nso-gov-vn
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/tmquan/nso-gov-vn
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是越南国家统计局(NSO)PX-Web统计数据库的完整镜像,经过重新结构化以支持下游机器学习应用。数据集包含502个统计矩阵,共计316,108条长格式数据记录,覆盖12个主要统计领域,如农业、教育、人口与劳动力等。数据时间跨度为1959年至2024年,包含越南语和英语标签。数据集以parquet格式存储,适用于表格分类、回归和文本分类等任务。此外,数据集还提供了丰富的可视化分析结果和交互式图表,便于数据探索和分析。
创建时间:
2026-05-08
原始信息汇总
数据集概述:personas-vn-pxweb — 越南国家统计局 PX-Web 镜像
基本信息
- 数据集名称:personas-vn-pxweb — Vietnamese NSO PX-Web mirror
- 发布者:TMQuan
- 语言:越南语(主要)、英语
- 许可协议:CC BY-NC 4.0(非商业性使用)
- 数据规模:100,000 ~ 1,000,000 条记录
- 任务类型:表格分类、表格回归、文本分类
数据来源与内容
该数据集是越南国家统计局(GSO/NSO) PX-Web 统计数据库的完整镜像,所有数据爬取自 https://pxweb.nso.gov.vn,并转换为 Parquet 格式供机器学习使用。该数据集也是 personas-vn 越南人物画像生成管线的输入数据集。
关键统计指标
| 指标 | 数值 |
|---|---|
| PX-Web 矩阵总数 | 502 |
| 长格式数据单元格 | 316,108 |
| 一级 NSO 数据库数量 | 12 |
| 最早数据年份 | 1959 |
| 最晚数据年份 | 2024 |
| 通过 JSON REST API 获取的表 | 187 |
| 通过旧版 HTML 表单获取的表 | 307 |
数据配置与分片
数据集包含 14 个配置(config),每个配置对应一个 Parquet 文件:
| 配置名称 | 说明 | 表数量 | 单元格数量 |
|---|---|---|---|
catalog |
502 行矩阵索引(默认配置) | 502 | - |
cells |
316,108 行长格式合并数据 | 502 | 316,108 |
V06_agriculture |
农业(Nông, lâm nghiệp và thủy sản) | 70 | 76,541 |
V13_education |
教育(Giáo dục) | 34 | 57,742 |
V02_population_labour |
人口与劳动力(Dân số và lao động) | 63 | 48,203 |
V05_enterprises |
企业(Doanh nghiệp) | 56 | 37,391 |
V14_health_society |
健康与社会(Y tế, văn hóa và đời sống) | 97 | 23,934 |
V08_trade_prices_tourism |
贸易、价格与旅游(Thương mại, giá cả) | 72 | 23,213 |
V12_transport_postal |
运输与邮政(Vận tải và bưu điện) | 24 | 17,380 |
V15_international |
