1gb-test-neural-pack
收藏Hugging Face2026-02-13 更新2026-02-14 收录
下载链接:
https://huggingface.co/datasets/Trelis/1gb-test-neural-pack
下载链接
链接失效反馈官方服务:
资源简介:
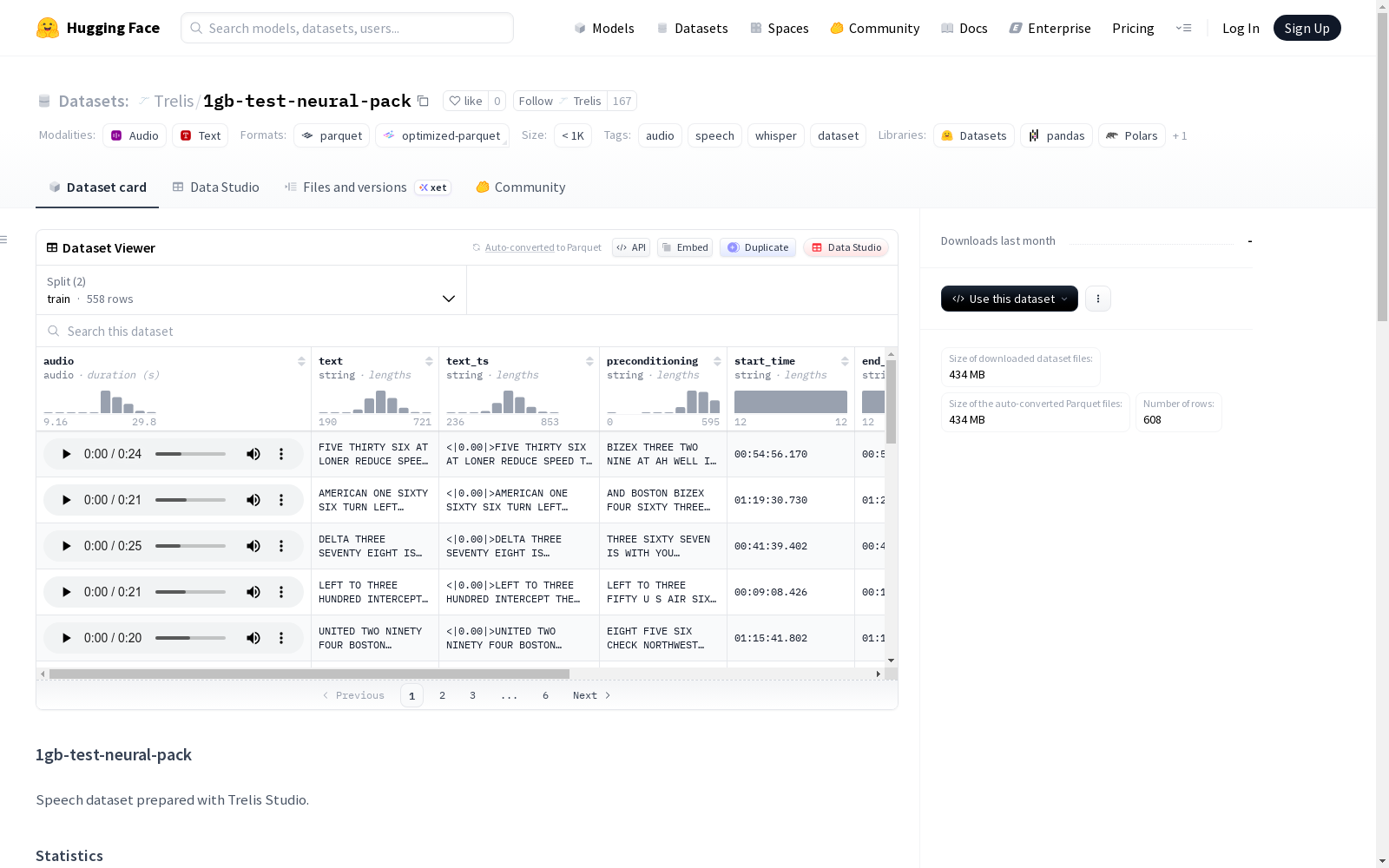
1gb-test-neural-pack 是一个由 Trelis Studio 准备的语音数据集,专为音频和语音处理任务设计。数据集包含 5 个源文件,共计 558 个训练样本和 50 个验证样本,总时长为 587.1 分钟。数据经过 Silero VAD 处理,去除了静音部分,仅保留语音区域,以确保与 faster-whisper 推理行为一致。数据集包含多个字段:音频片段(16kHz)、纯文本转录、带 Whisper 时间戳标记的转录、原始音频中的片段起始和结束时间、语音持续时间、词级时间戳以及源文件名。该数据集特别适用于 Whisper 时间戳训练,建议采用两桶方法:50% 使用不带时间戳的纯文本转录,50% 使用带时间戳标记的转录。
The 1gb-test-neural-pack is a speech dataset curated by Trelis Studio, tailored for audio and speech processing tasks. This dataset consists of 5 source files, with a total of 558 training samples and 50 validation samples, and a total duration of 587.1 minutes. The data has been processed with Silero VAD to remove silent segments, retaining only speech regions to align with the inference behavior of faster-whisper. The dataset includes multiple fields: audio clips (16kHz), plain text transcriptions, transcriptions with Whisper timestamp annotations, start and end times of segments in the original audio, speech duration, word-level timestamps, and source file names. This dataset is particularly suitable for Whisper timestamp training, and a two-bucket approach is recommended: 50% using plain text transcriptions without timestamps, and 50% using transcriptions with timestamp annotations.
