open-wikipedia
收藏Hugging Face2026-04-06 更新2026-04-07 收录
下载链接:
https://huggingface.co/datasets/open-index/open-wikipedia
下载链接
链接失效反馈官方服务:
资源简介:
Open Wikipedia (Wikitext) 数据集包含了所有语言版本的维基百科文章,以原始的 MediaWiki wikitext 标记格式保存。数据集保留了所有原始标记元素,如模板、信息框、引用、表格等,未进行任何转换或简化。数据来源于 Wikimedia 的官方数据库转储,按语言组织,每个语言的完整文章以分片的 Apache Parquet 文件形式存储,并采用 Zstandard 压缩。数据集包含 139.4K 篇文章,涵盖 1 种语言(拉丁语),适用于文本生成、特征提取、文本分类、问答、摘要和翻译等多种 NLP 任务。数据集还提供了详细的字段说明,包括文章 ID、标题、wikitext 内容、URL、语言代码、长度和时间戳等。使用该数据集可以分析模板使用模式、提取结构化数据、研究编辑惯例以及训练支持标记的模型。数据集采用 CC BY-SA 4.0 许可协议。
The Open Wikipedia (Wikitext) Dataset contains Wikipedia articles from all language versions, preserved in their original MediaWiki wikitext markup format. The dataset retains all original markup elements, including templates, infoboxes, citations, tables, and more, without any conversion or simplification. The data is sourced from Wikimedia's official database dumps, organized by language. Full articles for each language are stored as sharded Apache Parquet files, compressed with Zstandard. The dataset comprises 139.4K articles covering 1 language (Latin), and is applicable to a variety of NLP tasks including text generation, feature extraction, text classification, question answering, summarization, and machine translation. The dataset also provides detailed field descriptions, including article ID, title, wikitext content, URL, language code, article length, and timestamp, among others. Using this dataset enables analysis of template usage patterns, extraction of structured data, research into editing conventions, and training of markup-aware models. The dataset is licensed under CC BY-SA 4.0.
创建时间:
2026-04-03
原始信息汇总
Open Wikipedia (Wikitext) 数据集概述
数据集基本信息
- 数据集名称: Open Wikipedia (Wikitext)
- 发布者: Open Index
- 发布日期: 2026-04-03
- 许可证: Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0)
- 数据来源: 官方 Wikimedia 数据库转储 (https://dumps.wikimedia.org/)
- 数据集地址: https://huggingface.co/datasets/open-index/open-wikipedia
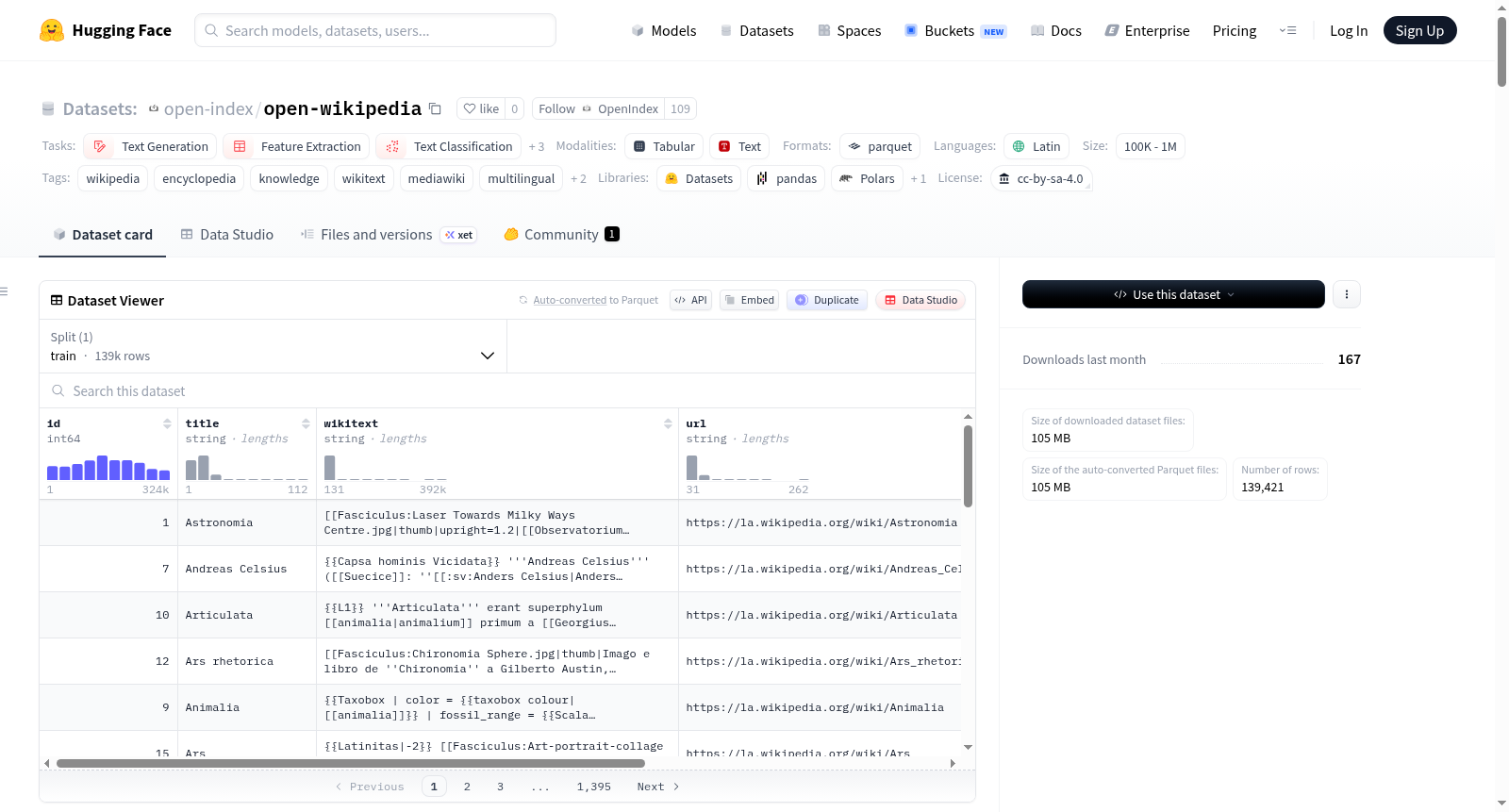