国际统计(Thống kê nước ngoài) | 10 | 11,502 |
V07_industry |
工业(Công nghiệp) | 9 | 5,532 |
V04_investment |
投资(Đầu tư) | 25 | 5,522 |
V01_geography |
行政单位、土地与气候(Đơn vị hành chính, đất đai và khí hậu) | 18 | 4,705 |
V03_national_accounts |
国民账户(Tài khoản quốc gia) | 24 | 4,443 |
数据结构
- catalog 配置:包含
table_id、database、config_id、title、source、variables、n_variables、n_cells、parquet_path等列。 - cells 配置:包含
table_id、database、dimensions(JSON 格式)、value等列。 - 单表 Parquet 文件(位于
tables/目录):保留 NSO 原始原生模式,例如V02_43.parquet包含Nghề nghiệp(职业)、Năm(年份)、value等列。
附加资源
配套文档
位于 docs/ 目录,共 7 篇:
DATAPROCESSING.md— 数据加工管线说明DATAANALYSIS.md— 数据分析详解DATAVISUALIZATION.md— 越南地图集DATAEXPLORATION.md— 目录 UMAP 探索DATASYNTHESIS.md— 人物画像生成器与 OCEAN 先验ONTOLOGY.md— 双语 NSO 本体树DATASETS.md— 人物画像数据集模式
交互式图表
位于 figures/ 目录,共 66 组(PNG + HTML 格式),涵盖:
- 分析图表(
figures/analysis/):39 个分析图形,覆盖 13 个 NSO 领域 - 可视化图表(
figures/visualization/):11 幅越南省级地图(choropleth) - 探索图表(
figures/exploration/):11 幅 UMAP 嵌入视图 - 合成图表(
figures/synthesis/):5 幅人物画像生成器视图
Jupyter 笔记本
位于 notebooks/ 目录,共 4 个已执行笔记本:
DATAANALYSIS.ipynbDATAVISUALIZATION.ipynbDATAEXPLORATION.ipynbDATASYNTHESIS.ipynb
引用信息
原始数据属于越南国家统计局(General Statistics Office of Vietnam)。使用数据集时需遵守源网站许可条款。建议同时引用 Hugging Face 版本和原始数据源。
搜集汇总
数据集介绍
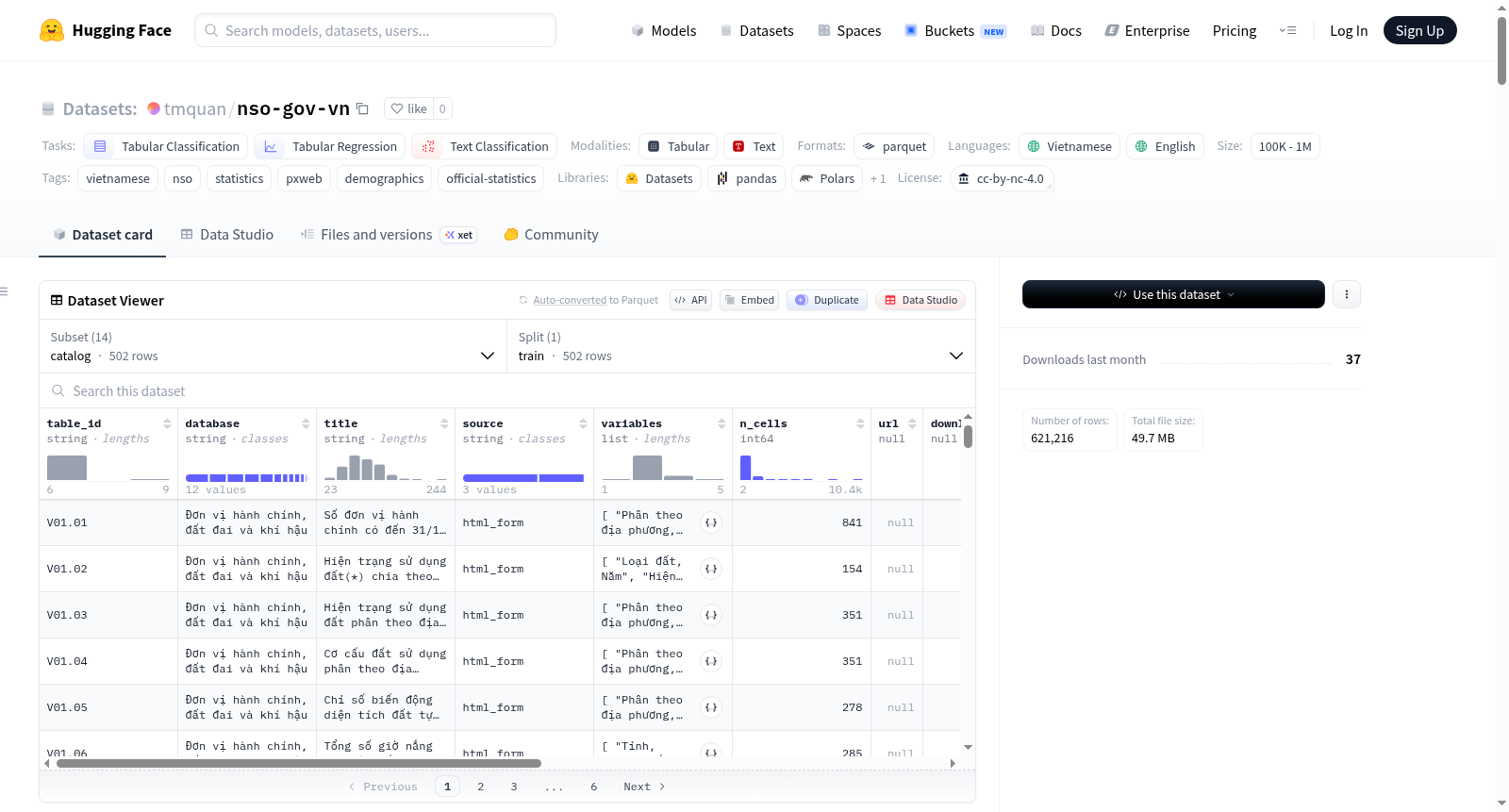
构建方式
该数据集构建于越南国家统计局PX-Web在线统计数据库的深度镜像与结构化重组织。研究者通过程序化爬虫,从API与遗留HTML表单两种通道逐一获取502个数据矩阵,随后将其解析并转换为高效的Parquet格式。为便于机器学习领域的直接应用,所有数据被重组为两种核心视图:一是包含31.6万条记录的长格式统一表,二是保留原生表格结构的二级数据库分区,覆蓋农业、教育、人口、企业、卫生等12个子领域。
特点