提供机构:
Trelis创建时间:
2026-02-13
原始信息汇总
1gb-test-neural-pack 数据集概述
数据集基本信息
- 数据集名称:1gb-test-neural-pack
- 主要用途:语音识别与Whisper时间戳训练
- 创建工具:Trelis Studio
- 标签:音频、语音、whisper、数据集
数据统计
| 指标 | 数值 |
|---|---|
| 源文件数量 | 5 |
| 训练样本数 | 558 |
| 验证样本数 | 50 |
| 总时长 | 587.1分钟 |
数据列结构
| 列名 | 类型 | 描述 |
|---|---|---|
audio |
Audio | 音频片段(16kHz)- 仅语音,通过VAD去除静音 |
text |
string | 纯文本转录(无时间戳)- 向后兼容 |
text_ts |
string | 带Whisper时间戳标记的转录(例如:`< |
start_time |
string | 片段在原始音频中的开始时间(HH:MM:SS.mmm) |
end_time |
string | 片段在原始音频中的结束时间(HH:MM:SS.mmm) |
speech_duration |
float | 片段中语音的持续时间(不包括静音) |
word_timestamps |
list | 词级时间戳(相对于仅语音音频) |
source_file |
string | 原始音频文件名 |
语音活动检测(VAD)处理
- 使用Silero VAD处理音频片段以匹配faster-whisper推理。
- 从音频中去除静音(仅保留语音区域)。
- 时间戳相对于拼接后的仅语音音频。
- 确保训练数据与推理行为匹配。
训练使用建议
针对Whisper时间戳训练,建议使用双桶方法:
- 桶A(50%):使用
text列(无时间戳的纯文本转录)。 - 桶B(50%):使用
text_ts列(带Whisper时间戳标记的转录)。
数据加载方式
python from datasets import load_dataset dataset = load_dataset("Trelis/1gb-test-neural-pack")
搜集汇总
数据集介绍
构建方式
在语音识别研究领域,高质量的数据集是推动模型性能提升的关键。1gb-test-neural-pack数据集通过Trelis Studio精心构建,其核心处理流程包括利用Silero VAD技术对原始音频进行语音活动检测,有效剥离静默部分,仅保留纯净的语音区域。所有时间戳均基于拼接后的语音音频进行计算,确保了与faster-whisper推理行为的一致性,从而为模型训练提供了精准对齐的语音-文本对。
特点
该数据集在结构设计上展现出显著的专业性,不仅提供标准的纯文本转录,还创新性地包含了带有Whisper时间戳标记的转录文本,支持细粒度的时序分析。数据列涵盖音频片段、起止时间、语音时长及词级时间戳等多维度信息,为语音识别与时间戳预测任务提供了丰富的研究素材。其严谨的VAD处理保证了音频数据的纯净度,使模型能够更专注于语音内容的建模。
使用方法
针对Whisper时间戳训练任务,数据集推荐采用双桶策略进行高效利用:一半样本使用不含时间戳的纯文本转录,另一半则使用包含时间戳标记的文本。研究人员可通过Hugging Face的datasets库直接加载数据,便捷地接入现有工作流程。这种设计兼顾了传统转录任务与新兴时序建模需求,为语音处理模型的开发与评估提供了灵活且可靠的实验基础。
背景与挑战
背景概述
在语音识别与处理领域,高精度转录及时间戳标注对推动自动语音识别(ASR)模型的发展至关重要。1gb-test-neural-pack数据集由Trelis Studio于近期构建,旨在为Whisper等先进语音模型提供训练与评估资源。该数据集聚焦于语音片段的精细化处理,通过去除静音部分并集成词级时间戳,致力于提升模型在真实场景下的转录准确性与时间对齐能力。其设计体现了当前语音技术向细粒度、结构化标注方向的演进,为研究者探索端到端语音识别系统的优化提供了关键数据支撑。
当前挑战
该数据集致力于解决语音识别中转录与时间戳同步的挑战,尤其在处理包含不规则静音的连续语音时,模型需准确分割语音段并关联对应文本。构建过程中,通过Silero VAD技术剥离静音,确保数据与推理环境一致,但面临语音边界检测的精度问题,以及时间戳在静音去除后的对齐复杂性。此外,数据规模相对有限,可能制约模型在多样化口音与噪声环境下的泛化能力,需进一步扩展以覆盖更广泛的语音场景。
常用场景
经典使用场景
在语音处理领域,1gb-test-neural-pack数据集专为训练和评估Whisper等自动语音识别模型而设计。其核心应用场景在于支持带时间戳的语音转录任务,通过提供精确的语音片段分割和文本对齐,使模型能够学习生成包含时间标记的转录结果。该数据集经过静音去除处理,确保了训练数据与推理环境的一致性,从而优化了模型在真实场景下的性能表现。
衍生相关工作
围绕该数据集,衍生出了一系列专注于时间戳语音识别的研究与实践。例如,基于Whisper架构的改进模型常利用其进行带时间戳的微调训练,以提升转录的时间精度。同时,该数据集支持了双桶训练策略的开发,即混合使用带时间戳和不带时间戳的样本,平衡模型在不同任务上的泛化能力。这些工作推动了语音识别技术向更细粒度时序分析方向的发展。
数据集最近研究
最新研究方向
在语音处理领域,1gb-test-neural-pack数据集凭借其精细的语音活动检测(VAD)处理和Whisper时间戳标注,正推动自动语音识别(ASR)模型向细粒度时序对齐方向演进。当前研究聚焦于利用该数据集的双桶训练策略,探索端到端模型在生成准确转录的同时,精准预测词级或子词级时间戳的能力,以支持音频字幕生成、语音翻译同步等应用。这一方向与多模态交互、实时语音分析等热点紧密结合,通过提升时序建模的鲁棒性,为构建更智能、可解释的语音系统奠定数据基础。
以上内容由遇见数据集搜集并总结生成