数据集内容与规模
- 内容描述: 该数据集包含所有语言版本的维基百科文章,以原始的 MediaWiki wikitext 源标记形式提供。所有模板、信息框、参考文献、表格、分类、文件链接和其他 MediaWiki 结构均被完整保留。
- 数据规模: 包含 139.4K 篇文章,涵盖 1 种语言。
- 语言: 拉丁语 (语言代码:
la)
数据结构与格式
- 数据格式: Apache Parquet 文件,采用 Zstandard 压缩。
- 文件组织: 按语言目录组织,每种语言包含分片的 Parquet 文件。
- 数据分割: 仅包含训练集 (
train),共 139,421 个样本。
数据模式 (Schema)
每个 Parquet 文件共享相同的结构:
| 列名 | 数据类型 | 描述 |
|---|---|---|
id |
int64 |
维基百科页面 ID,在每种语言版本中唯一 |
title |
string |
文章标题,与维基百科上显示的一致 |
wikitext |
string |
以原始 MediaWiki wikitext 标记格式呈现的完整文章正文 |
url |
string |
指向维基百科文章的直接 URL |
lang |
string |
ISO 639 语言代码 (例如 en, de, fr, ja) |
length |
int32 |
Wikitext 正文的字节长度 |
timestamp |
string |
最后修订时间戳 (ISO 8601 格式) |
数据处理流程
- 下载: 从 https://dumps.wikimedia.org/ 流式下载最新的
{lang}wiki-latest-pages-articles.xml.bz2转储文件。 - 解析: 使用流式 XML 解析器处理 bzip2 压缩的转储文件,仅保留命名空间-0 的页面(文章)。
- 过滤: 排除纯文本等效内容短于 100 字节的文章(移除存根、消歧页面等)。
- 分片: 文章被写入 Zstandard 压缩的 Parquet 文件,每个分片大约包含 500,000 行。
- 发布: 每种语言的分片在处理完成后提交至 Hugging Face 仓库。
预期用途与优势
- 构建或评估 wikitext 解析器: 为开发 MediaWiki 解析器或转换器提供跨多种语言的大量真实测试用例。
- 分析模板使用模式: 保留信息框、引用模板和导航模板中编码的结构化知识。
- 从信息框中提取结构化数据: 解析信息框模板中的键值对以构建结构化知识库。
- 研究编辑规范: 原始标记揭示了不同语言社区组织和格式化文章的方式。
- 训练支持标记的模型: 在 wikitext 上训练的语言模型可以学习生成或补全 MediaWiki 标记,这对编辑工具和机器人很有用。
已知限制
- 这是原始页面源代码,而非渲染后的 HTML: 模板未展开,解析器函数未求值,Lua 模块未执行。
- 单一时间点快照: 数据集代表每种语言转储的单一快照,不包含编辑历史或文章修订。
- 转储可用性各异: 并非所有语言版本都始终提供其转储文件。
- 部分文章体积非常大: 少数文章(列表、时间线、参考页面)的 wikitext 正文可能超过 1 MB。
相关数据集
- Open Wikipedia (Markdown): https://huggingface.co/datasets/open-index/open-wikipedia-markdown - 相同文章转换为干净的 Markdown 格式。
- Open Wikipedia (Text): https://huggingface.co/datasets/open-index/open-wikipedia-text - 相同文章以纯文本形式提供,所有格式和标记均已移除。
引用方式
bibtex @dataset{open_wikipedia, title = {Open Wikipedia (Wikitext)}, author = {Open Index}, year = {2026}, url = {https://huggingface.co/datasets/open-index/open-wikipedia}, license = {CC BY-SA 4.0}, publisher = {Hugging Face} }
搜集汇总
数据集介绍
构建方式