该数据集汇聚越南国家统计局的权威官方数据,时间跨度从1959年延伸至2024年,涵盖宏观经济、人口、产业、社会等多维度指标。其核心优势在于双轨兼容性:一方面提供统一的长格式视图便于跨表聚合分析,另一方面保留每个数据矩阵的原生列名与分类体系,兼顾大规模统计学习与细粒度领域探究的需求。同时,数据标签采用越南语为主、英语为辅的双语形式,扩展了国际适用性。
使用方法
数据集通过HuggingFace Datasets库实现便捷加载,默认配置可直接读取包含502个条目的元数据目录,用于表级检索与选择。调用特定数据库配置(如V06_agriculture)即可获取该领域内所有矩阵的统一长格式数据。若需保留原始指标列名,可经由huggingface_hub下载tables目录下的原生Parquet文件,再以Pandas进行细粒度读取。这种分层加载机制既满足快速原型验证,也支持深度的结构化分析任务。
背景与挑战
背景概述
nso-gov-vn数据集由TMQuan于2026年构建,旨在全面镜像越南统计总局(NSO/GSO)的PX-Web官方统计数据库。该数据集通过爬取https://pxweb.nso.gov.vn获取502个统计矩阵、超过31.6万个长格式数据单元,涵盖农业、教育、人口、企业、健康等12个核心领域,时间跨度从1959年至2024年。作为personas-vn越南人物生成流水线的核心输入,该数据集为自然语言处理、人口统计学建模及社会经济分析提供了高权威性的结构化官方统计数据,在越南语计算社会科学领域具有开创性影响力。
当前挑战
该数据集面临双重挑战:领域层面,越南官方统计数据长期以非结构化PX-Web格式分散存储,缺乏统一、机器可读的清洗版本,严重制约了机器学习模型在人口预测、政策模拟等任务中的应用;构建层面,需从307个遗留HTML表单和187个JSON REST API中异构抓取数据,并解决超30万单元的多语言标签对齐(越英双语)、跨年代统计口径变化及502个矩阵的归一化架构设计问题,确保数据语义完整性与下游兼容性。
常用场景
经典使用场景
作为越南官方统计数据的结构化镜像,nso-gov-vn数据集在社会科学与自然语言处理交叉领域开辟了独特的研究范式。其经典使用场景集中于利用502个PX-Web统计矩阵构建细粒度的社会经济画像:研究者可加载长格式的316K条元胞记录,通过多维度筛选(如地域、产业、教育层级)提取特定群体的时间序列特征,进而为人口建模、劳动力市场分析等任务提供权威数据基底。该数据集的拆分式配置允许用户按农业、教育、人口等12个主题子集直接获取原生架构表格,显著降低了官方统计数据的获取门槛。
实际应用
在实际应用中,该数据集已成为越南政策分析与商业智能的基础设施。地方政府利用其人口和劳动力子集进行区域发展规划,而企业智库则通过企业注册与投资表(V04、V05)评估行业增长潜力。媒体机构借助教育与社会健康数据(V13、V14)生成数据新闻可视化,例如人口密度热力图与经济产出气泡图的叠合分析。数据集配套的交互式Plotly图表使得非技术用户也能直接探索超50年的时序演变,从农业产出波动到旅游业复苏趋势的追踪均可低成本实现。
衍生相关工作
该数据集直接驱动了personas-vn越南合成人口生成管线的开发,该管道将官方统计矩与OCEAN人格先验概率结合,产出具有地域和教育属性约束的虚拟个体嵌入。在此基础上,衍生工作延伸出双语统计本体论框架(ONTOLOGY.md),实现了跨表变量的语义标准化标注。教学领域则涌现了数据科学案例库,如利用V02人口表的UMAP探勘分析作为计算社会科学课程作业。学术界更基于其时间序列结构,开发了针对缺失历史数据的多任务回归基准,推动统计数据库与深度学习模型的可控生成融合。
以上内容由遇见数据集搜集并总结生成


