典使用场景
在语音处理领域,该数据集专为训练和评估Whisper模型而设计,尤其适用于语音识别与时间戳标注任务。通过提供经过VAD处理的纯语音片段及带时间戳的文本转录,它支持模型学习在去除静音后准确对齐音频与文本,从而优化语音识别系统在实时或离线场景下的性能表现。
解决学术问题
该数据集有效解决了语音识别研究中音频与文本对齐的精确性问题,通过引入时间戳标注和静音剥离技术,降低了模型训练中的噪声干扰。其意义在于推动了端到端语音识别模型在时序建模方面的发展,为学术研究提供了高质量、结构化的基准数据,促进了语音技术向更精准、鲁棒的方向演进。
实际应用
在实际应用中,该数据集可服务于智能语音助手、会议转录系统及多媒体内容索引等场景。其带时间戳的转录功能支持音频内容的快速检索与分段,提升用户体验;同时,静音剥离处理增强了系统在嘈杂环境下的识别鲁棒性,为工业界部署高效的语音处理解决方案提供了可靠数据支撑。
数据集最近研究
最新研究方向
在语音处理领域,基于Whisper模型的语音识别与时间戳标注技术正成为研究热点。该数据集通过集成Silero VAD技术去除静音片段,并提供了带时间戳的文本标注,为语音识别模型的训练提供了精细化数据支持。前沿研究聚焦于利用此类数据集优化端到端语音识别系统,特别是在多模态交互、实时字幕生成及语音内容检索等场景中,提升时间戳预测的准确性与鲁棒性。相关技术已应用于智能助手、无障碍通信及媒体自动化处理,推动了语音技术在时效性与可解释性方面的进步,对促进人机自然交互具有重要影响。
以上内容由遇见数据集搜集并总结生成