在数字人文与自然语言处理领域,大规模高质量语料库的构建是推动研究进展的基石。Open Wikipedia (Wikitext)数据集源于维基媒体基金会官方发布的数据库快照,其构建过程遵循严谨的数据工程流程。首先,系统从dumps.wikimedia.org流式下载各语言维基百科最新的XML文章压缩包。随后,通过流式XML解析器仅提取命名空间为0的条目文章,自动过滤重定向页、讨论页等非内容页面。为保障数据质量,算法会排除纯文本等效长度小于100字节的存根文章。最终,所有合格文章以其原始的MediaWiki维基文本标记格式,被分片写入采用Zstandard压缩的Apache Parquet文件中,并按语言目录进行组织,完整保留了模板、信息框、参考文献等全部结构化标记元素。
特点
该数据集的核心特征在于其无与伦比的原始性与完整性。作为维基百科文章的源数据存储,它完整囊括了MediaWiki标记语言的所有语法结构,包括信息框模板、内部链接、分类标签、引用注释乃至Lua模块调用等复杂元素。这种对原始标记的忠实保留,使得数据集超越了常规纯文本语料库的范畴,转化为一个蕴含丰富结构化知识的语义网络。其多语言架构覆盖了包括拉丁语在内的百余种语言版本,每种语言的数据均通过统一模式进行组织,确保了跨语言分析的一致性。数据集采用高效的列式存储格式,支持直接查询与流式加载,为大规模标记文本分析提供了理想的基础设施。
使用方法
针对该数据集的应用,研究者可采用多种灵活的技术路径进行访问与分析。最便捷的方式是直接通过Hugging Face的`datasets`库加载特定语言子集,并利用流式读取功能处理海量数据而无需完全下载。对于需要执行复杂聚合查询的任务,推荐使用DuckDB通过SQL语句直接远程读取Parquet文件,例如统计各语言文章数量或分析特定模板的使用模式。此外,用户亦可借助`huggingface_hub`工具库或命令行接口,有选择地下载特定语言的数据分片。在具体研究场景中,该数据集特别适用于训练能够理解和生成维基标记的语言模型、深度解析模板以构建知识图谱,或进行跨语言编辑规范与标记模式的比较研究。
背景与挑战
背景概述
Open Wikipedia (Wikitext) 数据集由 Open Index 机构于2026年发布,旨在为自然语言处理与知识计算领域提供原始、未处理的维基百科文章源数据。该数据集的核心研究问题在于如何完整保留维基百科文章的原生 MediaWiki 标记语言(wikitext),包括模板、信息框、参考文献等所有结构化元素,从而支持对维基百科知识体系的深度解析与建模。其影响力体现在为构建或评估维基文本解析器、分析模板使用模式、以及训练能够理解复杂标记结构的语言模型提供了关键资源,推动了知识表示与多语言文本处理研究的发展。
当前挑战
该数据集旨在解决从维基百科原始标记中提取结构化知识的领域挑战,其核心问题在于如何有效解析和处理高度异构的 MediaWiki 语法,包括嵌套模板、解析函数和 Lua 模块调用,这些元素使得自动化信息抽取任务变得异常复杂。在构建过程中,数据集面临多重技术挑战:需要设计流式处理管道以高效解析庞大的多语言 XML 转储文件,同时确保在过滤短文章和分片存储时保持数据的完整性与一致性;此外,原始标记的非标准化特性以及不同语言版本间编辑规范的差异,也为数据的统一处理与质量评估带来了显著困难。
常用场景
经典使用场景
在自然语言处理领域,原始维基文本数据集常被用于训练和评估语言模型,特别是那些需要理解或生成结构化标记的模型。由于该数据集完整保留了MediaWiki原始标记,包括模板、信息框和引用等复杂结构,它成为研究模型处理富文本格式能力的理想基准。研究人员利用这些数据来探索模型在解析维基标记语法、识别模板参数以及生成符合维基编辑规范的内容方面的表现,从而推动标记感知型语言模型的发展。
衍生相关工作
围绕该数据集衍生了一系列经典研究工作。在模型训练方面,出现了专门针对维基标记预训练的语言模型,如WikiBERT,这些模型在文章自动摘要和分类任务中表现出色。在知识提取领域,研究者开发了如InfoboxExtractor的工具,能够高效解析信息框模板以填充知识库。此外,跨语言分析研究利用该数据集比较模板使用差异,揭示了文化偏好对知识组织方式的影响,推动了多语言数字人文研究的发展。
数据集最近研究
最新研究方向
在自然语言处理领域,维基百科原始标记数据集正成为结构化知识提取与多模态模型训练的关键资源。前沿研究聚焦于利用其完整的MediaWiki语法,开发能够解析复杂模板与引用结构的深度学习模型,以增强模型对百科全书式知识的理解与生成能力。近期热点事件如大规模语言模型对事实性知识的渴求,推动了基于原始维基文本的检索增强生成技术发展,使模型能更精准地调用内部链接、信息框等结构化元素。该数据集在提升模型可解释性、支持多语言知识图谱构建方面具有深远影响,为人工智能系统注入更可靠、可追溯的知识源泉。
以上内容由遇见数据集搜集并总结生成


